 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaloProbe: Bayesian Detection and Mitigation of Object Hallucinations in Vision-Language Models
Apr 07, 2026Large vision-language models can produce object hallucinations in image descriptions, highlighting the need for effective detection and mitigation strategies. Prior work commonly relies on the model's attention weights on visual tokens as a detection signal. We reveal that coarse-grained attention-based analysis is unreliable due to hidden confounders, specifically token position and object repetition in a description. This leads to Simpson's paradox: the attention trends reverse or disappear when statistics are aggregated. Based on this observation, we introduce HaloProbe, a Bayesian framework that factorizes external description statistics and internal decoding signals to estimate token-level hallucination probabilities. HaloProbe uses balanced training to isolate internal evidence and combines it with learned prior over external features to recover the true posterior. While intervention-based mitigation methods often degrade utility or fluency by modifying models' internals, we use HaloProbe as an external scoring signal for non-invasive mitigation. Our experiments show that HaloProbe-guided decoding reduces hallucinations more effectively than state-of-the-art intervention-based methods while preserving utility.
MEENA (PersianMMMU): Multimodal-Multilingual Educational Exams for N-level Assessment
Aug 24, 2025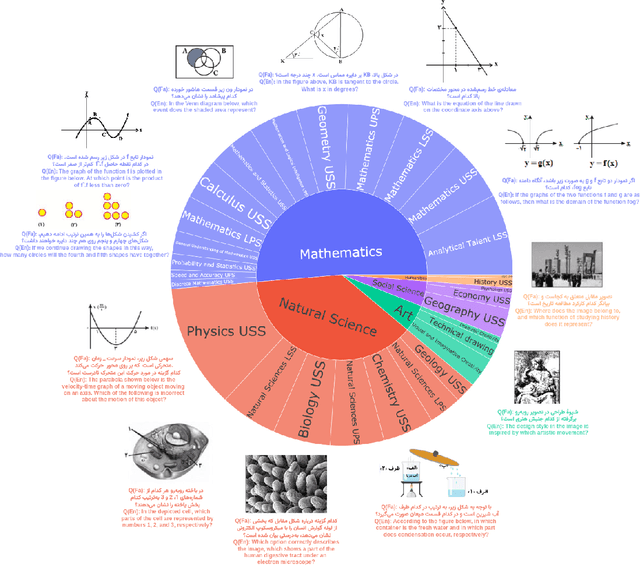

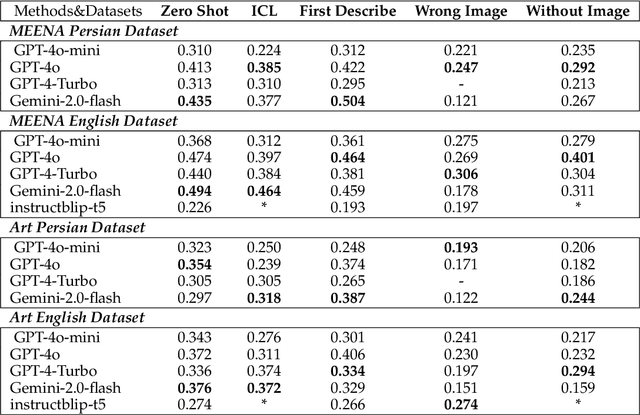
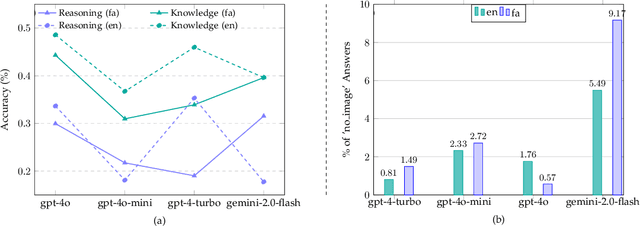
Recent advancements in large vision-language models (VLMs) have primarily focused on English, with limited attention given to other languages. To address this gap, we introduce MEENA (also known as PersianMMMU), the first dataset designed to evaluate Persian VLMs across scientific, reasoning, and human-level understanding tasks. Our dataset comprises approximately 7,500 Persian and 3,000 English questions, covering a wide range of topics such as reasoning, mathematics, physics, diagrams, charts, and Persian art and literature. Key features of MEENA include: (1) diverse subject coverage spanning various educational levels, from primary to upper secondary school, (2) rich metadata, including difficulty levels and descriptive answers, (3) original Persian data that preserves cultural nuances, (4) a bilingual structure to assess cross-linguistic performance, and (5) a series of diverse experiments assessing various capabilities, including overall performance, the model's ability to attend to images, and its tendency to generate hallucinations. We hope this benchmark contributes to enhancing VLM capabilities beyond English.
Spuriosity Rankings for Free: A Simple Framework for Last Layer Retraining Based on Object Detection
Oct 31, 2023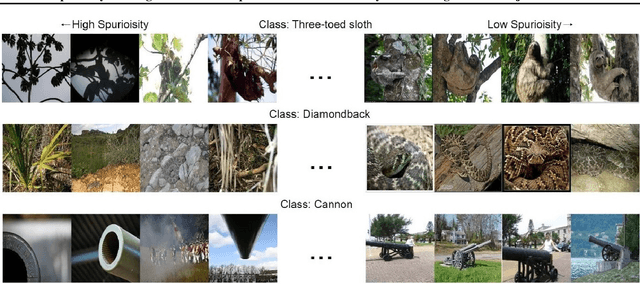

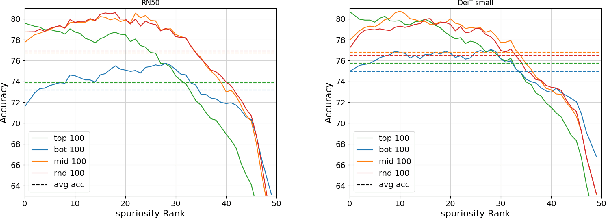
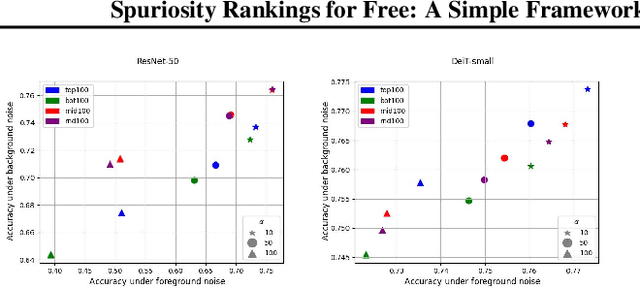
Deep neural networks have exhibited remarkable performance in various domains. However, the reliance of these models on spurious features has raised concerns about their reliability. A promising solution to this problem is last-layer retraining, which involves retraining the linear classifier head on a small subset of data without spurious cues. Nevertheless, selecting this subset requires human supervision, which reduces its scalability. Moreover, spurious cues may still exist in the selected subset. As a solution to this problem, we propose a novel ranking framework that leverages an open vocabulary object detection technique to identify images without spurious cues. More specifically, we use the object detector as a measure to score the presence of the target object in the images. Next, the images are sorted based on this score, and the last-layer of the model is retrained on a subset of the data with the highest scores. Our experiments on the ImageNet-1k dataset demonstrate the effectiveness of this ranking framework in sorting images based on spuriousness and using them for last-layer retraining.
Your Out-of-Distribution Detection Method is Not Robust!
Sep 30, 2022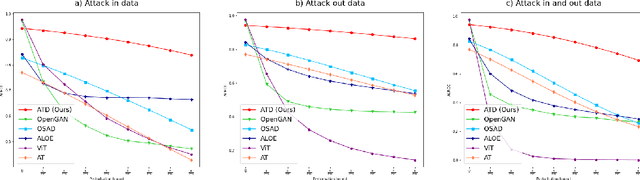
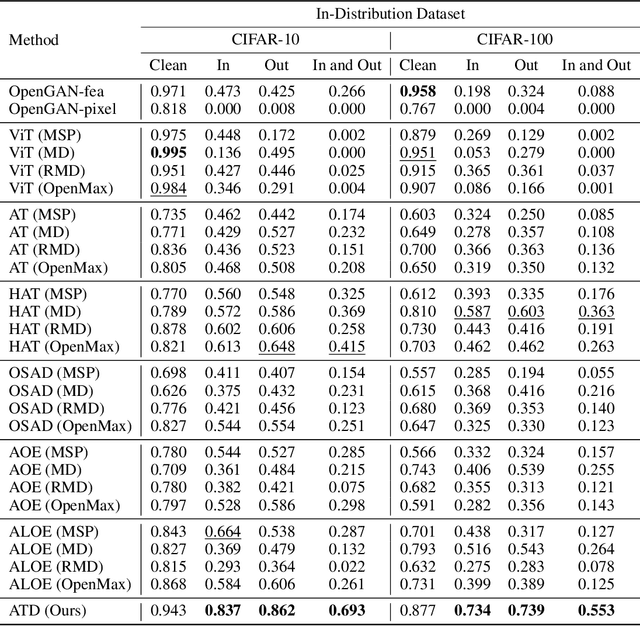
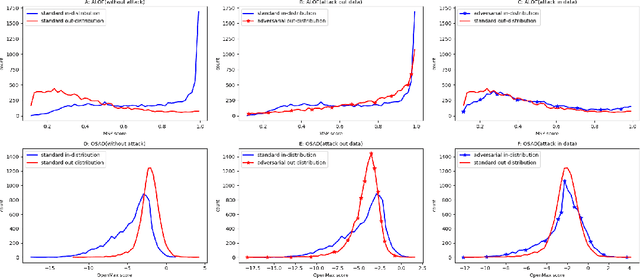

Out-of-distribution (OOD) detection has recently gained substantial attention due to the importance of identifying out-of-domain samples in reliability and safety. Although OOD detection methods have advanced by a great deal, they are still susceptible to adversarial examples, which is a violation of their purpose. To mitigate this issue, several defenses have recently been proposed. Nevertheless, these efforts remained ineffective, as their evaluations are based on either small perturbation sizes, or weak attacks. In this work, we re-examine these defenses against an end-to-end PGD attack on in/out data with larger perturbation sizes, e.g. up to commonly used $\epsilon=8/255$ for the CIFAR-10 dataset. Surprisingly, almost all of these defenses perform worse than a random detection under the adversarial setting. Next, we aim to provide a robust OOD detection method. In an ideal defense, the training should expose the model to almost all possible adversarial perturbations, which can be achieved through adversarial training. That is, such training perturbations should based on both in- and out-of-distribution samples. Therefore, unlike OOD detection in the standard setting, access to OOD, as well as in-distribution, samples sounds necessary in the adversarial training setup. These tips lead us to adopt generative OOD detection methods, such as OpenGAN, as a baseline. We subsequently propose the Adversarially Trained Discriminator (ATD), which utilizes a pre-trained robust model to extract robust features, and a generator model to create OOD samples. Using ATD with CIFAR-10 and CIFAR-100 as the in-distribution data, we could significantly outperform all previous methods in the robust AUROC while maintaining high standard AUROC and classification accuracy. The code repository is available at https://github.com/rohban-lab/ATD .