 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManipulation of oral cancer speech using neural articulatory synthesis
Mar 31, 2022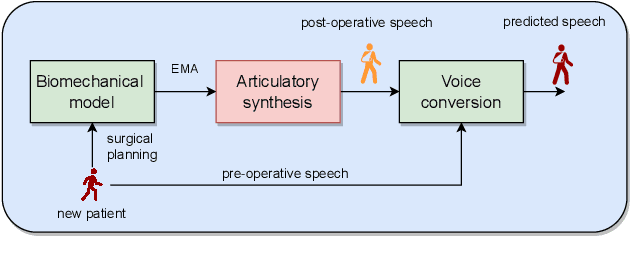
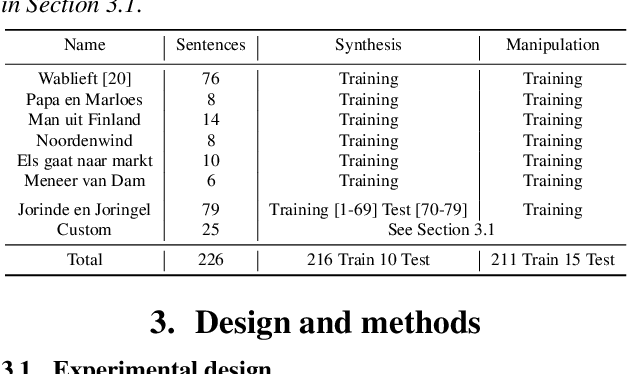
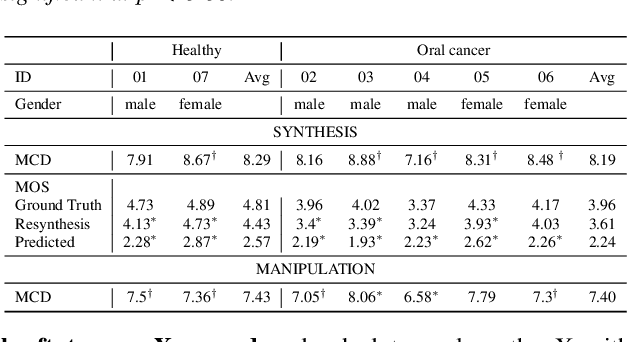
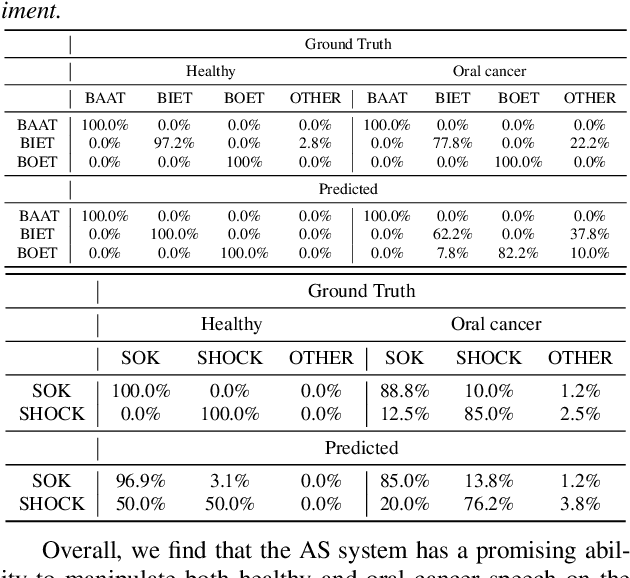
We present an articulatory synthesis framework for the synthesis and manipulation of oral cancer speech for clinical decision making and alleviation of patient stress. Objective and subjective evaluations demonstrate that the framework has acceptable naturalness and is worth further investigation. A subsequent subjective vowel and consonant identification experiment showed that the articulatory synthesis system can manipulate the articulatory trajectories so that the synthesised speech reproduces problems present in the ground truth oral cancer speech.
An Objective Evaluation Framework for Pathological Speech Synthesis
Jul 01, 2021
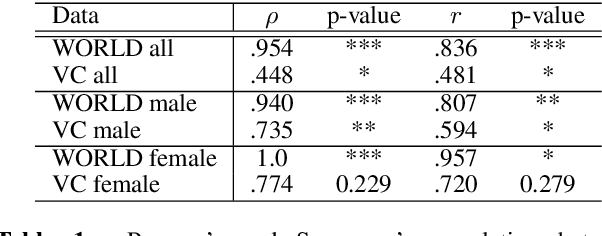

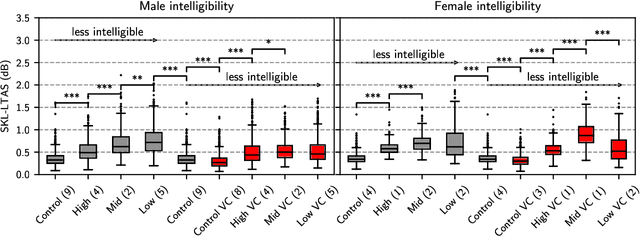
The development of pathological speech systems is currently hindered by the lack of a standardised objective evaluation framework. In this work, (1) we utilise existing detection and analysis techniques to propose a general framework for the consistent evaluation of synthetic pathological speech. This framework evaluates the voice quality and the intelligibility aspects of speech and is shown to be complementary using our experiments. (2) Using our proposed evaluation framework, we develop and test a dysarthric voice conversion system (VC) using CycleGAN-VC and a PSOLA-based speech rate modification technique. We show that the developed system is able to synthesise dysarthric speech with different levels of speech intelligibility.
Pathological voice adaptation with autoencoder-based voice conversion
Jun 15, 2021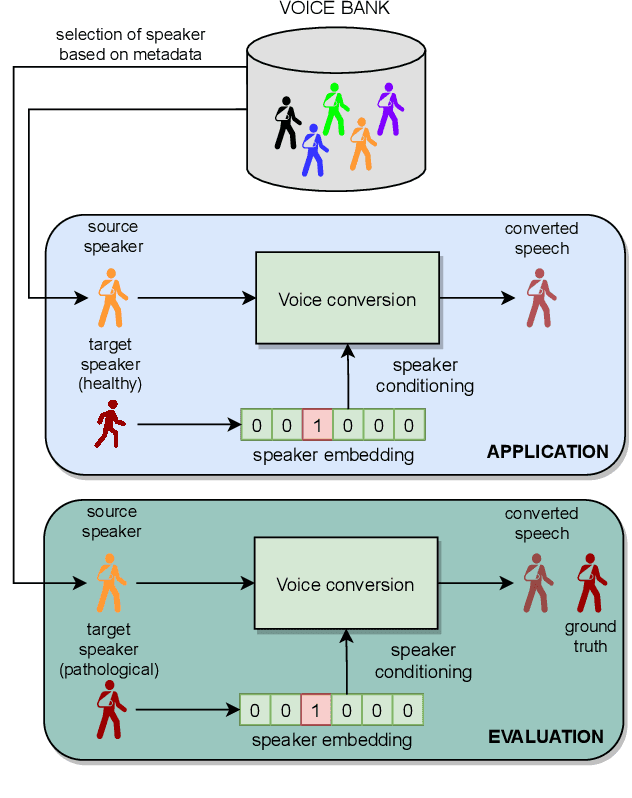

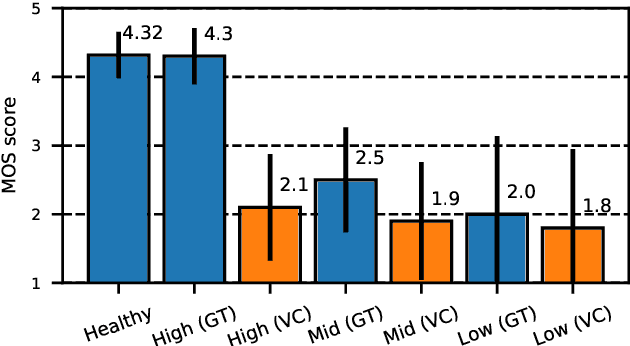
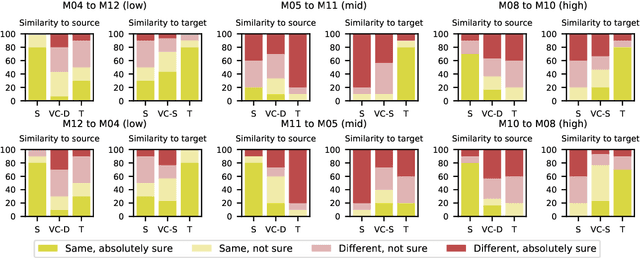
In this paper, we propose a new approach to pathological speech synthesis. Instead of using healthy speech as a source, we customise an existing pathological speech sample to a new speaker's voice characteristics. This approach alleviates the evaluation problem one normally has when converting typical speech to pathological speech, as in our approach, the voice conversion (VC) model does not need to be optimised for speech degradation but only for the speaker change. This change in the optimisation ensures that any degradation found in naturalness is due to the conversion process and not due to the model exaggerating characteristics of a speech pathology. To show a proof of concept of this method, we convert dysarthric speech using the UASpeech database and an autoencoder-based VC technique. Subjective evaluation results show reasonable naturalness for high intelligibility dysarthric speakers, though lower intelligibility seems to introduce a marginal degradation in naturalness scores for mid and low intelligibility speakers compared to ground truth. Conversion of speaker characteristics for low and high intelligibility speakers is successful, but not for mid. Whether the differences in the results for the different intelligibility levels is due to the intelligibility levels or due to the speakers needs to be further investigated.
Detecting and analysing spontaneous oral cancer speech in the wild
Jul 28, 2020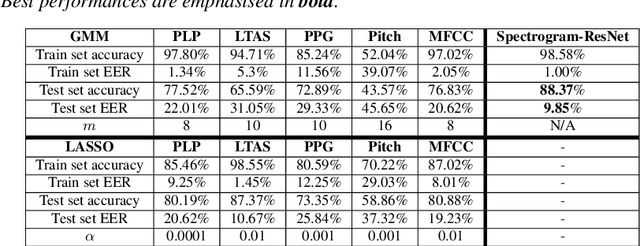
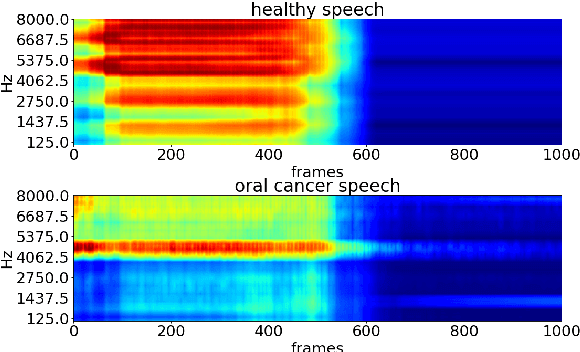
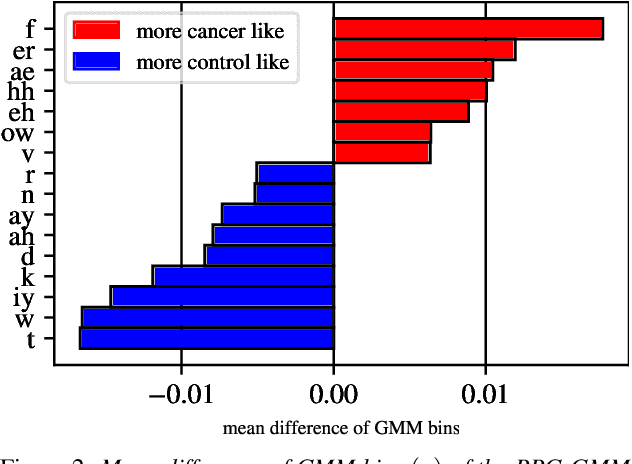
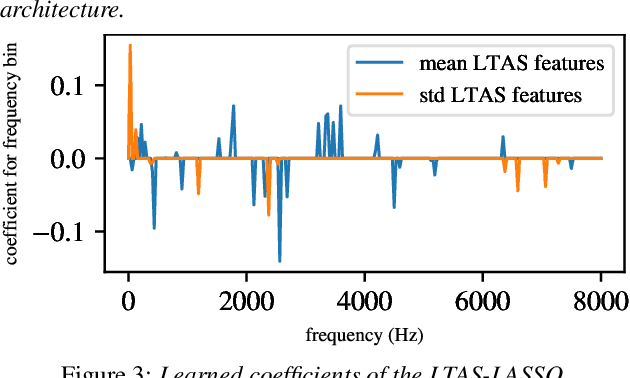
Oral cancer speech is a disease which impacts more than half a million people worldwide every year. Analysis of oral cancer speech has so far focused on read speech. In this paper, we 1) present and 2) analyse a three-hour long spontaneous oral cancer speech dataset collected from YouTube. 3) We set baselines for an oral cancer speech detection task on this dataset. The analysis of these explainable machine learning baselines shows that sibilants and stop consonants are the most important indicators for spontaneous oral cancer speech detection.