Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMean Box Pooling: A Rich Image Representation and Output Embedding for the Visual Madlibs Task
Paper and Code
Aug 09, 2016
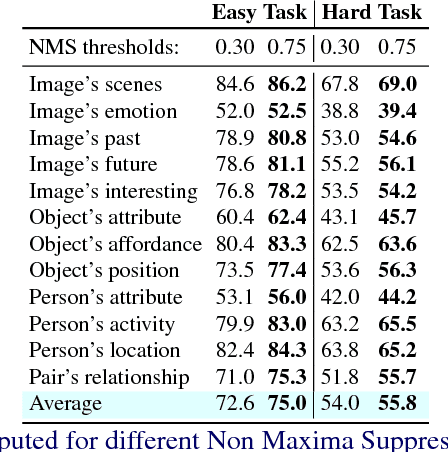

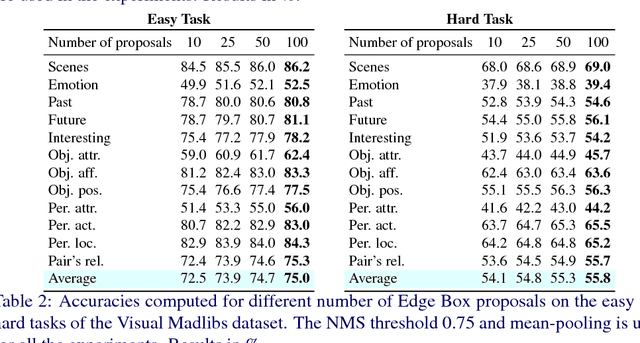
We present Mean Box Pooling, a novel visual representation that pools over CNN representations of a large number, highly overlapping object proposals. We show that such representation together with nCCA, a successful multimodal embedding technique, achieves state-of-the-art performance on the Visual Madlibs task. Moreover, inspired by the nCCA's objective function, we extend classical CNN+LSTM approach to train the network by directly maximizing the similarity between the internal representation of the deep learning architecture and candidate answers. Again, such approach achieves a significant improvement over the prior work that also uses CNN+LSTM approach on Visual Madlibs.
* Accepted to BMVC'16
View paper on