 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiking neural networks trained via proxy
Sep 27, 2021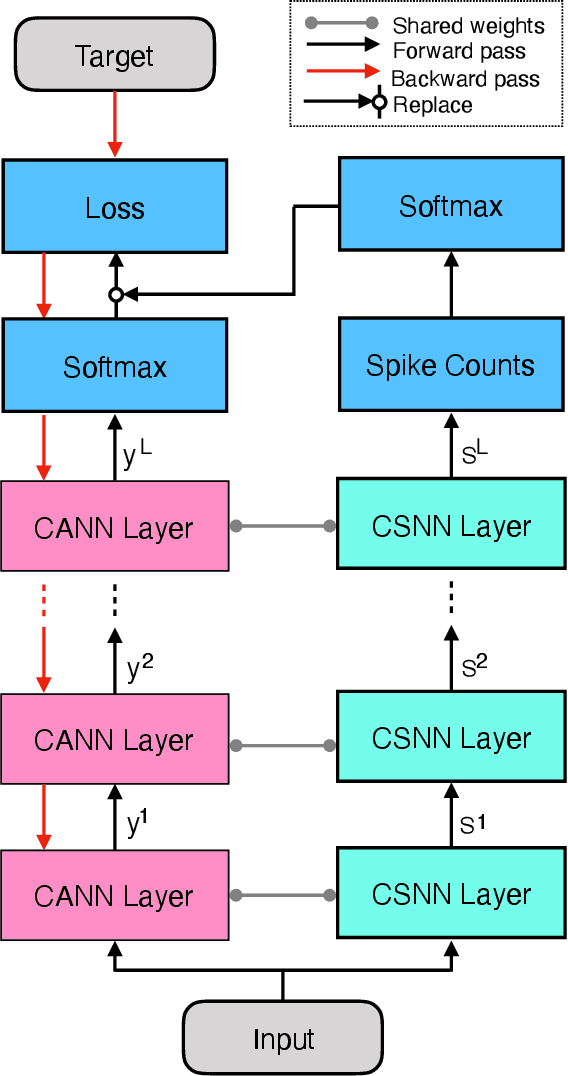

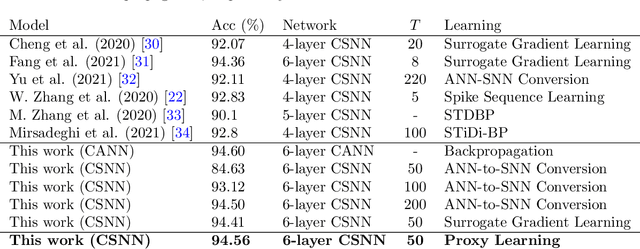

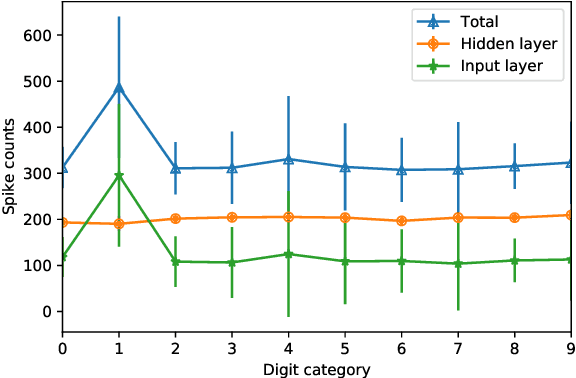
We propose a new learning algorithm to train spiking neural networks (SNN) using conventional artificial neural networks (ANN) as proxy. We couple two SNN and ANN networks, respectively, made of integrate-and-fire (IF) and ReLU neurons with the same network architectures and shared synaptic weights. The forward passes of the two networks are totally independent. By assuming IF neuron with rate-coding as an approximation of ReLU, we backpropagate the error of the SNN in the proxy ANN to update the shared weights, simply by replacing the ANN final output with that of the SNN. We applied the proposed proxy learning to deep convolutional SNNs and evaluated it on two benchmarked datasets of Fahion-MNIST and Cifar10 with 94.56% and 93.11% classification accuracy, respectively. The proposed networks could outperform other deep SNNs trained with tandem learning, surrogate gradient learning, or converted from deep ANNs. Converted SNNs require long simulation times to reach reasonable accuracies while our proxy learning leads to efficient SNNs with much shorter simulation times.
Spike time displacement based error backpropagation in convolutional spiking neural networks
Aug 31, 2021



We recently proposed the STiDi-BP algorithm, which avoids backward recursive gradient computation, for training multi-layer spiking neural networks (SNNs) with single-spike-based temporal coding. The algorithm employs a linear approximation to compute the derivative of the spike latency with respect to the membrane potential and it uses spiking neurons with piecewise linear postsynaptic potential to reduce the computational cost and the complexity of neural processing. In this paper, we extend the STiDi-BP algorithm to employ it in deeper and convolutional architectures. The evaluation results on the image classification task based on two popular benchmarks, MNIST and Fashion-MNIST datasets with the accuracies of respectively 99.2% and 92.8%, confirm that this algorithm has been applicable in deep SNNs. Another issue we consider is the reduction of memory storage and computational cost. To do so, we consider a convolutional SNN (CSNN) with two sets of weights: real-valued weights that are updated in the backward pass and their signs, binary weights, that are employed in the feedforward process. We evaluate the binary CSNN on two datasets of MNIST and Fashion-MNIST and obtain acceptable performance with a negligible accuracy drop with respect to real-valued weights (about $0.6%$ and $0.8%$ drops, respectively).
BS4NN: Binarized Spiking Neural Networks with Temporal Coding and Learning
Jul 08, 2020


We recently proposed the S4NN algorithm, essentially an adaptation of backpropagation to multilayer spiking neural networks that use simple non-leaky integrate-and-fire neurons and a form of temporal coding known as time-to-first-spike coding. With this coding scheme, neurons fire at most once per stimulus, but the firing order carries information. Here, we introduce BS4NN, a modification of S4NN in which the synaptic weights are constrained to be binary (+1 or -1), in order to decrease memory and computation footprints. This was done using two sets of weights: firstly, real-valued weights, updated by gradient descent, and used in the backward pass of backpropagation, and secondly, their signs, used in the forward pass. Similar strategies have been used to train (non-spiking) binarized neural networks. The main difference is that BS4NN operates in the time domain: spikes are propagated sequentially, and different neurons may reach their threshold at different times, which increases computational power. We validated BS4NN on two popular benchmarks, MNIST and Fashion MNIST, and obtained state-of-the-art accuracies for this sort of networks (97.0% and 87.3% respectively) with a negligible accuracy drop with respect to real-valued weights (0.4% and 0.7%, respectively). We also demonstrated that BS4NN outperforms a simple BNN with the same architectures on those two datasets (by 0.2% and 0.9% respectively), presumably because it leverages the temporal dimension.