 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effectiveness of Time Stretching for Enhancing Dysarthric Speech for Improved Dysarthric Speech Recognition
Paper and Code

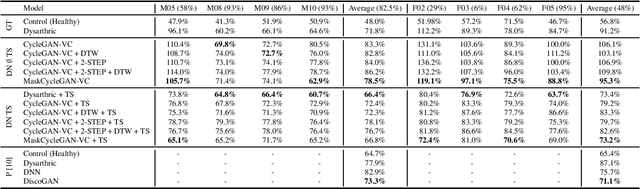
In this paper, we investigate several existing and a new state-of-the-art generative adversarial network-based (GAN) voice conversion method for enhancing dysarthric speech for improved dysarthric speech recognition. We compare key components of existing methods as part of a rigorous ablation study to find the most effective solution to improve dysarthric speech recognition. We find that straightforward signal processing methods such as stationary noise removal and vocoder-based time stretching lead to dysarthric speech recognition results comparable to those obtained when using state-of-the-art GAN-based voice conversion methods as measured using a phoneme recognition task. Additionally, our proposed solution of a combination of MaskCycleGAN-VC and time stretched enhancement is able to improve the phoneme recognition results for certain dysarthric speakers compared to our time stretched baseline.