 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Effects of Diffusion-based Conditional Generative Speech Models Used for Speech Enhancement on Dysarthric Speech
Dec 18, 2024In this study, we aim to explore the effect of pre-trained conditional generative speech models for the first time on dysarthric speech due to Parkinson's disease recorded in an ideal/non-noisy condition. Considering one category of generative models, i.e., diffusion-based speech enhancement, these models are previously trained to learn the distribution of clean (i.e, recorded in a noise-free environment) typical speech signals. Therefore, we hypothesized that when being exposed to dysarthric speech they might remove the unseen atypical paralinguistic cues during the enhancement process. By considering the automatic dysarthric speech detection task, in this study, we experimentally show that during the enhancement process of dysarthric speech data recorded in an ideal non-noisy environment, some of the acoustic dysarthric speech cues are lost. Therefore such pre-trained models are not yet suitable in the context of dysarthric speech enhancement since they manipulate the pathological speech cues when they process clean dysarthric speech. Furthermore, we show that the removed acoustics cues by the enhancement models in the form of residue speech signal can provide complementary dysarthric cues when fused with the original input speech signal in the feature space.
Comparing supervised and self-supervised embedding for ExVo Multi-Task learning track
Jun 23, 2022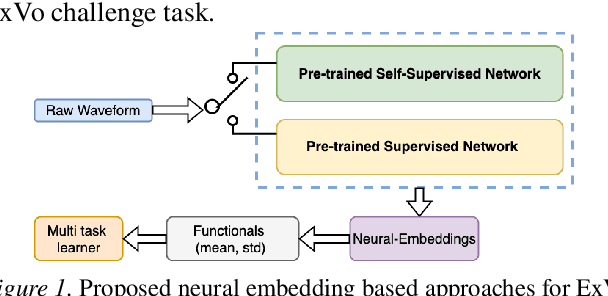
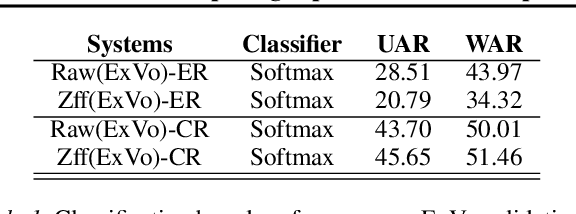
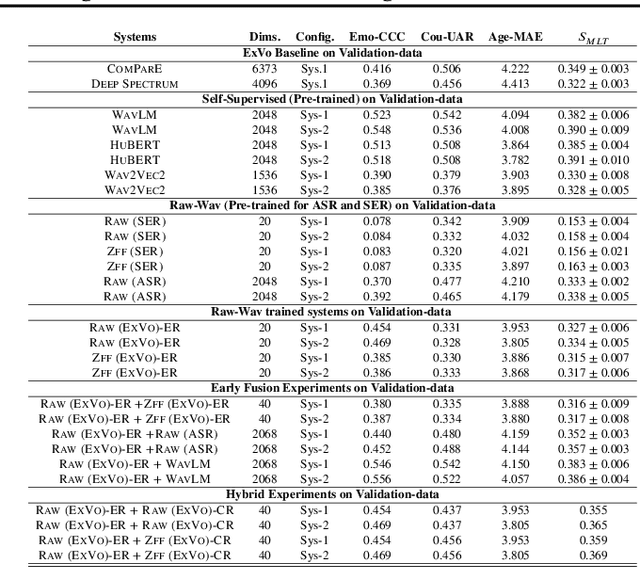
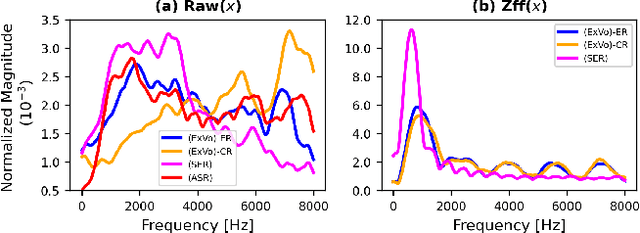
The ICML Expressive Vocalizations (ExVo) Multi-task challenge 2022, focuses on understanding the emotional facets of the non-linguistic vocalizations (vocal bursts (VB)). The objective of this challenge is to predict emotional intensities for VB, being a multi-task challenge it also requires to predict speakers' age and native-country. For this challenge we study and compare two distinct embedding spaces namely, self-supervised learning (SSL) based embeddings and task-specific supervised learning based embeddings. Towards that, we investigate feature representations obtained from several pre-trained SSL neural networks and task-specific supervised classification neural networks. Our studies show that the best performance is obtained with a hybrid approach, where predictions derived via both SSL and task-specific supervised learning are used. Our best system on test-set surpasses the ComPARE baseline (harmonic mean of all sub-task scores i.e., $S_{MTL}$) by a relative $13\%$ margin.