 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the effect of speech pathology on automatic and human speaker verification
Jun 10, 2024



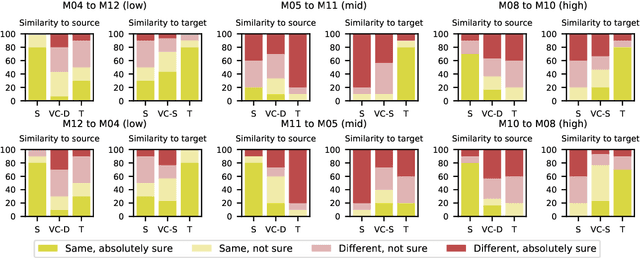
This study investigates how surgical intervention for speech pathology (specifically, as a result of oral cancer surgery) impacts the performance of an automatic speaker verification (ASV) system. Using two recently collected Dutch datasets with parallel pre and post-surgery audio from the same speaker, NKI-OC-VC and SPOKE, we assess the extent to which speech pathology influences ASV performance, and whether objective/subjective measures of speech severity are correlated with the performance. Finally, we carry out a perceptual study to compare judgements of ASV and human listeners. Our findings reveal that pathological speech negatively affects ASV performance, and the severity of the speech is negatively correlated with the performance. There is a moderate agreement in perceptual and objective scores of speaker similarity and severity, however, we could not clearly establish in the perceptual study, whether the same phenomenon also exists in human perception.
Improving severity preservation of healthy-to-pathological voice conversion with global style tokens
Oct 04, 2023In healthy-to-pathological voice conversion (H2P-VC), healthy speech is converted into pathological while preserving the identity. The paper improves on previous two-stage approach to H2P-VC where (1) speech is created first with the appropriate severity, (2) then the speaker identity of the voice is converted while preserving the severity of the voice. Specifically, we propose improvements to (2) by using phonetic posteriorgrams (PPG) and global style tokens (GST). Furthermore, we present a new dataset that contains parallel recordings of pathological and healthy speakers with the same identity which allows more precise evaluation. Listening tests by expert listeners show that the framework preserves severity of the source sample, while modelling target speaker's voice. We also show that (a) pathology impacts x-vectors but not all speaker information is lost, (b) choosing source speakers based on severity labels alone is insufficient.
Manipulation of oral cancer speech using neural articulatory synthesis
Mar 31, 2022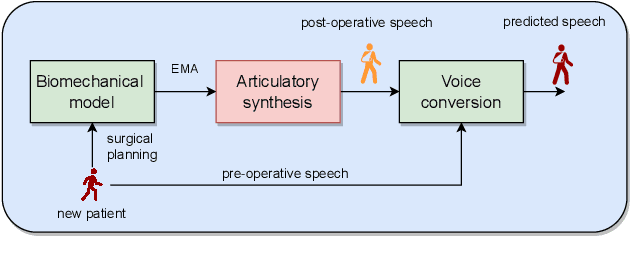
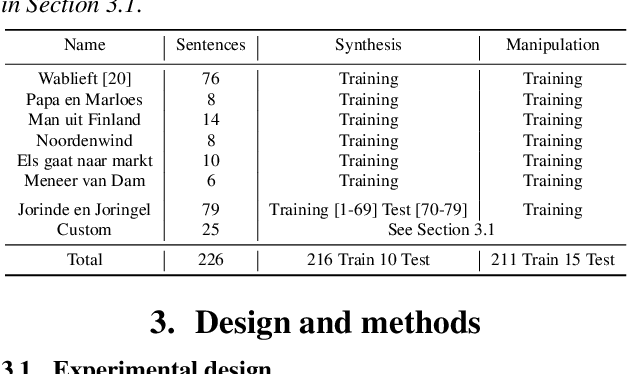
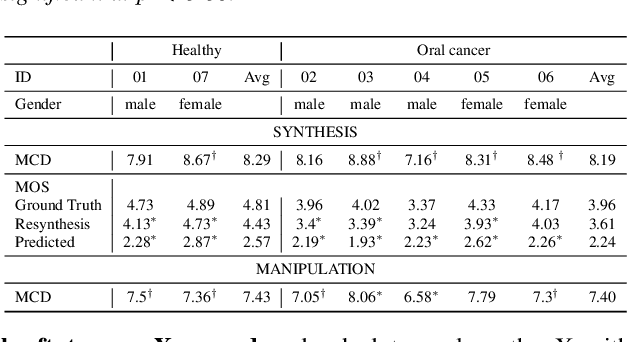
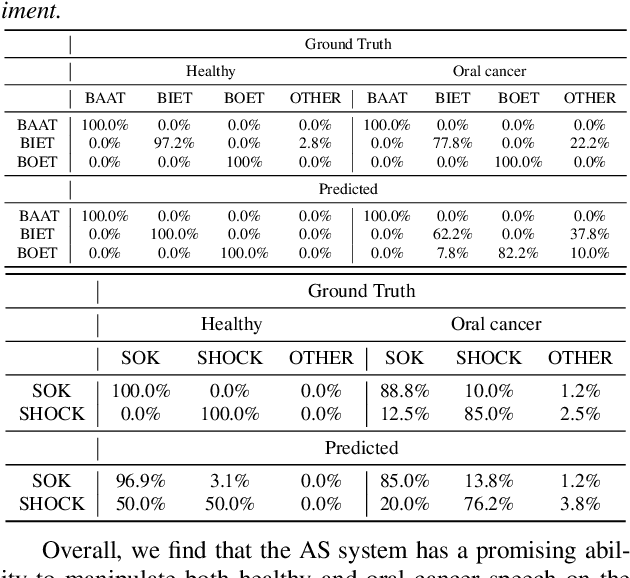
We present an articulatory synthesis framework for the synthesis and manipulation of oral cancer speech for clinical decision making and alleviation of patient stress. Objective and subjective evaluations demonstrate that the framework has acceptable naturalness and is worth further investigation. A subsequent subjective vowel and consonant identification experiment showed that the articulatory synthesis system can manipulate the articulatory trajectories so that the synthesised speech reproduces problems present in the ground truth oral cancer speech.
The Effectiveness of Time Stretching for Enhancing Dysarthric Speech for Improved Dysarthric Speech Recognition
Jan 13, 2022
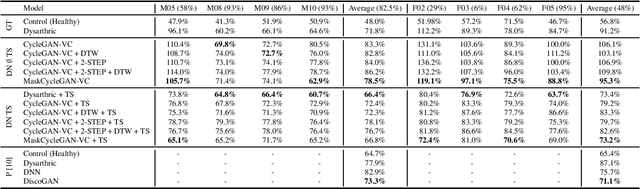
In this paper, we investigate several existing and a new state-of-the-art generative adversarial network-based (GAN) voice conversion method for enhancing dysarthric speech for improved dysarthric speech recognition. We compare key components of existing methods as part of a rigorous ablation study to find the most effective solution to improve dysarthric speech recognition. We find that straightforward signal processing methods such as stationary noise removal and vocoder-based time stretching lead to dysarthric speech recognition results comparable to those obtained when using state-of-the-art GAN-based voice conversion methods as measured using a phoneme recognition task. Additionally, our proposed solution of a combination of MaskCycleGAN-VC and time stretched enhancement is able to improve the phoneme recognition results for certain dysarthric speakers compared to our time stretched baseline.
Towards Identity Preserving Normal to Dysarthric Voice Conversion
Oct 15, 2021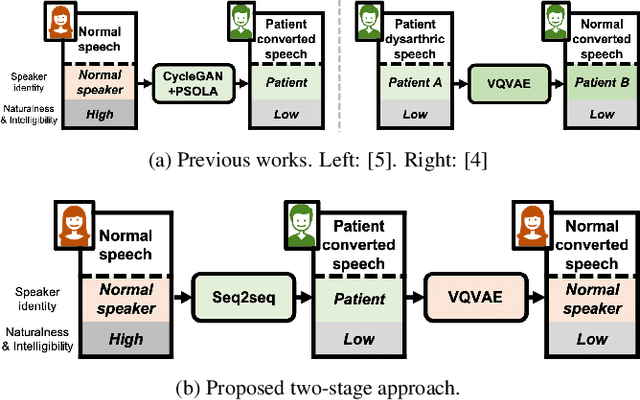
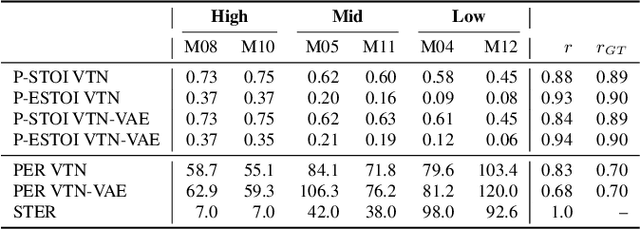

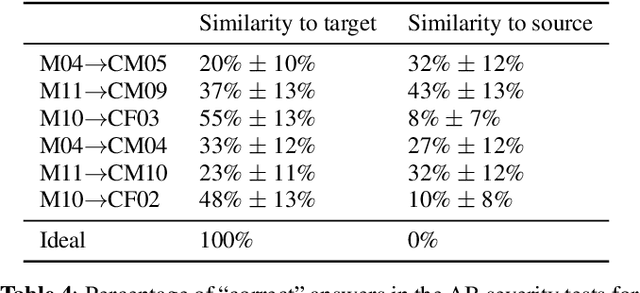
We present a voice conversion framework that converts normal speech into dysarthric speech while preserving the speaker identity. Such a framework is essential for (1) clinical decision making processes and alleviation of patient stress, (2) data augmentation for dysarthric speech recognition. This is an especially challenging task since the converted samples should capture the severity of dysarthric speech while being highly natural and possessing the speaker identity of the normal speaker. To this end, we adopted a two-stage framework, which consists of a sequence-to-sequence model and a nonparallel frame-wise model. Objective and subjective evaluations were conducted on the UASpeech dataset, and results showed that the method was able to yield reasonable naturalness and capture severity aspects of the pathological speech. On the other hand, the similarity to the normal source speaker's voice was limited and requires further improvements.
An Objective Evaluation Framework for Pathological Speech Synthesis
Jul 01, 2021
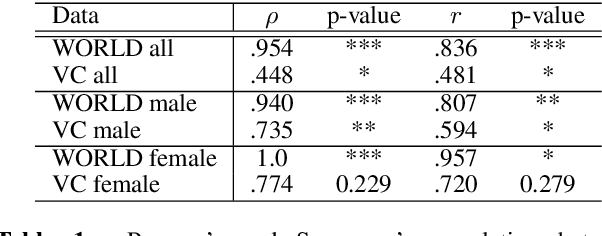

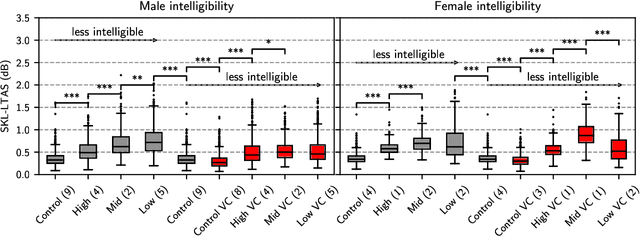
The development of pathological speech systems is currently hindered by the lack of a standardised objective evaluation framework. In this work, (1) we utilise existing detection and analysis techniques to propose a general framework for the consistent evaluation of synthetic pathological speech. This framework evaluates the voice quality and the intelligibility aspects of speech and is shown to be complementary using our experiments. (2) Using our proposed evaluation framework, we develop and test a dysarthric voice conversion system (VC) using CycleGAN-VC and a PSOLA-based speech rate modification technique. We show that the developed system is able to synthesise dysarthric speech with different levels of speech intelligibility.
Pathological voice adaptation with autoencoder-based voice conversion
Jun 15, 2021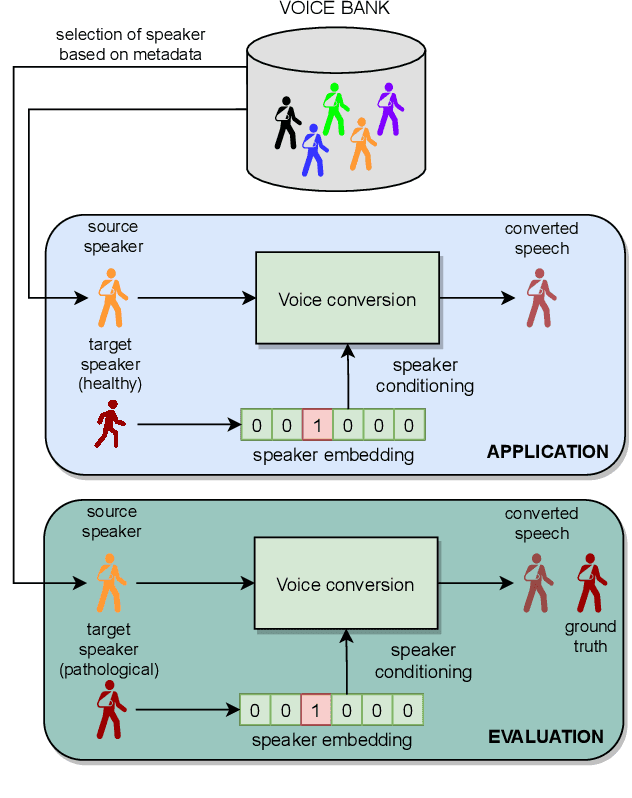

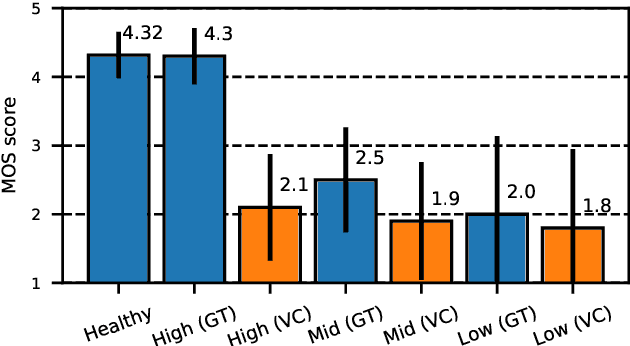
In this paper, we propose a new approach to pathological speech synthesis. Instead of using healthy speech as a source, we customise an existing pathological speech sample to a new speaker's voice characteristics. This approach alleviates the evaluation problem one normally has when converting typical speech to pathological speech, as in our approach, the voice conversion (VC) model does not need to be optimised for speech degradation but only for the speaker change. This change in the optimisation ensures that any degradation found in naturalness is due to the conversion process and not due to the model exaggerating characteristics of a speech pathology. To show a proof of concept of this method, we convert dysarthric speech using the UASpeech database and an autoencoder-based VC technique. Subjective evaluation results show reasonable naturalness for high intelligibility dysarthric speakers, though lower intelligibility seems to introduce a marginal degradation in naturalness scores for mid and low intelligibility speakers compared to ground truth. Conversion of speaker characteristics for low and high intelligibility speakers is successful, but not for mid. Whether the differences in the results for the different intelligibility levels is due to the intelligibility levels or due to the speakers needs to be further investigated.
Quantifying Bias in Automatic Speech Recognition
Apr 01, 2021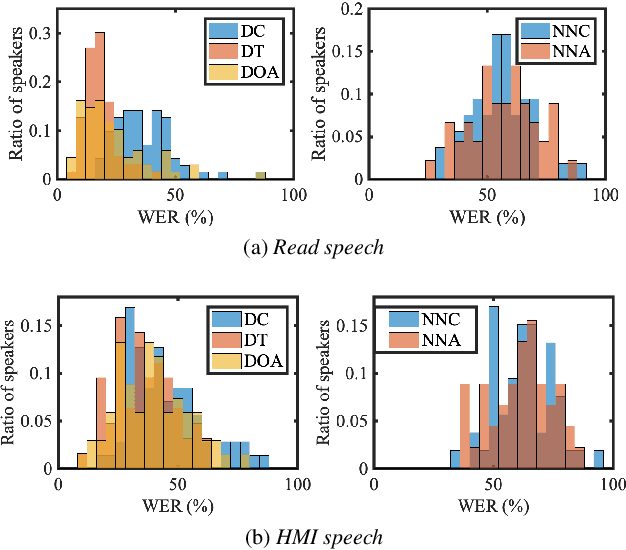
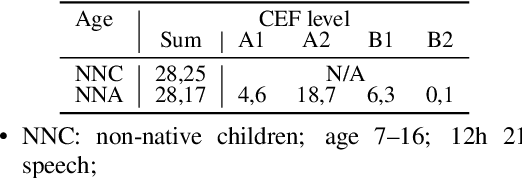
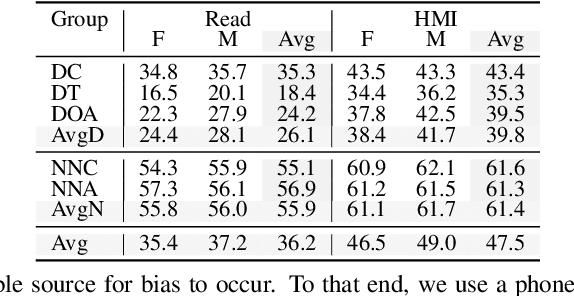
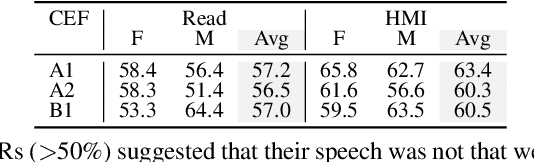
Automatic speech recognition (ASR) systems promise to deliver objective interpretation of human speech. Practice and recent evidence suggests that the state-of-the-art (SotA) ASRs struggle with the large variation in speech due to e.g., gender, age, speech impairment, race, and accents. Many factors can cause the bias of an ASR system. Our overarching goal is to uncover bias in ASR systems to work towards proactive bias mitigation in ASR. This paper is a first step towards this goal and systematically quantifies the bias of a Dutch SotA ASR system against gender, age, regional accents and non-native accents. Word error rates are compared, and an in-depth phoneme-level error analysis is conducted to understand where bias is occurring. We primarily focus on bias due to articulation differences in the dataset. Based on our findings, we suggest bias mitigation strategies for ASR development.
Detecting and analysing spontaneous oral cancer speech in the wild
Jul 28, 2020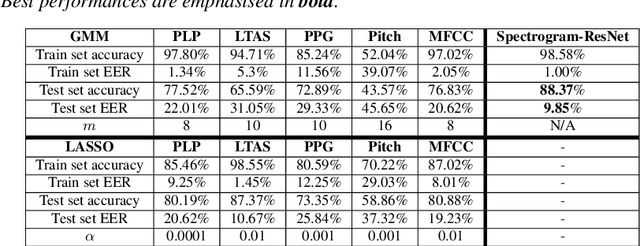
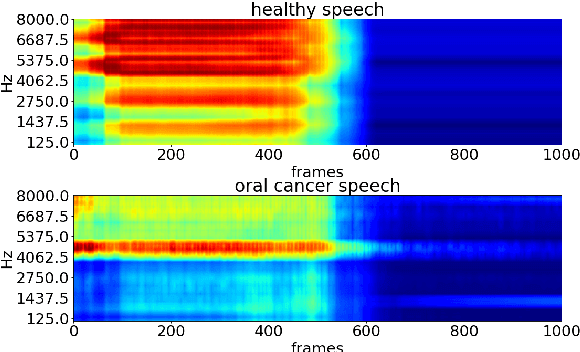
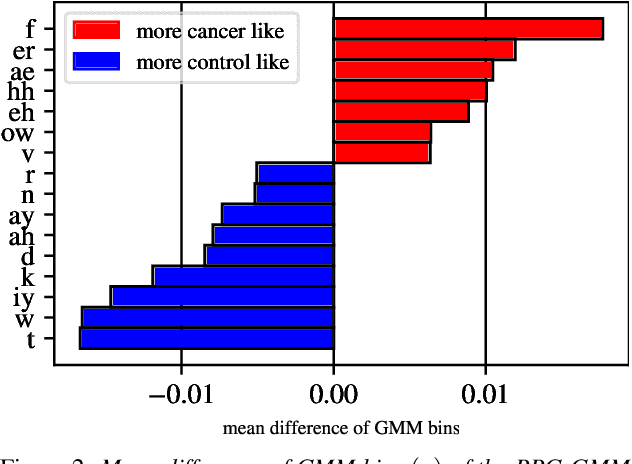
Oral cancer speech is a disease which impacts more than half a million people worldwide every year. Analysis of oral cancer speech has so far focused on read speech. In this paper, we 1) present and 2) analyse a three-hour long spontaneous oral cancer speech dataset collected from YouTube. 3) We set baselines for an oral cancer speech detection task on this dataset. The analysis of these explainable machine learning baselines shows that sibilants and stop consonants are the most important indicators for spontaneous oral cancer speech detection.