 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Autoencoder for Personalized Pathological Speech Enhancement
Mar 18, 2025
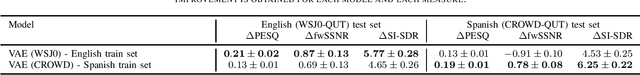

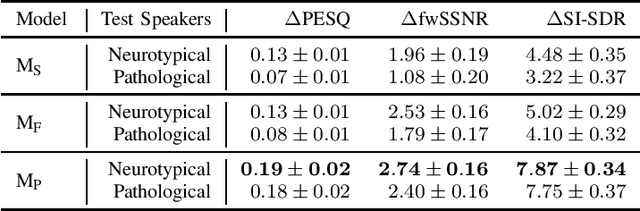
The generalizability of speech enhancement (SE) models across speaker conditions remains largely unexplored, despite its critical importance for broader applicability. This paper investigates the performance of the hybrid variational autoencoder (VAE)-non-negative matrix factorization (NMF) model for SE, focusing primarily on its generalizability to pathological speakers with Parkinson's disease. We show that VAE models trained on large neurotypical datasets perform poorly on pathological speech. While fine-tuning these pre-trained models with pathological speech improves performance, a performance gap remains between neurotypical and pathological speakers. To address this gap, we propose using personalized SE models derived from fine-tuning pre-trained models with only a few seconds of clean data from each speaker. Our results demonstrate that personalized models considerably enhance performance for all speakers, achieving comparable results for both neurotypical and pathological speakers.