 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential Privacy Under Class Imbalance: Methods and Empirical Insights
Paper and Code
Nov 08, 2024
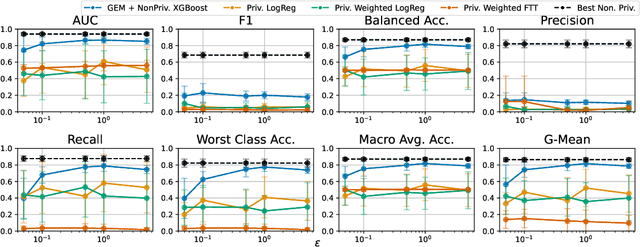
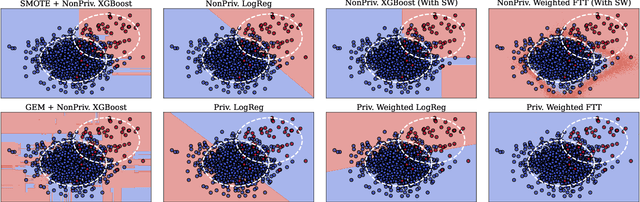
Imbalanced learning occurs in classification settings where the distribution of class-labels is highly skewed in the training data, such as when predicting rare diseases or in fraud detection. This class imbalance presents a significant algorithmic challenge, which can be further exacerbated when privacy-preserving techniques such as differential privacy are applied to protect sensitive training data. Our work formalizes these challenges and provides a number of algorithmic solutions. We consider DP variants of pre-processing methods that privately augment the original dataset to reduce the class imbalance; these include oversampling, SMOTE, and private synthetic data generation. We also consider DP variants of in-processing techniques, which adjust the learning algorithm to account for the imbalance; these include model bagging, class-weighted empirical risk minimization and class-weighted deep learning. For each method, we either adapt an existing imbalanced learning technique to the private setting or demonstrate its incompatibility with differential privacy. Finally, we empirically evaluate these privacy-preserving imbalanced learning methods under various data and distributional settings. We find that private synthetic data methods perform well as a data pre-processing step, while class-weighted ERMs are an alternative in higher-dimensional settings where private synthetic data suffers from the curse of dimensionality.