 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Rhythm and Voice Conversion of Dysarthric to Healthy Speech for ASR
Jan 17, 2025Automatic speech recognition (ASR) systems are well known to perform poorly on dysarthric speech. Previous works have addressed this by speaking rate modification to reduce the mismatch with typical speech. Unfortunately, these approaches rely on transcribed speech data to estimate speaking rates and phoneme durations, which might not be available for unseen speakers. Therefore, we combine unsupervised rhythm and voice conversion methods based on self-supervised speech representations to map dysarthric to typical speech. We evaluate the outputs with a large ASR model pre-trained on healthy speech without further fine-tuning and find that the proposed rhythm conversion especially improves performance for speakers of the Torgo corpus with more severe cases of dysarthria. Code and audio samples are available at https://idiap.github.io/RnV .
SSL-TTS: Leveraging Self-Supervised Embeddings and kNN Retrieval for Zero-Shot Multi-speaker TTS
Aug 20, 2024While recent zero-shot multispeaker text-to-speech (TTS) models achieve impressive results, they typically rely on extensive transcribed speech datasets from numerous speakers and intricate training pipelines. Meanwhile, self-supervised learning (SSL) speech features have emerged as effective intermediate representations for TTS. It was also observed that SSL features from different speakers that are linearly close share phonetic information while maintaining individual speaker identity, which enables straight-forward and robust voice cloning. In this study, we introduce SSL-TTS, a lightweight and efficient zero-shot TTS framework trained on transcribed speech from a single speaker. SSL-TTS leverages SSL features and retrieval methods for simple and robust zero-shot multi-speaker synthesis. Objective and subjective evaluations show that our approach achieves performance comparable to state-of-the-art models that require significantly larger training datasets. The low training data requirements mean that SSL-TTS is well suited for the development of multi-speaker TTS systems for low-resource domains and languages. We also introduce an interpolation parameter which enables fine control over the output speech by blending voices. Demo samples are available at https://idiap.github.io/ssl-tts
Towards interfacing large language models with ASR systems using confidence measures and prompting
Jul 31, 2024As large language models (LLMs) grow in parameter size and capabilities, such as interaction through prompting, they open up new ways of interfacing with automatic speech recognition (ASR) systems beyond rescoring n-best lists. This work investigates post-hoc correction of ASR transcripts with LLMs. To avoid introducing errors into likely accurate transcripts, we propose a range of confidence-based filtering methods. Our results indicate that this can improve the performance of less competitive ASR systems.
An Objective Evaluation Framework for Pathological Speech Synthesis
Jul 01, 2021
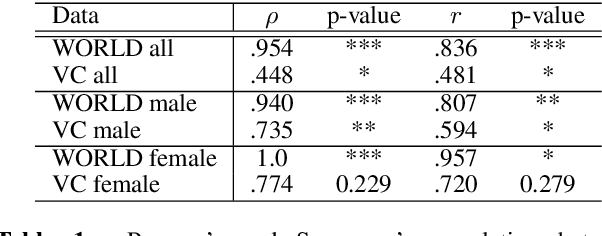

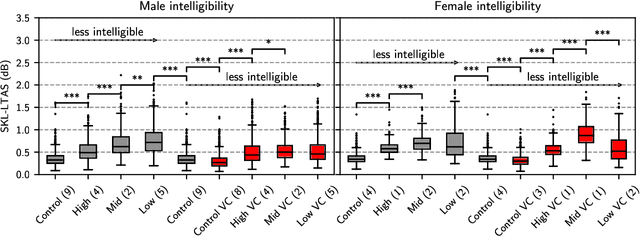
The development of pathological speech systems is currently hindered by the lack of a standardised objective evaluation framework. In this work, (1) we utilise existing detection and analysis techniques to propose a general framework for the consistent evaluation of synthetic pathological speech. This framework evaluates the voice quality and the intelligibility aspects of speech and is shown to be complementary using our experiments. (2) Using our proposed evaluation framework, we develop and test a dysarthric voice conversion system (VC) using CycleGAN-VC and a PSOLA-based speech rate modification technique. We show that the developed system is able to synthesise dysarthric speech with different levels of speech intelligibility.
Multilingual and Unsupervised Subword Modeling for Zero-Resource Languages
Nov 09, 2018



Unsupervised subword modeling aims to learn low-level representations of speech audio in "zero-resource" settings: that is, without using transcriptions or other resources from the target language (such as text corpora or pronunciation dictionaries). A good representation should capture phonetic content and abstract away from other types of variability, such as speaker differences and channel noise. Previous work in this area has primarily focused on learning from target language data only, and has been evaluated only intrinsically. Here we directly compare multiple methods, including some that use only target language speech data and some that use transcribed speech from other (non-target) languages, and we evaluate using two intrinsic measures as well as on a downstream unsupervised word segmentation and clustering task. We find that combining two existing target-language-only methods yields better features than either method alone. Nevertheless, even better results are obtained by extracting target language bottleneck features using a model trained on other languages. Cross-lingual training using just one other language is enough to provide this benefit, but multilingual training helps even more. In addition to these results, which hold across both intrinsic measures and the extrinsic task, we discuss the qualitative differences between the different types of learned features.
Multilingual bottleneck features for subword modeling in zero-resource languages
Jun 18, 2018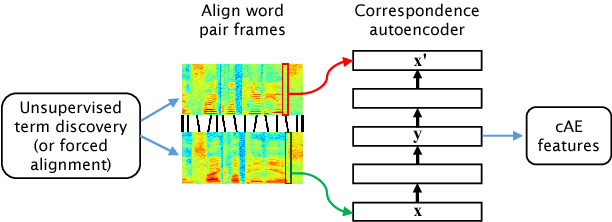



How can we effectively develop speech technology for languages where no transcribed data is available? Many existing approaches use no annotated resources at all, yet it makes sense to leverage information from large annotated corpora in other languages, for example in the form of multilingual bottleneck features (BNFs) obtained from a supervised speech recognition system. In this work, we evaluate the benefits of BNFs for subword modeling (feature extraction) in six unseen languages on a word discrimination task. First we establish a strong unsupervised baseline by combining two existing methods: vocal tract length normalisation (VTLN) and the correspondence autoencoder (cAE). We then show that BNFs trained on a single language already beat this baseline; including up to 10 languages results in additional improvements which cannot be matched by just adding more data from a single language. Finally, we show that the cAE can improve further on the BNFs if high-quality same-word pairs are available.