 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from a Generative Oracle: Domain Adaptation for Restoration
Dec 11, 2025Pre-trained image restoration models often fail on real-world, out-of-distribution degradations due to significant domain gaps. Adapting to these unseen domains is challenging, as out-of-distribution data lacks ground truth, and traditional adaptation methods often require complex architectural changes. We propose LEGO (Learning from a Generative Oracle), a practical three-stage framework for post-training domain adaptation without paired data. LEGO converts this unsupervised challenge into a tractable pseudo-supervised one. First, we obtain initial restorations from the pre-trained model. Second, we leverage a frozen, large-scale generative oracle to refine these estimates into high-quality pseudo-ground-truths. Third, we fine-tune the original model using a mixed-supervision strategy combining in-distribution data with these new pseudo-pairs. This approach adapts the model to the new distribution without sacrificing its original robustness or requiring architectural modifications. Experiments demonstrate that LEGO effectively bridges the domain gap, significantly improving performance on diverse real-world benchmarks.
Reference-Guided Identity Preserving Face Restoration
May 28, 2025Preserving face identity is a critical yet persistent challenge in diffusion-based image restoration. While reference faces offer a path forward, existing reference-based methods often fail to fully exploit their potential. This paper introduces a novel approach that maximizes reference face utility for improved face restoration and identity preservation. Our method makes three key contributions: 1) Composite Context, a comprehensive representation that fuses multi-level (high- and low-level) information from the reference face, offering richer guidance than prior singular representations. 2) Hard Example Identity Loss, a novel loss function that leverages the reference face to address the identity learning inefficiencies found in the existing identity loss. 3) A training-free method to adapt the model to multi-reference inputs during inference. The proposed method demonstrably restores high-quality faces and achieves state-of-the-art identity preserving restoration on benchmarks such as FFHQ-Ref and CelebA-Ref-Test, consistently outperforming previous work.
The Power of Context: How Multimodality Improves Image Super-Resolution
Mar 18, 2025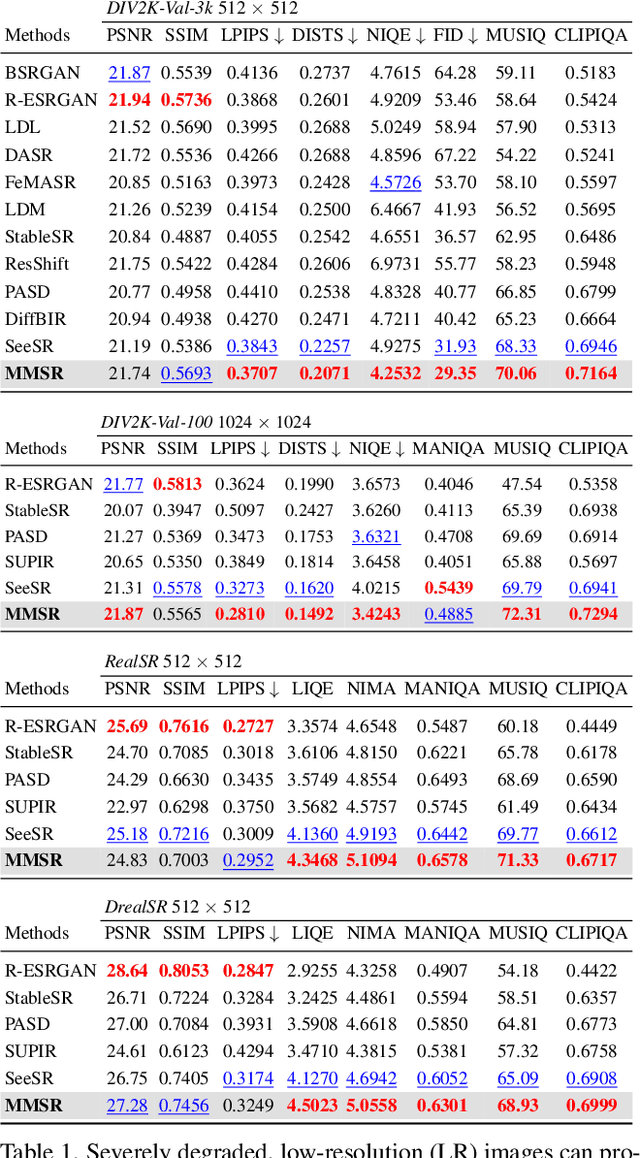
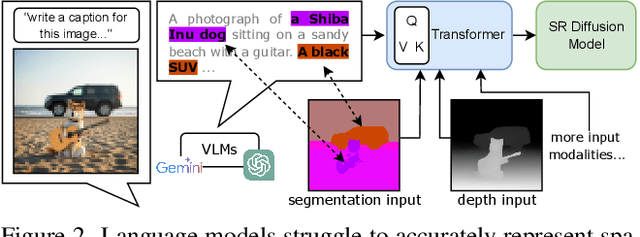
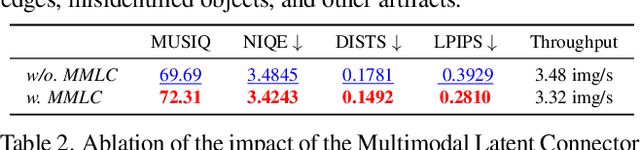
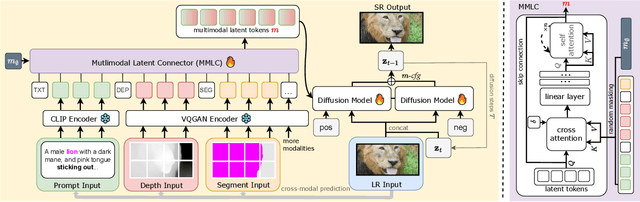
Single-image super-resolution (SISR) remains challenging due to the inherent difficulty of recovering fine-grained details and preserving perceptual quality from low-resolution inputs. Existing methods often rely on limited image priors, leading to suboptimal results. We propose a novel approach that leverages the rich contextual information available in multiple modalities -- including depth, segmentation, edges, and text prompts -- to learn a powerful generative prior for SISR within a diffusion model framework. We introduce a flexible network architecture that effectively fuses multimodal information, accommodating an arbitrary number of input modalities without requiring significant modifications to the diffusion process. Crucially, we mitigate hallucinations, often introduced by text prompts, by using spatial information from other modalities to guide regional text-based conditioning. Each modality's guidance strength can also be controlled independently, allowing steering outputs toward different directions, such as increasing bokeh through depth or adjusting object prominence via segmentation. Extensive experiments demonstrate that our model surpasses state-of-the-art generative SISR methods, achieving superior visual quality and fidelity. See project page at https://mmsr.kfmei.com/.
Bigger is not Always Better: Scaling Properties of Latent Diffusion Models
Apr 01, 2024We study the scaling properties of latent diffusion models (LDMs) with an emphasis on their sampling efficiency. While improved network architecture and inference algorithms have shown to effectively boost sampling efficiency of diffusion models, the role of model size -- a critical determinant of sampling efficiency -- has not been thoroughly examined. Through empirical analysis of established text-to-image diffusion models, we conduct an in-depth investigation into how model size influences sampling efficiency across varying sampling steps. Our findings unveil a surprising trend: when operating under a given inference budget, smaller models frequently outperform their larger equivalents in generating high-quality results. Moreover, we extend our study to demonstrate the generalizability of the these findings by applying various diffusion samplers, exploring diverse downstream tasks, evaluating post-distilled models, as well as comparing performance relative to training compute. These findings open up new pathways for the development of LDM scaling strategies which can be employed to enhance generative capabilities within limited inference budgets.
Latent Feature-Guided Diffusion Models for Shadow Removal
Dec 04, 2023



Recovering textures under shadows has remained a challenging problem due to the difficulty of inferring shadow-free scenes from shadow images. In this paper, we propose the use of diffusion models as they offer a promising approach to gradually refine the details of shadow regions during the diffusion process. Our method improves this process by conditioning on a learned latent feature space that inherits the characteristics of shadow-free images, thus avoiding the limitation of conventional methods that condition on degraded images only. Additionally, we propose to alleviate potential local optima during training by fusing noise features with the diffusion network. We demonstrate the effectiveness of our approach which outperforms the previous best method by 13% in terms of RMSE on the AISTD dataset. Further, we explore instance-level shadow removal, where our model outperforms the previous best method by 82% in terms of RMSE on the DESOBA dataset.
Conditional Diffusion Distillation
Oct 02, 2023

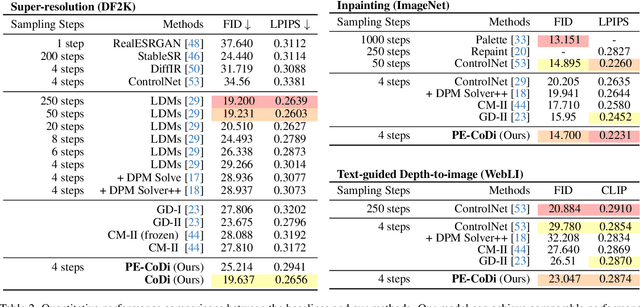
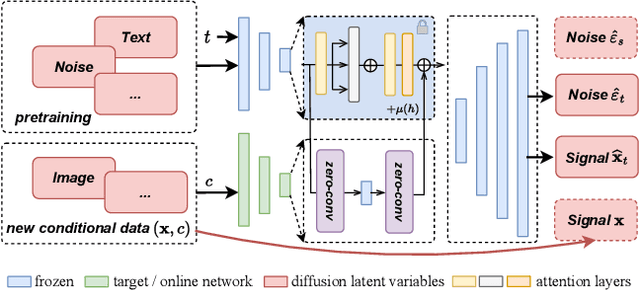
Generative diffusion models provide strong priors for text-to-image generation and thereby serve as a foundation for conditional generation tasks such as image editing, restoration, and super-resolution. However, one major limitation of diffusion models is their slow sampling time. To address this challenge, we present a novel conditional distillation method designed to supplement the diffusion priors with the help of image conditions, allowing for conditional sampling with very few steps. We directly distill the unconditional pre-training in a single stage through joint-learning, largely simplifying the previous two-stage procedures that involve both distillation and conditional finetuning separately. Furthermore, our method enables a new parameter-efficient distillation mechanism that distills each task with only a small number of additional parameters combined with the shared frozen unconditional backbone. Experiments across multiple tasks including super-resolution, image editing, and depth-to-image generation demonstrate that our method outperforms existing distillation techniques for the same sampling time. Notably, our method is the first distillation strategy that can match the performance of the much slower fine-tuned conditional diffusion models.
T1: Scaling Diffusion Probabilistic Fields to High-Resolution on Unified Visual Modalities
May 24, 2023Diffusion Probabilistic Field (DPF) models the distribution of continuous functions defined over metric spaces. While DPF shows great potential for unifying data generation of various modalities including images, videos, and 3D geometry, it does not scale to a higher data resolution. This can be attributed to the ``scaling property'', where it is difficult for the model to capture local structures through uniform sampling. To this end, we propose a new model comprising of a view-wise sampling algorithm to focus on local structure learning, and incorporating additional guidance, e.g., text description, to complement the global geometry. The model can be scaled to generate high-resolution data while unifying multiple modalities. Experimental results on data generation in various modalities demonstrate the effectiveness of our model, as well as its potential as a foundation framework for scalable modality-unified visual content generation.
Bi-Noising Diffusion: Towards Conditional Diffusion Models with Generative Restoration Priors
Dec 14, 2022



Conditional diffusion probabilistic models can model the distribution of natural images and can generate diverse and realistic samples based on given conditions. However, oftentimes their results can be unrealistic with observable color shifts and textures. We believe that this issue results from the divergence between the probabilistic distribution learned by the model and the distribution of natural images. The delicate conditions gradually enlarge the divergence during each sampling timestep. To address this issue, we introduce a new method that brings the predicted samples to the training data manifold using a pretrained unconditional diffusion model. The unconditional model acts as a regularizer and reduces the divergence introduced by the conditional model at each sampling step. We perform comprehensive experiments to demonstrate the effectiveness of our approach on super-resolution, colorization, turbulence removal, and image-deraining tasks. The improvements obtained by our method suggest that the priors can be incorporated as a general plugin for improving conditional diffusion models.
VIDM: Video Implicit Diffusion Models
Dec 01, 2022



Diffusion models have emerged as a powerful generative method for synthesizing high-quality and diverse set of images. In this paper, we propose a video generation method based on diffusion models, where the effects of motion are modeled in an implicit condition manner, i.e. one can sample plausible video motions according to the latent feature of frames. We improve the quality of the generated videos by proposing multiple strategies such as sampling space truncation, robustness penalty, and positional group normalization. Various experiments are conducted on datasets consisting of videos with different resolutions and different number of frames. Results show that the proposed method outperforms the state-of-the-art generative adversarial network-based methods by a significant margin in terms of FVD scores as well as perceptible visual quality.
AT-DDPM: Restoring Faces degraded by Atmospheric Turbulence using Denoising Diffusion Probabilistic Models
Aug 24, 2022
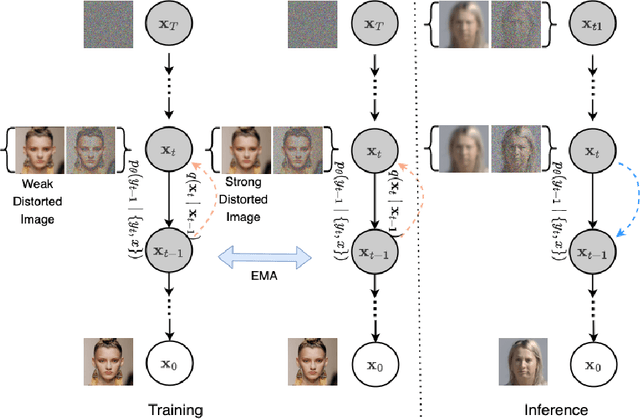


Although many long-range imaging systems are designed to support extended vision applications, a natural obstacle to their operation is degradation due to atmospheric turbulence. Atmospheric turbulence causes significant degradation to image quality by introducing blur and geometric distortion. In recent years, various deep learning-based single image atmospheric turbulence mitigation methods, including CNN-based and GAN inversion-based, have been proposed in the literature which attempt to remove the distortion in the image. However, some of these methods are difficult to train and often fail to reconstruct facial features and produce unrealistic results especially in the case of high turbulence. Denoising Diffusion Probabilistic Models (DDPMs) have recently gained some traction because of their stable training process and their ability to generate high quality images. In this paper, we propose the first DDPM-based solution for the problem of atmospheric turbulence mitigation. We also propose a fast sampling technique for reducing the inference times for conditional DDPMs. Extensive experiments are conducted on synthetic and real-world data to show the significance of our model. To facilitate further research, all codes and pretrained models will be made public after the review process.