 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Shift Equivariance Impacts Metric Learning for Instance Segmentation
Jan 14, 2021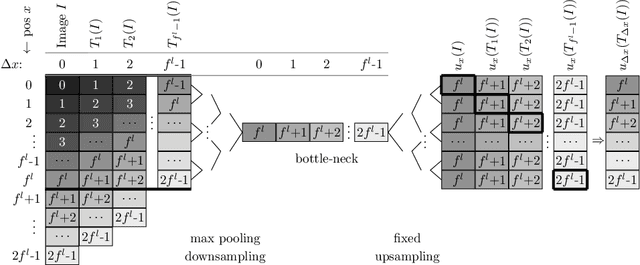

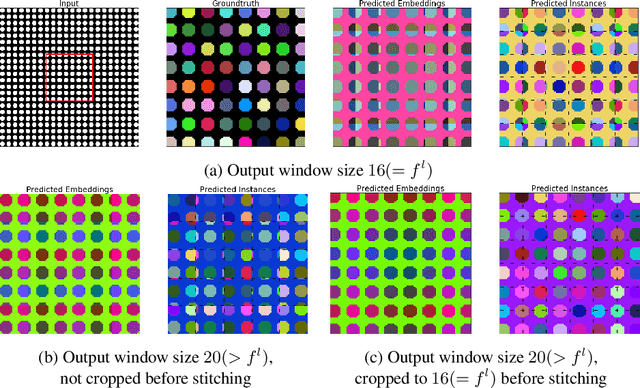

Metric learning has received conflicting assessments concerning its suitability for solving instance segmentation tasks. It has been dismissed as theoretically flawed due to the shift equivariance of the employed CNNs and their respective inability to distinguish same-looking objects. Yet it has been shown to yield state of the art results for a variety of tasks, and practical issues have mainly been reported in the context of tile-and-stitch approaches, where discontinuities at tile boundaries have been observed. To date, neither of the reported issues have undergone thorough formal analysis. In our work, we contribute a comprehensive formal analysis of the shift equivariance properties of encoder-decoder-style CNNs, which yields a clear picture of what can and cannot be achieved with metric learning in the face of same-looking objects. In particular, we prove that a standard encoder-decoder network that takes $d$-dimensional images as input, with $l$ pooling layers and pooling factor $f$, has the capacity to distinguish at most $f^{dl}$ same-looking objects, and we show that this upper limit can be reached. Furthermore, we show that to avoid discontinuities in a tile-and-stitch approach, assuming standard batch size 1, it is necessary to employ valid convolutions in combination with a training output window size strictly greater than $f^l$, while at test-time it is necessary to crop tiles to size $n\cdot f^l$ before stitching, with $n\geq 1$. We complement these theoretical findings by discussing a number of insightful special cases for which we show empirical results on synthetic data.
Mean Box Pooling: A Rich Image Representation and Output Embedding for the Visual Madlibs Task
Aug 09, 2016
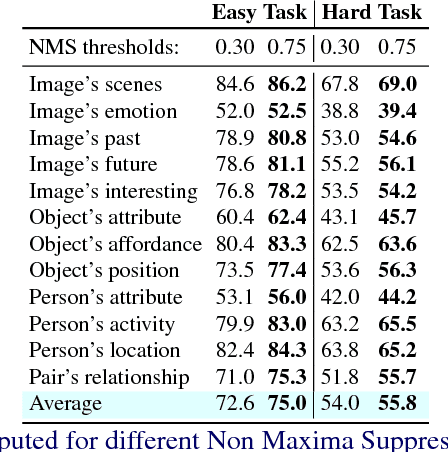

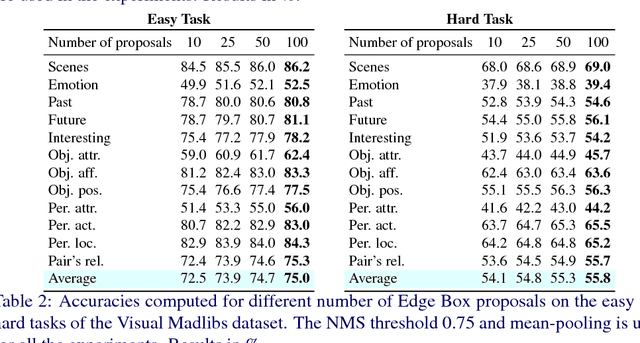
We present Mean Box Pooling, a novel visual representation that pools over CNN representations of a large number, highly overlapping object proposals. We show that such representation together with nCCA, a successful multimodal embedding technique, achieves state-of-the-art performance on the Visual Madlibs task. Moreover, inspired by the nCCA's objective function, we extend classical CNN+LSTM approach to train the network by directly maximizing the similarity between the internal representation of the deep learning architecture and candidate answers. Again, such approach achieves a significant improvement over the prior work that also uses CNN+LSTM approach on Visual Madlibs.