 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Contrastive Vision-Language Learning with Predictive Embedding Alignment
Jan 31, 2026Vision-language models have transformed multimodal representation learning, yet dominant contrastive approaches like CLIP require large batch sizes, careful negative sampling, and extensive hyperparameter tuning. We introduce NOVA, a NOn-contrastive Vision-language Alignment framework based on joint embedding prediction with distributional regularization. NOVA aligns visual representations to a frozen, domain-specific text encoder by predicting text embeddings from augmented image views, while enforcing an isotropic Gaussian structure via Sketched Isotropic Gaussian Regularization (SIGReg). This eliminates the need for negative sampling, momentum encoders, or stop-gradients, reducing the training objective to a single hyperparameter. We evaluate NOVA on zeroshot chest X-ray classification using ClinicalBERT as the text encoder and Vision Transformers trained from scratch on MIMIC-CXR. On zero-shot classification across three benchmark datasets, NOVA outperforms multiple standard baselines while exhibiting substantially more consistent training runs. Our results demonstrate that non-contrastive vision-language pretraining offers a simpler, more stable, and more effective alternative to contrastive methods.
LVLM-Aided Alignment of Task-Specific Vision Models
Dec 26, 2025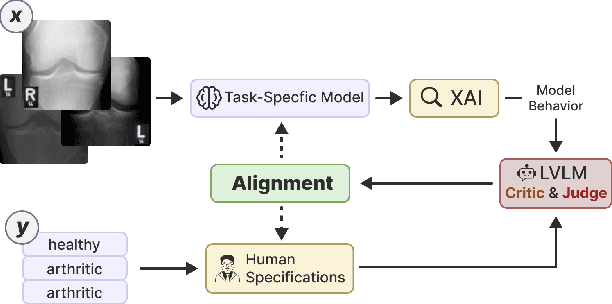
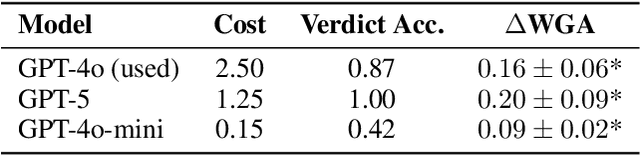
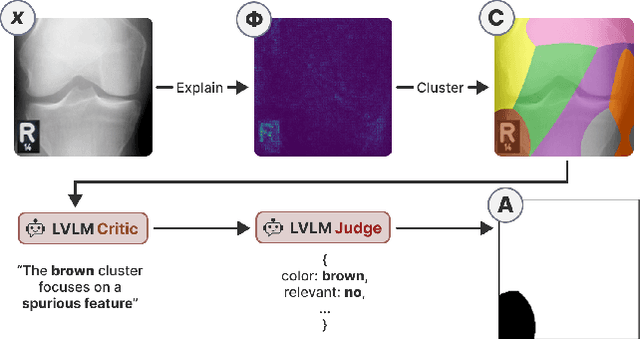

In high-stakes domains, small task-specific vision models are crucial due to their low computational requirements and the availability of numerous methods to explain their results. However, these explanations often reveal that the models do not align well with human domain knowledge, relying instead on spurious correlations. This might result in brittle behavior once deployed in the real-world. To address this issue, we introduce a novel and efficient method for aligning small task-specific vision models with human domain knowledge by leveraging the generalization capabilities of a Large Vision Language Model (LVLM). Our LVLM-Aided Visual Alignment (LVLM-VA) method provides a bidirectional interface that translates model behavior into natural language and maps human class-level specifications to image-level critiques, enabling effective interaction between domain experts and the model. Our method demonstrates substantial improvement in aligning model behavior with human specifications, as validated on both synthetic and real-world datasets. We show that it effectively reduces the model's dependence on spurious features and on group-specific biases, without requiring fine-grained feedback.
Beyond Overconfidence: Foundation Models Redefine Calibration in Deep Neural Networks
Jun 11, 2025Reliable uncertainty calibration is essential for safely deploying deep neural networks in high-stakes applications. Deep neural networks are known to exhibit systematic overconfidence, especially under distribution shifts. Although foundation models such as ConvNeXt, EVA and BEiT have demonstrated significant improvements in predictive performance, their calibration properties remain underexplored. This paper presents a comprehensive investigation into the calibration behavior of foundation models, revealing insights that challenge established paradigms. Our empirical analysis shows that these models tend to be underconfident in in-distribution predictions, resulting in higher calibration errors, while demonstrating improved calibration under distribution shifts. Furthermore, we demonstrate that foundation models are highly responsive to post-hoc calibration techniques in the in-distribution setting, enabling practitioners to effectively mitigate underconfidence bias. However, these methods become progressively less reliable under severe distribution shifts and can occasionally produce counterproductive results. Our findings highlight the complex, non-monotonic effects of architectural and training innovations on calibration, challenging established narratives of continuous improvement.
Efficient Unsupervised Shortcut Learning Detection and Mitigation in Transformers
Jan 01, 2025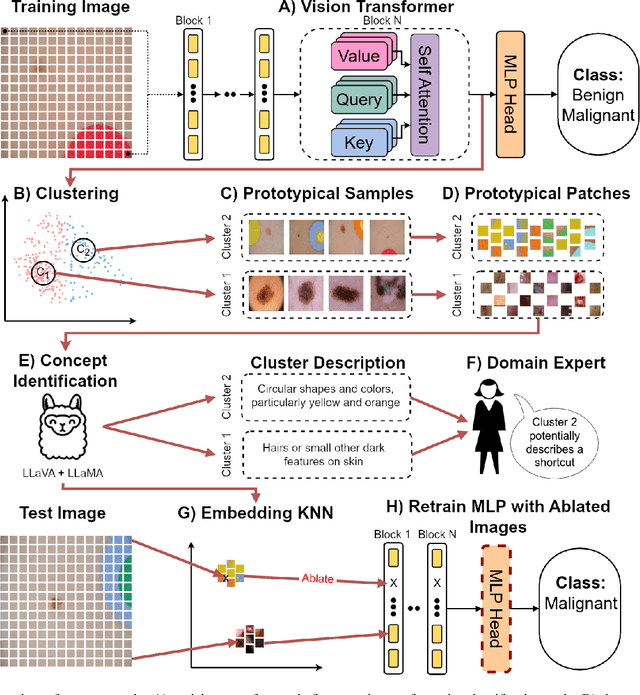
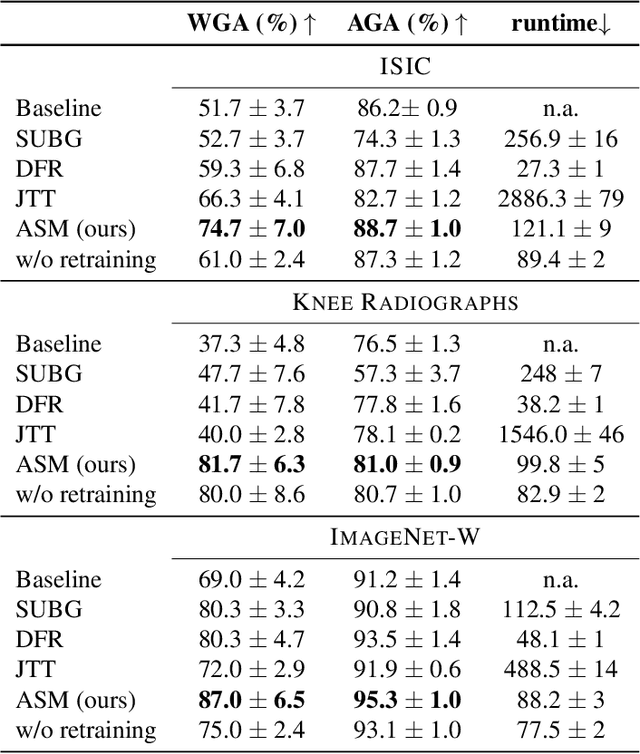


Shortcut learning, i.e., a model's reliance on undesired features not directly relevant to the task, is a major challenge that severely limits the applications of machine learning algorithms, particularly when deploying them to assist in making sensitive decisions, such as in medical diagnostics. In this work, we leverage recent advancements in machine learning to create an unsupervised framework that is capable of both detecting and mitigating shortcut learning in transformers. We validate our method on multiple datasets. Results demonstrate that our framework significantly improves both worst-group accuracy (samples misclassified due to shortcuts) and average accuracy, while minimizing human annotation effort. Moreover, we demonstrate that the detected shortcuts are meaningful and informative to human experts, and that our framework is computationally efficient, allowing it to be run on consumer hardware.