 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot System for Automatic Body Region Detection for Volumetric CT and MR Images
Feb 09, 2026Reliable identification of anatomical body regions is a prerequisite for many automated medical imaging workflows, yet existing solutions remain heavily dependent on unreliable DICOM metadata. Current solutions mainly use supervised learning, which limits their applicability in many real-world scenarios. In this work, we investigate whether body region detection in volumetric CT and MR images can be achieved in a fully zero-shot manner by using knowledge embedded in large pre-trained foundation models. We propose and systematically evaluate three training-free pipelines: (1) a segmentation-driven rule-based system leveraging pre-trained multi-organ segmentation models, (2) a Multimodal Large Language Model (MLLM) guided by radiologist-defined rules, and (3) a segmentation-aware MLLM that combines visual input with explicit anatomical evidence. All methods are evaluated on 887 heterogeneous CT and MR scans with manually verified anatomical region labels. The segmentation-driven rule-based approach achieves the strongest and most consistent performance, with weighted F1-scores of 0.947 (CT) and 0.914 (MR), demonstrating robustness across modalities and atypical scan coverage. The MLLM performs competitively in visually distinctive regions, while the segmentation-aware MLLM reveals fundamental limitations.
HepatoGEN: Generating Hepatobiliary Phase MRI with Perceptual and Adversarial Models
Apr 25, 2025
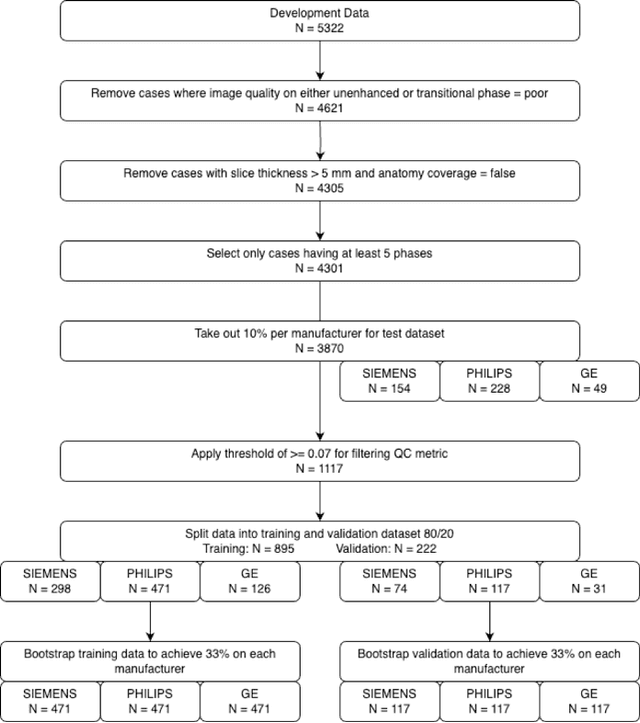


Dynamic contrast-enhanced magnetic resonance imaging (DCE-MRI) plays a crucial role in the detection and characterization of focal liver lesions, with the hepatobiliary phase (HBP) providing essential diagnostic information. However, acquiring HBP images requires prolonged scan times, which may compromise patient comfort and scanner throughput. In this study, we propose a deep learning based approach for synthesizing HBP images from earlier contrast phases (precontrast and transitional) and compare three generative models: a perceptual U-Net, a perceptual GAN (pGAN), and a denoising diffusion probabilistic model (DDPM). We curated a multi-site DCE-MRI dataset from diverse clinical settings and introduced a contrast evolution score (CES) to assess training data quality, enhancing model performance. Quantitative evaluation using pixel-wise and perceptual metrics, combined with qualitative assessment through blinded radiologist reviews, showed that pGAN achieved the best quantitative performance but introduced heterogeneous contrast in out-of-distribution cases. In contrast, the U-Net produced consistent liver enhancement with fewer artifacts, while DDPM underperformed due to limited preservation of fine structural details. These findings demonstrate the feasibility of synthetic HBP image generation as a means to reduce scan time without compromising diagnostic utility, highlighting the clinical potential of deep learning for dynamic contrast enhancement in liver MRI. A project demo is available at: https://jhooge.github.io/hepatogen
Exploring AI-based System Design for Pixel-level Protected Health Information Detection in Medical Images
Jan 16, 2025

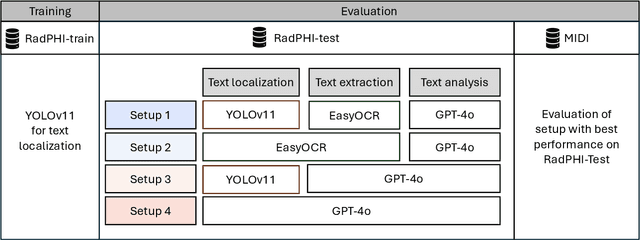

De-identification of medical images is a critical step to ensure privacy during data sharing in research and clinical settings. The initial step in this process involves detecting Protected Health Information (PHI), which can be found in image metadata or imprinted within image pixels. Despite the importance of such systems, there has been limited evaluation of existing AI-based solutions, creating barriers to the development of reliable and robust tools. In this study, we present an AI-based pipeline for PHI detection, comprising three key components: text detection, text extraction, and analysis of PHI content in medical images. By experimenting with exchanging roles of vision and language models within the pipeline, we evaluate the performance and recommend the best setup for the PHI detection task.
Similarity Metrics for MR Image-To-Image Translation
May 15, 2024Image-to-image translation can create large impact in medical imaging, i.e. if images of a patient can be translated to another modality, type or sequence for better diagnosis. However, these methods must be validated by human reader studies, which are costly and restricted to small samples. Automatic evaluation of large samples to pre-evaluate and continuously improve methods before human validation is needed. In this study, we give an overview of reference and non-reference metrics for image synthesis assessment and investigate the ability of nine metrics, that need a reference (SSIM, MS-SSIM, PSNR, MSE, NMSE, MAE, LPIPS, NMI and PCC) and three non-reference metrics (BLUR, MSN, MNG) to detect 11 kinds of distortions in MR images from the BraSyn dataset. In addition we test a downstream segmentation metric and the effect of three normalization methods (Minmax, cMinMax and Zscore). Although PSNR and SSIM are frequently used to evaluate generative models for image-to-image-translation tasks in the medical domain, they show very specific shortcomings. SSIM ignores blurring but is very sensitive to intensity shifts in unnormalized MR images. PSNR is even more sensitive to different normalization methods and hardly measures the degree of distortions. Further metrics, such as LPIPS, NMI and DICE can be very useful to evaluate other similarity aspects. If the images to be compared are misaligned, most metrics are flawed. By carefully selecting and reasonably combining image similarity metrics, the training and selection of generative models for MR image synthesis can be improved. Many aspects of their output can be validated before final and costly evaluation by trained radiologists is conducted.