 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Geometric Constraints on Dense Trajectories for Motion Saliency
Paper and Code
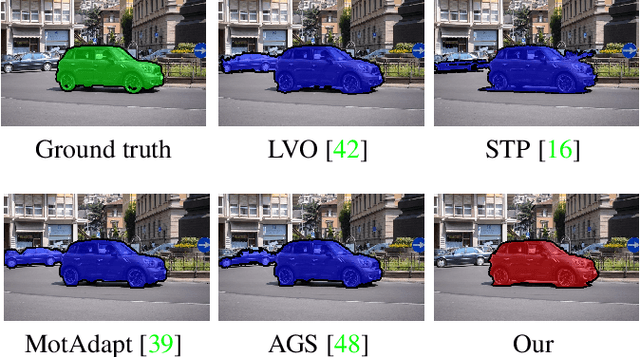

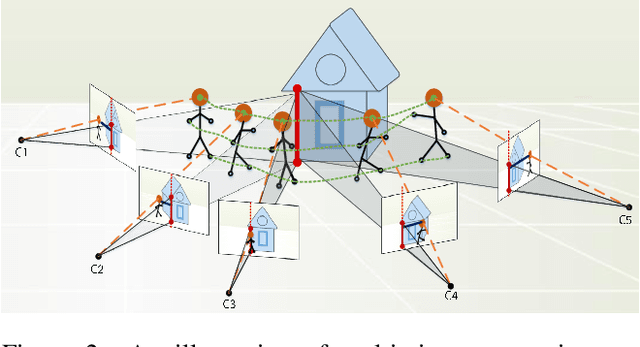
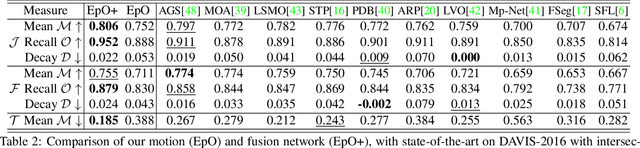
The existing approaches for salient motion segmentation are unable to explicitly learn geometric cues and often give false detections on prominent static objects. We exploit multiview geometric constraints to avoid such mistakes. To handle nonrigid background like sea, we also propose a robust fusion mechanism between motion and appearance-based features. We find dense trajectories, covering every pixel in the video, and propose trajectory-based epipolar distances to distinguish between background and foreground regions. Trajectory epipolar distances are data-independent and can be readily computed given a few features' correspondences in the images. We show that by combining epipolar distances with optical flow, a powerful motion network can be learned. Enabling the network to leverage both of these information, we propose a simple mechanism, we call input-dropout. We outperform the previous motion network on DAVIS-2016 dataset by 5.2% in mean IoU score. By robustly fusing our motion network with an appearance network using the proposed input-dropout, we also outperform the previous methods on DAVIS-2016, 2017 and Segtrackv2 dataset.