 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARTIME: Scalable and Parallel Processing Over Time with Deep Neural Networks
Oct 17, 2022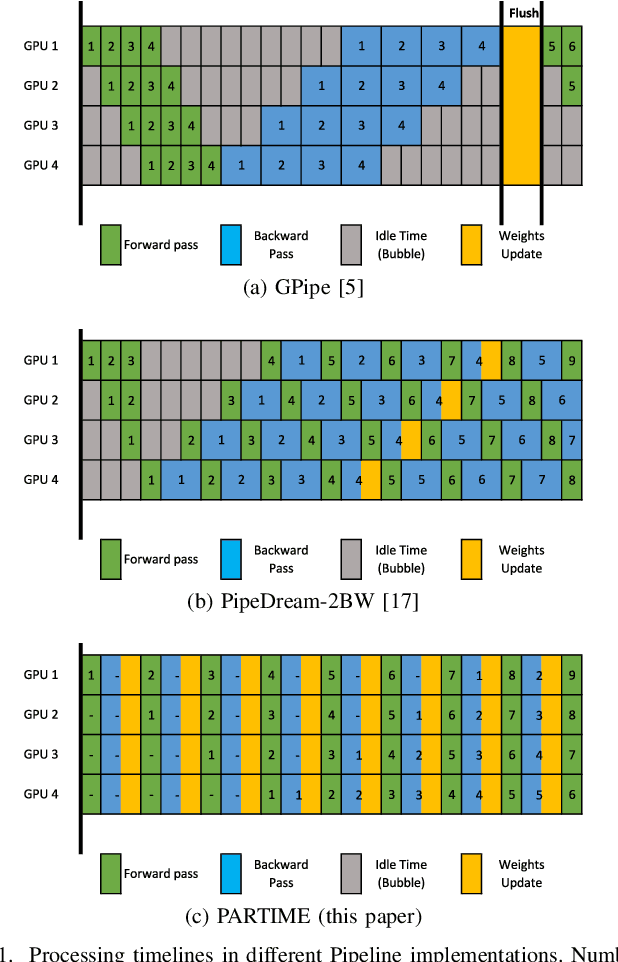


In this paper, we present PARTIME, a software library written in Python and based on PyTorch, designed specifically to speed up neural networks whenever data is continuously streamed over time, for both learning and inference. Existing libraries are designed to exploit data-level parallelism, assuming that samples are batched, a condition that is not naturally met in applications that are based on streamed data. Differently, PARTIME starts processing each data sample at the time in which it becomes available from the stream. PARTIME wraps the code that implements a feed-forward multi-layer network and it distributes the layer-wise processing among multiple devices, such as Graphics Processing Units (GPUs). Thanks to its pipeline-based computational scheme, PARTIME allows the devices to perform computations in parallel. At inference time this results in scaling capabilities that are theoretically linear with respect to the number of devices. During the learning stage, PARTIME can leverage the non-i.i.d. nature of the streamed data with samples that are smoothly evolving over time for efficient gradient computations. Experiments are performed in order to empirically compare PARTIME with classic non-parallel neural computations in online learning, distributing operations on up to 8 NVIDIA GPUs, showing significant speedups that are almost linear in the number of devices, mitigating the impact of the data transfer overhead.
Stochastic Coherence Over Attention Trajectory For Continuous Learning In Video Streams
Apr 26, 2022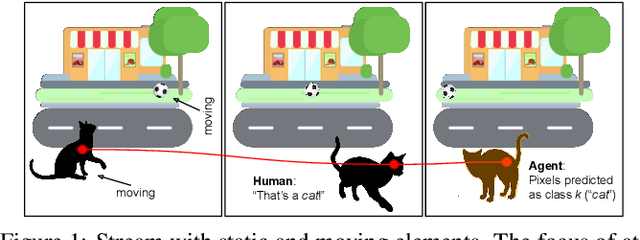
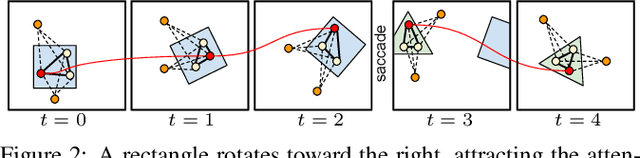
Devising intelligent agents able to live in an environment and learn by observing the surroundings is a longstanding goal of Artificial Intelligence. From a bare Machine Learning perspective, challenges arise when the agent is prevented from leveraging large fully-annotated dataset, but rather the interactions with supervisory signals are sparsely distributed over space and time. This paper proposes a novel neural-network-based approach to progressively and autonomously develop pixel-wise representations in a video stream. The proposed method is based on a human-like attention mechanism that allows the agent to learn by observing what is moving in the attended locations. Spatio-temporal stochastic coherence along the attention trajectory, paired with a contrastive term, leads to an unsupervised learning criterion that naturally copes with the considered setting. Differently from most existing works, the learned representations are used in open-set class-incremental classification of each frame pixel, relying on few supervisions. Our experiments leverage 3D virtual environments and they show that the proposed agents can learn to distinguish objects just by observing the video stream. Inheriting features from state-of-the art models is not as powerful as one might expect.
Messing Up 3D Virtual Environments: Transferable Adversarial 3D Objects
Sep 17, 2021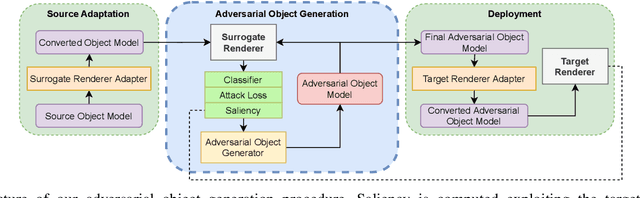



In the last few years, the scientific community showed a remarkable and increasing interest towards 3D Virtual Environments, training and testing Machine Learning-based models in realistic virtual worlds. On one hand, these environments could also become a mean to study the weaknesses of Machine Learning algorithms, or to simulate training settings that allow Machine Learning models to gain robustness to 3D adversarial attacks. On the other hand, their growing popularity might also attract those that aim at creating adversarial conditions to invalidate the benchmarking process, especially in the case of public environments that allow the contribution from a large community of people. Most of the existing Adversarial Machine Learning approaches are focused on static images, and little work has been done in studying how to deal with 3D environments and how a 3D object should be altered to fool a classifier that observes it. In this paper, we study how to craft adversarial 3D objects by altering their textures, using a tool chain composed of easily accessible elements. We show that it is possible, and indeed simple, to create adversarial objects using off-the-shelf limited surrogate renderers that can compute gradients with respect to the parameters of the rendering process, and, to a certain extent, to transfer the attacks to more advanced 3D engines. We propose a saliency-based attack that intersects the two classes of renderers in order to focus the alteration to those texture elements that are estimated to be effective in the target engine, evaluating its impact in popular neural classifiers.
Evaluating Continual Learning Algorithms by Generating 3D Virtual Environments
Sep 16, 2021



Continual learning refers to the ability of humans and animals to incrementally learn over time in a given environment. Trying to simulate this learning process in machines is a challenging task, also due to the inherent difficulty in creating conditions for designing continuously evolving dynamics that are typical of the real-world. Many existing research works usually involve training and testing of virtual agents on datasets of static images or short videos, considering sequences of distinct learning tasks. However, in order to devise continual learning algorithms that operate in more realistic conditions, it is fundamental to gain access to rich, fully customizable and controlled experimental playgrounds. Focussing on the specific case of vision, we thus propose to leverage recent advances in 3D virtual environments in order to approach the automatic generation of potentially life-long dynamic scenes with photo-realistic appearance. Scenes are composed of objects that move along variable routes with different and fully customizable timings, and randomness can also be included in their evolution. A novel element of this paper is that scenes are described in a parametric way, thus allowing the user to fully control the visual complexity of the input stream the agent perceives. These general principles are concretely implemented exploiting a recently published 3D virtual environment. The user can generate scenes without the need of having strong skills in computer graphics, since all the generation facilities are exposed through a simple high-level Python interface. We publicly share the proposed generator.
An Optimal Control Approach to Learning in SIDARTHE Epidemic model
Oct 28, 2020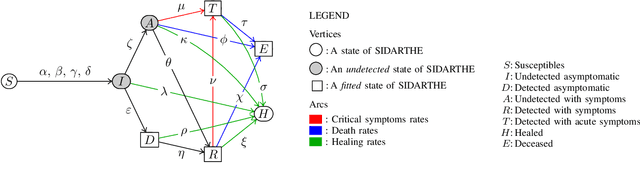
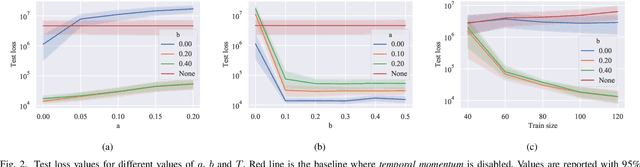
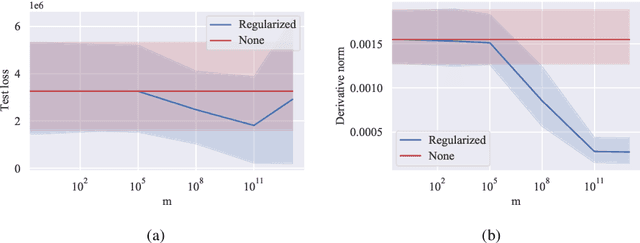
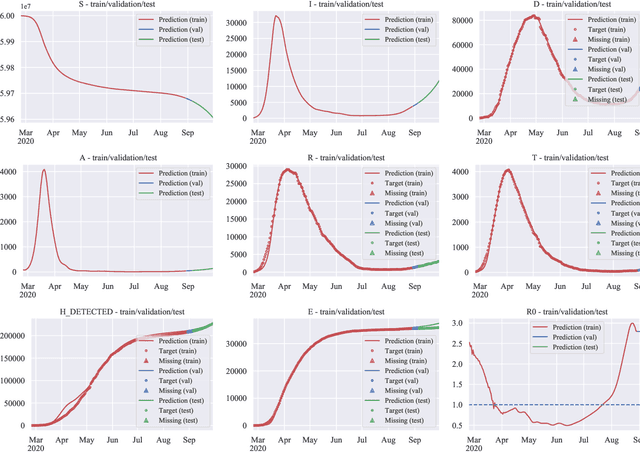
The COVID-19 outbreak has stimulated the interest in the proposal of novel epidemiological models to predict the course of the epidemic so as to help planning effective control strategies. In particular, in order to properly interpret the available data, it has become clear that one must go beyond most classic epidemiological models and consider models that, like the recently proposed SIDARTHE, offer a richer description of the stages of infection. The problem of learning the parameters of these models is of crucial importance especially when assuming that they are time-variant, which further enriches their effectiveness. In this paper we propose a general approach for learning time-variant parameters of dynamic compartmental models from epidemic data. We formulate the problem in terms of a functional risk that depends on the learning variables through the solutions of a dynamic system. The resulting variational problem is then solved by using a gradient flow on a suitable, regularized functional. We forecast the epidemic evolution in Italy and France. Results indicate that the model provides reliable and challenging predictions over all available data as well as the fundamental role of the chosen strategy on the time-variant parameters.
SAILenv: Learning in Virtual Visual Environments Made Simple
Jul 20, 2020
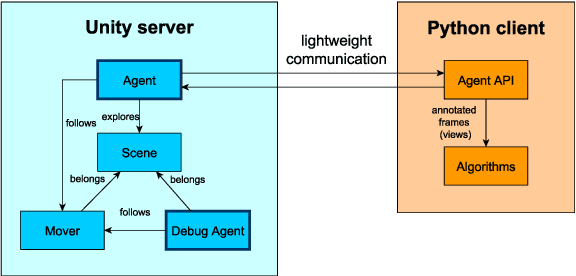


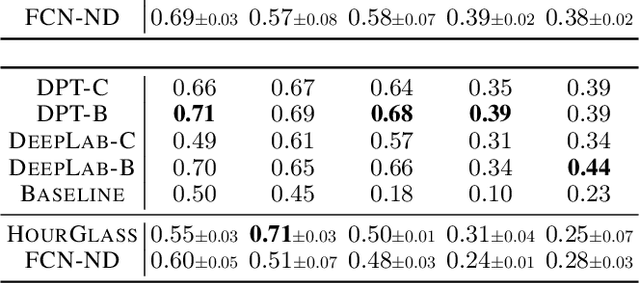
Recently, researchers in Machine Learning algorithms, Computer Vision scientists, engineers and others, showed a growing interest in 3D simulators as a mean to artificially create experimental settings that are very close to those in the real world. However, most of the existing platforms to interface algorithms with 3D environments are often designed to setup navigation-related experiments, to study physical interactions, or to handle ad-hoc cases that are not thought to be customized, sometimes lacking a strong photorealistic appearance and an easy-to-use software interface. In this paper, we present a novel platform, SAILenv, that is specifically designed to be simple and customizable, and that allows researchers to experiment visual recognition in virtual 3D scenes. A few lines of code are needed to interface every algorithm with the virtual world, and non-3D-graphics experts can easily customize the 3D environment itself, exploiting a collection of photorealistic objects. Our framework yields pixel-level semantic and instance labeling, depth, and, to the best of our knowledge, it is the only one that provides motion-related information directly inherited from the 3D engine. The client-server communication operates at a low level, avoiding the overhead of HTTP-based data exchanges. We perform experiments using a state-of-the-art object detector trained on real-world images, showing that it is able to recognize the photorealistic 3D objects of our environment. The computational burden of the optical flow compares favourably with the estimation performed using modern GPU-based convolutional networks or more classic implementations. We believe that the scientific community will benefit from the easiness and high-quality of our framework to evaluate newly proposed algorithms in their own customized realistic conditions.