 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Adversarial Video Synthesis with Learned Priors
Paper and Code

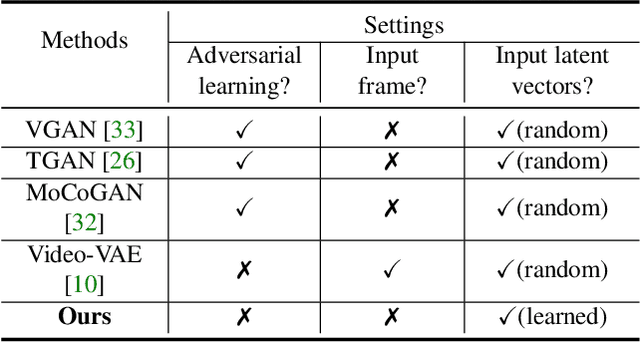
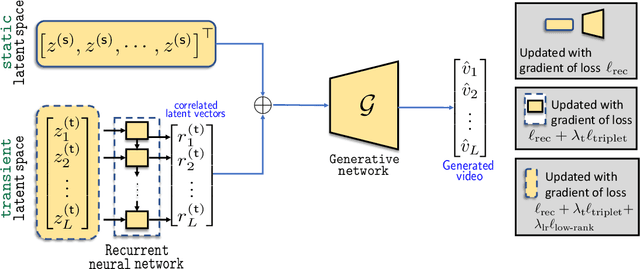

Most of the existing works in video synthesis focus on generating videos using adversarial learning. Despite their success, these methods often require input reference frame or fail to generate diverse videos from the given data distribution, with little to no uniformity in the quality of videos that can be generated. Different from these methods, we focus on the problem of generating videos from latent noise vectors, without any reference input frames. To this end, we develop a novel approach that jointly optimizes the input latent space, the weights of a recurrent neural network and a generator through non-adversarial learning. Optimizing for the input latent space along with the network weights allows us to generate videos in a controlled environment, i.e., we can faithfully generate all videos the model has seen during the learning process as well as new unseen videos. Extensive experiments on three challenging and diverse datasets well demonstrate that our approach generates superior quality videos compared to the existing state-of-the-art methods.