 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressive Sensing with Tensorized Autoencoder
Paper and Code
Mar 10, 2023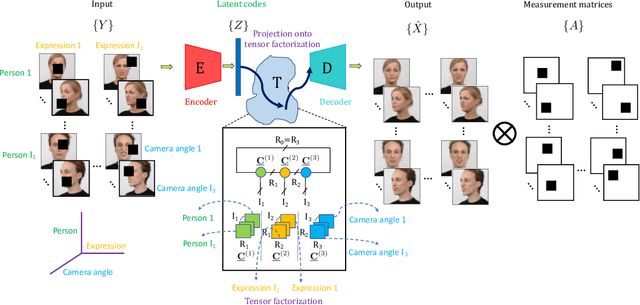
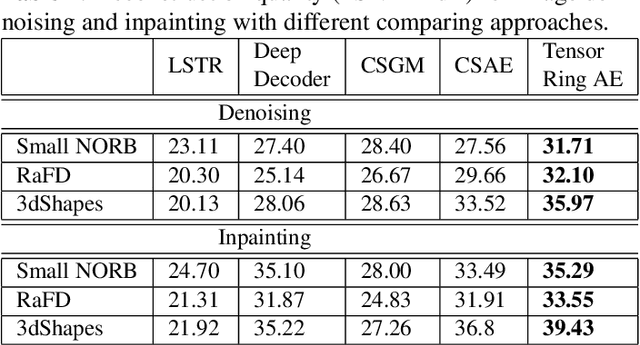
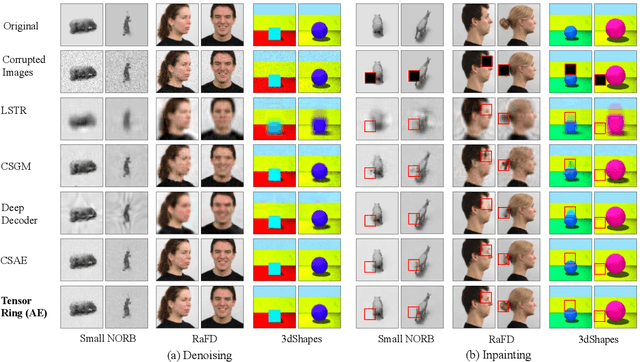
Deep networks can be trained to map images into a low-dimensional latent space. In many cases, different images in a collection are articulated versions of one another; for example, same object with different lighting, background, or pose. Furthermore, in many cases, parts of images can be corrupted by noise or missing entries. In this paper, our goal is to recover images without access to the ground-truth (clean) images using the articulations as structural prior of the data. Such recovery problems fall under the domain of compressive sensing. We propose to learn autoencoder with tensor ring factorization on the the embedding space to impose structural constraints on the data. In particular, we use a tensor ring structure in the bottleneck layer of the autoencoder that utilizes the soft labels of the structured dataset. We empirically demonstrate the effectiveness of the proposed approach for inpainting and denoising applications. The resulting method achieves better reconstruction quality compared to other generative prior-based self-supervised recovery approaches for compressive sensing.