 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Mesh Transformers with Topology-Guided Pretraining for Morphometric Analysis of Brain Structures
Apr 06, 2026Representation learning on large-scale unstructured volumetric and surface meshes poses significant challenges in neuroimaging, especially when models must incorporate diverse vertex-level morphometric descriptors, such as cortical thickness, curvature, sulcal depth, and myelin content, which carry subtle disease-related signals. Current approaches either ignore these clinically informative features or support only a single mesh topology, restricting their use across imaging pipelines. We introduce a hierarchical transformer framework designed for heterogeneous mesh analysis that operates on spatially adaptive tree partitions constructed from simplicial complexes of arbitrary order. This design accommodates both volumetric and surface discretizations within a single architecture, enabling efficient multi-scale attention without topology-specific modifications. A feature projection module maps variable-length per-vertex clinical descriptors into the spatial hierarchy, separating geometric structure from feature dimensionality and allowing seamless integration of different neuroimaging feature sets. Self-supervised pretraining via masked reconstruction of both coordinates and morphometric channels on large unlabeled cohorts yields a transferable encoder backbone applicable to diverse downstream tasks and mesh modalities. We validate our approach on Alzheimer's disease classification and amyloid burden prediction using volumetric brain meshes from ADNI, as well as focal cortical dysplasia detection on cortical surface meshes from the MELD dataset, achieving state-of-the-art results across all benchmarks.
Enhancing Alzheimer's Diagnosis: Leveraging Anatomical Landmarks in Graph Convolutional Neural Networks on Tetrahedral Meshes
Mar 06, 2025Alzheimer's disease (AD) is a major neurodegenerative condition that affects millions around the world. As one of the main biomarkers in the AD diagnosis procedure, brain amyloid positivity is typically identified by positron emission tomography (PET), which is costly and invasive. Brain structural magnetic resonance imaging (sMRI) may provide a safer and more convenient solution for the AD diagnosis. Recent advances in geometric deep learning have facilitated sMRI analysis and early diagnosis of AD. However, determining AD pathology, such as brain amyloid deposition, in preclinical stage remains challenging, as less significant morphological changes can be observed. As a result, few AD classification models are generalizable to the brain amyloid positivity classification task. Blood-based biomarkers (BBBMs), on the other hand, have recently achieved remarkable success in predicting brain amyloid positivity and identifying individuals with high risk of being brain amyloid positive. However, individuals in medium risk group still require gold standard tests such as Amyloid PET for further evaluation. Inspired by the recent success of transformer architectures, we propose a geometric deep learning model based on transformer that is both scalable and robust to variations in input volumetric mesh size. Our work introduced a novel tokenization scheme for tetrahedral meshes, incorporating anatomical landmarks generated by a pre-trained Gaussian process model. Our model achieved superior classification performance in AD classification task. In addition, we showed that the model was also generalizable to the brain amyloid positivity prediction with individuals in the medium risk class, where BM alone cannot achieve a clear classification. Our work may enrich geometric deep learning research and improve AD diagnosis accuracy without using expensive and invasive PET scans.
A Recipe for Geometry-Aware 3D Mesh Transformers
Oct 31, 2024



Utilizing patch-based transformers for unstructured geometric data such as polygon meshes presents significant challenges, primarily due to the absence of a canonical ordering and variations in input sizes. Prior approaches to handling 3D meshes and point clouds have either relied on computationally intensive node-level tokens for large objects or resorted to resampling to standardize patch size. Moreover, these methods generally lack a geometry-aware, stable Structural Embedding (SE), often depending on simplistic absolute SEs such as 3D coordinates, which compromise isometry invariance essential for tasks like semantic segmentation. In our study, we meticulously examine the various components of a geometry-aware 3D mesh transformer, from tokenization to structural encoding, assessing the contribution of each. Initially, we introduce a spectral-preserving tokenization rooted in algebraic multigrid methods. Subsequently, we detail an approach for embedding features at the patch level, accommodating patches with variable node counts. Through comparative analyses against a baseline model employing simple point-wise Multi-Layer Perceptrons (MLP), our research highlights critical insights: 1) the importance of structural and positional embeddings facilitated by heat diffusion in general 3D mesh transformers; 2) the effectiveness of novel components such as geodesic masking and feature interaction via cross-attention in enhancing learning; and 3) the superior performance and efficiency of our proposed methods in challenging segmentation and classification tasks.
AMG: Avatar Motion Guided Video Generation
Sep 02, 2024



Human video generation task has gained significant attention with the advancement of deep generative models. Generating realistic videos with human movements is challenging in nature, due to the intricacies of human body topology and sensitivity to visual artifacts. The extensively studied 2D media generation methods take advantage of massive human media datasets, but struggle with 3D-aware control; whereas 3D avatar-based approaches, while offering more freedom in control, lack photorealism and cannot be harmonized seamlessly with background scene. We propose AMG, a method that combines the 2D photorealism and 3D controllability by conditioning video diffusion models on controlled rendering of 3D avatars. We additionally introduce a novel data processing pipeline that reconstructs and renders human avatar movements from dynamic camera videos. AMG is the first method that enables multi-person diffusion video generation with precise control over camera positions, human motions, and background style. We also demonstrate through extensive evaluation that it outperforms existing human video generation methods conditioned on pose sequences or driving videos in terms of realism and adaptability.
SelfReg-UNet: Self-Regularized UNet for Medical Image Segmentation
Jun 21, 2024Since its introduction, UNet has been leading a variety of medical image segmentation tasks. Although numerous follow-up studies have also been dedicated to improving the performance of standard UNet, few have conducted in-depth analyses of the underlying interest pattern of UNet in medical image segmentation. In this paper, we explore the patterns learned in a UNet and observe two important factors that potentially affect its performance: (i) irrelative feature learned caused by asymmetric supervision; (ii) feature redundancy in the feature map. To this end, we propose to balance the supervision between encoder and decoder and reduce the redundant information in the UNet. Specifically, we use the feature map that contains the most semantic information (i.e., the last layer of the decoder) to provide additional supervision to other blocks to provide additional supervision and reduce feature redundancy by leveraging feature distillation. The proposed method can be easily integrated into existing UNet architecture in a plug-and-play fashion with negligible computational cost. The experimental results suggest that the proposed method consistently improves the performance of standard UNets on four medical image segmentation datasets. The code is available at \url{https://github.com/ChongQingNoSubway/SelfReg-UNet}
TetCNN: Convolutional Neural Networks on Tetrahedral Meshes
Feb 14, 2023



Convolutional neural networks (CNN) have been broadly studied on images, videos, graphs, and triangular meshes. However, it has seldom been studied on tetrahedral meshes. Given the merits of using volumetric meshes in applications like brain image analysis, we introduce a novel interpretable graph CNN framework for the tetrahedral mesh structure. Inspired by ChebyNet, our model exploits the volumetric Laplace-Beltrami Operator (LBO) to define filters over commonly used graph Laplacian which lacks the Riemannian metric information of 3D manifolds. For pooling adaptation, we introduce new objective functions for localized minimum cuts in the Graclus algorithm based on the LBO. We employ a piece-wise constant approximation scheme that uses the clustering assignment matrix to estimate the LBO on sampled meshes after each pooling. Finally, adapting the Gradient-weighted Class Activation Mapping algorithm for tetrahedral meshes, we use the obtained heatmaps to visualize discovered regions-of-interest as biomarkers. We demonstrate the effectiveness of our model on cortical tetrahedral meshes from patients with Alzheimer's disease, as there is scientific evidence showing the correlation of cortical thickness to neurodegenerative disease progression. Our results show the superiority of our LBO-based convolution layer and adapted pooling over the conventionally used unitary cortical thickness, graph Laplacian, and point cloud representation.
OTRE: Where Optimal Transport Guided Unpaired Image-to-Image Translation Meets Regularization by Enhancing
Feb 09, 2023



Non-mydriatic retinal color fundus photography (CFP) is widely available due to the advantage of not requiring pupillary dilation, however, is prone to poor quality due to operators, systemic imperfections, or patient-related causes. Optimal retinal image quality is mandated for accurate medical diagnoses and automated analyses. Herein, we leveraged the Optimal Transport (OT) theory to propose an unpaired image-to-image translation scheme for mapping low-quality retinal CFPs to high-quality counterparts. Furthermore, to improve the flexibility, robustness, and applicability of our image enhancement pipeline in the clinical practice, we generalized a state-of-the-art model-based image reconstruction method, regularization by denoising, by plugging in priors learned by our OT-guided image-to-image translation network. We named it as regularization by enhancing (RE). We validated the integrated framework, OTRE, on three publicly available retinal image datasets by assessing the quality after enhancement and their performance on various downstream tasks, including diabetic retinopathy grading, vessel segmentation, and diabetic lesion segmentation. The experimental results demonstrated the superiority of our proposed framework over some state-of-the-art unsupervised competitors and a state-of-the-art supervised method.
Optimal Transport Guided Unsupervised Learning for Enhancing low-quality Retinal Images
Feb 06, 2023



Real-world non-mydriatic retinal fundus photography is prone to artifacts, imperfections and low-quality when certain ocular or systemic co-morbidities exist. Artifacts may result in inaccuracy or ambiguity in clinical diagnoses. In this paper, we proposed a simple but effective end-to-end framework for enhancing poor-quality retinal fundus images. Leveraging the optimal transport theory, we proposed an unpaired image-to-image translation scheme for transporting low-quality images to their high-quality counterparts. We theoretically proved that a Generative Adversarial Networks (GAN) model with a generator and discriminator is sufficient for this task. Furthermore, to mitigate the inconsistency of information between the low-quality images and their enhancements, an information consistency mechanism was proposed to maximally maintain structural consistency (optical discs, blood vessels, lesions) between the source and enhanced domains. Extensive experiments were conducted on the EyeQ dataset to demonstrate the superiority of our proposed method perceptually and quantitatively.
Anisotropic Multi-Scale Graph Convolutional Network for Dense Shape Correspondence
Oct 17, 2022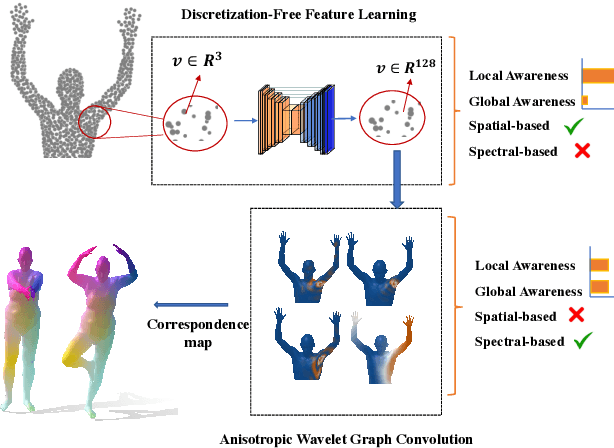
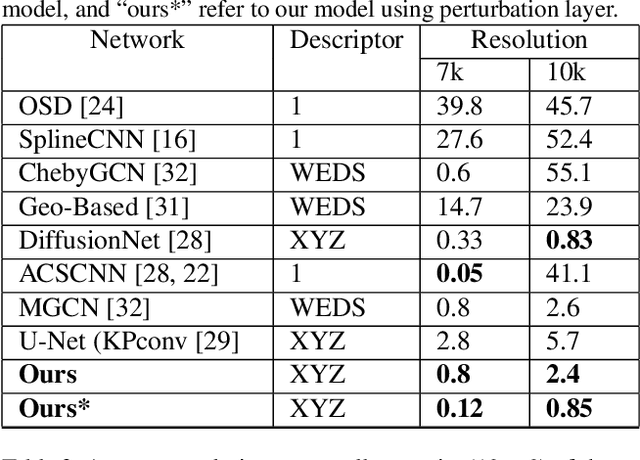
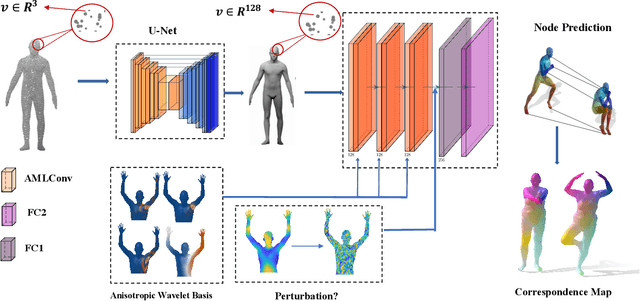
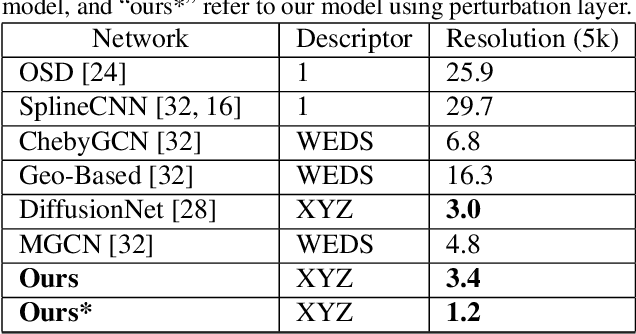
This paper studies 3D dense shape correspondence, a key shape analysis application in computer vision and graphics. We introduce a novel hybrid geometric deep learning-based model that learns geometrically meaningful and discretization-independent features with a U-Net model as the primary node feature extraction module, followed by a successive spectral-based graph convolutional network. To create a diverse set of filters, we use anisotropic wavelet basis filters, being sensitive to both different directions and band-passes. This filter set overcomes the over-smoothing behavior of conventional graph neural networks. To further improve the model's performance, we add a function that perturbs the feature maps in the last layer ahead of fully connected layers, forcing the network to learn more discriminative features overall. The resulting correspondence maps show state-of-the-art performance on the benchmark datasets based on average geodesic errors and superior robustness to discretization in 3D meshes. Our approach provides new insights and practical solutions to the dense shape correspondence research.