 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward using Speech to Sense Student Emotion in Remote Learning Environments
Apr 10, 2026With advancements in multimodal communication technologies, remote learning environments such as, distance universities are increasing. Remote learning typically happens asynchronously. As a consequence, unlike face-to-face in-person classroom teaching, this lacks availability of sufficient emotional cues for making learning a pleasant experience. Motivated by advances made in the paralinguistic speech processing community on emotion prediction, in this paper we explore use of speech for sensing students' emotions by building upon speech-based self-control tasks developed to aid effective remote learning. More precisely, we investigate: (a) whether speech acquired through self-control tasks exhibit perceptible variation along valence, arousal, and dominance dimensions? and (b) whether those dimensional emotion variations can be automatically predicted? We address these two research questions by developing a dataset containing spontaneous monologue speech acquired as open responses to self-control tasks and by carrying out subjective listener evaluations and automatic dimensional emotion prediction studies on that dataset. Our investigations indicate that speech-based self-control tasks can be a means to sense student emotion in remote learning environment. This opens potential venues to seamlessly integrate paralinguistic speech processing technologies in the remote learning loop for enhancing learning experiences through instructional design and feedback generation.
Multilingual Hidden Prompt Injection Attacks on LLM-Based Academic Reviewing
Dec 29, 2025Large language models (LLMs) are increasingly considered for use in high-impact workflows, including academic peer review. However, LLMs are vulnerable to document-level hidden prompt injection attacks. In this work, we construct a dataset of approximately 500 real academic papers accepted to ICML and evaluate the effect of embedding hidden adversarial prompts within these documents. Each paper is injected with semantically equivalent instructions in four different languages and reviewed using an LLM. We find that prompt injection induces substantial changes in review scores and accept/reject decisions for English, Japanese, and Chinese injections, while Arabic injections produce little to no effect. These results highlight the susceptibility of LLM-based reviewing systems to document-level prompt injection and reveal notable differences in vulnerability across languages.
Towards Leveraging Sequential Structure in Animal Vocalizations
Nov 13, 2025Animal vocalizations contain sequential structures that carry important communicative information, yet most computational bioacoustics studies average the extracted frame-level features across the temporal axis, discarding the order of the sub-units within a vocalization. This paper investigates whether discrete acoustic token sequences, derived through vector quantization and gumbel-softmax vector quantization of extracted self-supervised speech model representations can effectively capture and leverage temporal information. To that end, pairwise distance analysis of token sequences generated from HuBERT embeddings shows that they can discriminate call-types and callers across four bioacoustics datasets. Sequence classification experiments using $k$-Nearest Neighbour with Levenshtein distance show that the vector-quantized token sequences yield reasonable call-type and caller classification performances, and hold promise as alternative feature representations towards leveraging sequential information in animal vocalizations.
On feature representations for marmoset vocal communication analysis
Apr 21, 2025The acoustic analysis of marmoset (Callithrix jacchus) vocalizations is often used to understand the evolutionary origins of human language. Currently, the analysis is largely carried out in a manual or semi-manual manner. Thus, there is a need to develop automatic call analysis methods. In that direction, research has been limited to the development of analysis methods with small amounts of data or for specific scenarios. Furthermore, there is lack of prior knowledge about what type of information is relevant for different call analysis tasks. To address these issues, as a first step, this paper explores different feature representation methods, namely, HCTSA-based hand-crafted features Catch22, pre-trained self supervised learning (SSL) based features extracted from neural networks trained on human speech and end-to-end acoustic modeling for call-type classification, caller identification and caller sex identification. Through an investigation on three different marmoset call datasets, we demonstrate that SSL-based feature representations and end-to-end acoustic modeling tend to lead to better systems than Catch22 features for call-type and caller classification. Furthermore, we also highlight the impact of signal bandwidth on the obtained task performances.
Unsupervised Rhythm and Voice Conversion of Dysarthric to Healthy Speech for ASR
Jan 17, 2025Automatic speech recognition (ASR) systems are well known to perform poorly on dysarthric speech. Previous works have addressed this by speaking rate modification to reduce the mismatch with typical speech. Unfortunately, these approaches rely on transcribed speech data to estimate speaking rates and phoneme durations, which might not be available for unseen speakers. Therefore, we combine unsupervised rhythm and voice conversion methods based on self-supervised speech representations to map dysarthric to typical speech. We evaluate the outputs with a large ASR model pre-trained on healthy speech without further fine-tuning and find that the proposed rhythm conversion especially improves performance for speakers of the Torgo corpus with more severe cases of dysarthria. Code and audio samples are available at https://idiap.github.io/RnV .
Comparing Self-Supervised Learning Models Pre-Trained on Human Speech and Animal Vocalizations for Bioacoustics Processing
Jan 10, 2025Self-supervised learning (SSL) foundation models have emerged as powerful, domain-agnostic, general-purpose feature extractors applicable to a wide range of tasks. Such models pre-trained on human speech have demonstrated high transferability for bioacoustic processing. This paper investigates (i) whether SSL models pre-trained directly on animal vocalizations offer a significant advantage over those pre-trained on speech, and (ii) whether fine-tuning speech-pretrained models on automatic speech recognition (ASR) tasks can enhance bioacoustic classification. We conduct a comparative analysis using three diverse bioacoustic datasets and two different bioacoustic tasks. Results indicate that pre-training on bioacoustic data provides only marginal improvements over speech-pretrained models, with comparable performance in most scenarios. Fine-tuning on ASR tasks yields mixed outcomes, suggesting that the general-purpose representations learned during SSL pre-training are already well-suited for bioacoustic tasks. These findings highlight the robustness of speech-pretrained SSL models for bioacoustics and imply that extensive fine-tuning may not be necessary for optimal performance.
Feature Representations for Automatic Meerkat Vocalization Classification
Aug 27, 2024Understanding evolution of vocal communication in social animals is an important research problem. In that context, beyond humans, there is an interest in analyzing vocalizations of other social animals such as, meerkats, marmosets, apes. While existing approaches address vocalizations of certain species, a reliable method tailored for meerkat calls is lacking. To that extent, this paper investigates feature representations for automatic meerkat vocalization analysis. Both traditional signal processing-based representations and data-driven representations facilitated by advances in deep learning are explored. Call type classification studies conducted on two data sets reveal that feature extraction methods developed for human speech processing can be effectively employed for automatic meerkat call analysis.
SSL-TTS: Leveraging Self-Supervised Embeddings and kNN Retrieval for Zero-Shot Multi-speaker TTS
Aug 20, 2024While recent zero-shot multispeaker text-to-speech (TTS) models achieve impressive results, they typically rely on extensive transcribed speech datasets from numerous speakers and intricate training pipelines. Meanwhile, self-supervised learning (SSL) speech features have emerged as effective intermediate representations for TTS. It was also observed that SSL features from different speakers that are linearly close share phonetic information while maintaining individual speaker identity, which enables straight-forward and robust voice cloning. In this study, we introduce SSL-TTS, a lightweight and efficient zero-shot TTS framework trained on transcribed speech from a single speaker. SSL-TTS leverages SSL features and retrieval methods for simple and robust zero-shot multi-speaker synthesis. Objective and subjective evaluations show that our approach achieves performance comparable to state-of-the-art models that require significantly larger training datasets. The low training data requirements mean that SSL-TTS is well suited for the development of multi-speaker TTS systems for low-resource domains and languages. We also introduce an interpolation parameter which enables fine control over the output speech by blending voices. Demo samples are available at https://idiap.github.io/ssl-tts
Towards interfacing large language models with ASR systems using confidence measures and prompting
Jul 31, 2024As large language models (LLMs) grow in parameter size and capabilities, such as interaction through prompting, they open up new ways of interfacing with automatic speech recognition (ASR) systems beyond rescoring n-best lists. This work investigates post-hoc correction of ASR transcripts with LLMs. To avoid introducing errors into likely accurate transcripts, we propose a range of confidence-based filtering methods. Our results indicate that this can improve the performance of less competitive ASR systems.
On the Utility of Speech and Audio Foundation Models for Marmoset Call Analysis
Jul 24, 2024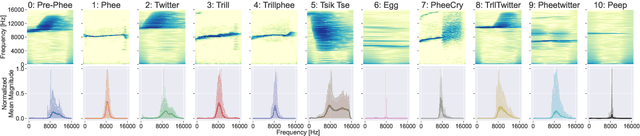
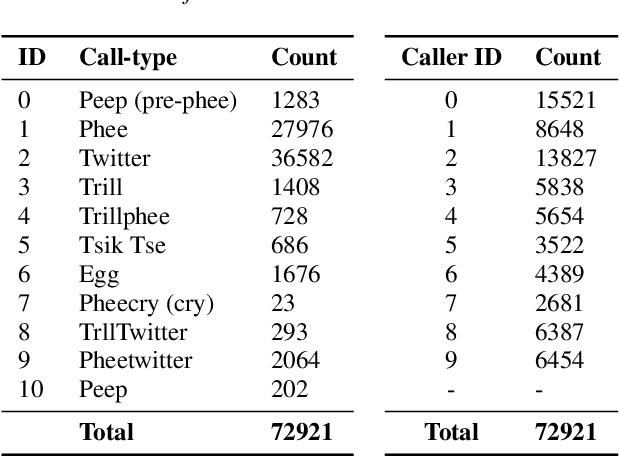
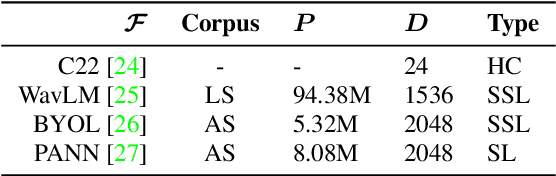
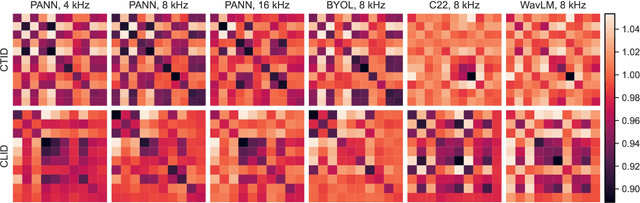
Marmoset monkeys encode vital information in their calls and serve as a surrogate model for neuro-biologists to understand the evolutionary origins of human vocal communication. Traditionally analyzed with signal processing-based features, recent approaches have utilized self-supervised models pre-trained on human speech for feature extraction, capitalizing on their ability to learn a signal's intrinsic structure independently of its acoustic domain. However, the utility of such foundation models remains unclear for marmoset call analysis in terms of multi-class classification, bandwidth, and pre-training domain. This study assesses feature representations derived from speech and general audio domains, across pre-training bandwidths of 4, 8, and 16 kHz for marmoset call-type and caller classification tasks. Results show that models with higher bandwidth improve performance, and pre-training on speech or general audio yields comparable results, improving over a spectral baseline.