 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Fine-Grained Semantic Segmentations in Low Data Regimes: A FungiTastic Baseline
May 21, 2026Fine-grained semantic segmentation requires both precise localization and discrimination between visually similar classes. In FungiTastic, this problem is further complicated by a long-tailed distribution and strong variation in image acquisition conditions. We propose a training-free two-stage framework that decouples segmentation from classification. SAM3 first produces class-agnostic mushroom masks using macro-taxonomic prompts, and DINOv3 then assigns fine-grained labels through prototype matching in the embedding space. To improve this stage, we apply a simple transformation of the DINOv3 feature space that improves prototype-based classification. Compared with class-specific prompting, our approach is more scalable and keeps the segmentation cost low. We report results from one-shot to few-hundred-shot regimes, providing, to the best of our knowledge, the first baseline for fine-grained semantic segmentation in low-data settings.
PARTIME: Scalable and Parallel Processing Over Time with Deep Neural Networks
Oct 17, 2022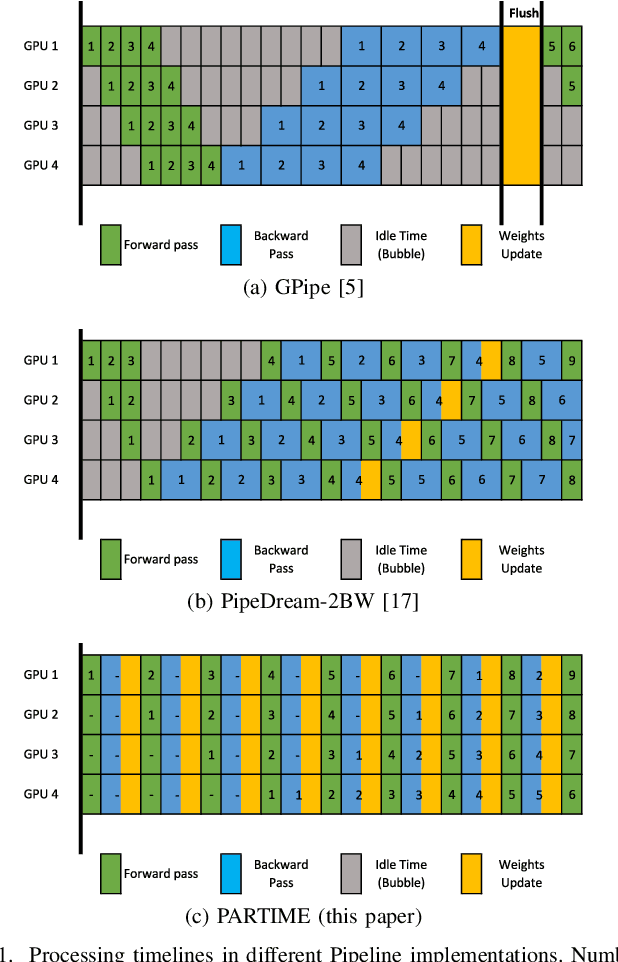


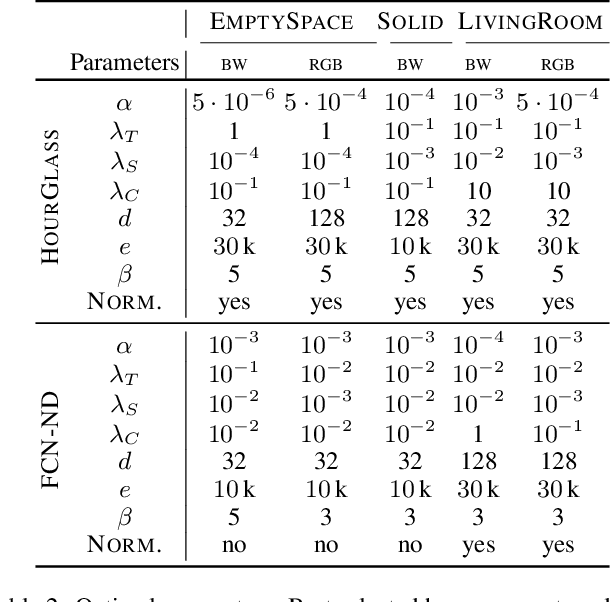
In this paper, we present PARTIME, a software library written in Python and based on PyTorch, designed specifically to speed up neural networks whenever data is continuously streamed over time, for both learning and inference. Existing libraries are designed to exploit data-level parallelism, assuming that samples are batched, a condition that is not naturally met in applications that are based on streamed data. Differently, PARTIME starts processing each data sample at the time in which it becomes available from the stream. PARTIME wraps the code that implements a feed-forward multi-layer network and it distributes the layer-wise processing among multiple devices, such as Graphics Processing Units (GPUs). Thanks to its pipeline-based computational scheme, PARTIME allows the devices to perform computations in parallel. At inference time this results in scaling capabilities that are theoretically linear with respect to the number of devices. During the learning stage, PARTIME can leverage the non-i.i.d. nature of the streamed data with samples that are smoothly evolving over time for efficient gradient computations. Experiments are performed in order to empirically compare PARTIME with classic non-parallel neural computations in online learning, distributing operations on up to 8 NVIDIA GPUs, showing significant speedups that are almost linear in the number of devices, mitigating the impact of the data transfer overhead.
Stochastic Coherence Over Attention Trajectory For Continuous Learning In Video Streams
Apr 26, 2022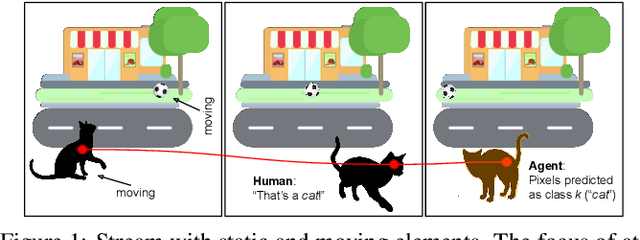
Devising intelligent agents able to live in an environment and learn by observing the surroundings is a longstanding goal of Artificial Intelligence. From a bare Machine Learning perspective, challenges arise when the agent is prevented from leveraging large fully-annotated dataset, but rather the interactions with supervisory signals are sparsely distributed over space and time. This paper proposes a novel neural-network-based approach to progressively and autonomously develop pixel-wise representations in a video stream. The proposed method is based on a human-like attention mechanism that allows the agent to learn by observing what is moving in the attended locations. Spatio-temporal stochastic coherence along the attention trajectory, paired with a contrastive term, leads to an unsupervised learning criterion that naturally copes with the considered setting. Differently from most existing works, the learned representations are used in open-set class-incremental classification of each frame pixel, relying on few supervisions. Our experiments leverage 3D virtual environments and they show that the proposed agents can learn to distinguish objects just by observing the video stream. Inheriting features from state-of-the art models is not as powerful as one might expect.
Evaluating Continual Learning Algorithms by Generating 3D Virtual Environments
Sep 16, 2021



Continual learning refers to the ability of humans and animals to incrementally learn over time in a given environment. Trying to simulate this learning process in machines is a challenging task, also due to the inherent difficulty in creating conditions for designing continuously evolving dynamics that are typical of the real-world. Many existing research works usually involve training and testing of virtual agents on datasets of static images or short videos, considering sequences of distinct learning tasks. However, in order to devise continual learning algorithms that operate in more realistic conditions, it is fundamental to gain access to rich, fully customizable and controlled experimental playgrounds. Focussing on the specific case of vision, we thus propose to leverage recent advances in 3D virtual environments in order to approach the automatic generation of potentially life-long dynamic scenes with photo-realistic appearance. Scenes are composed of objects that move along variable routes with different and fully customizable timings, and randomness can also be included in their evolution. A novel element of this paper is that scenes are described in a parametric way, thus allowing the user to fully control the visual complexity of the input stream the agent perceives. These general principles are concretely implemented exploiting a recently published 3D virtual environment. The user can generate scenes without the need of having strong skills in computer graphics, since all the generation facilities are exposed through a simple high-level Python interface. We publicly share the proposed generator.
Wave Propagation of Visual Stimuli in Focus of Attention
Jun 19, 2020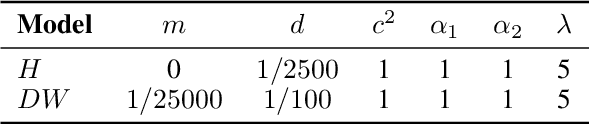

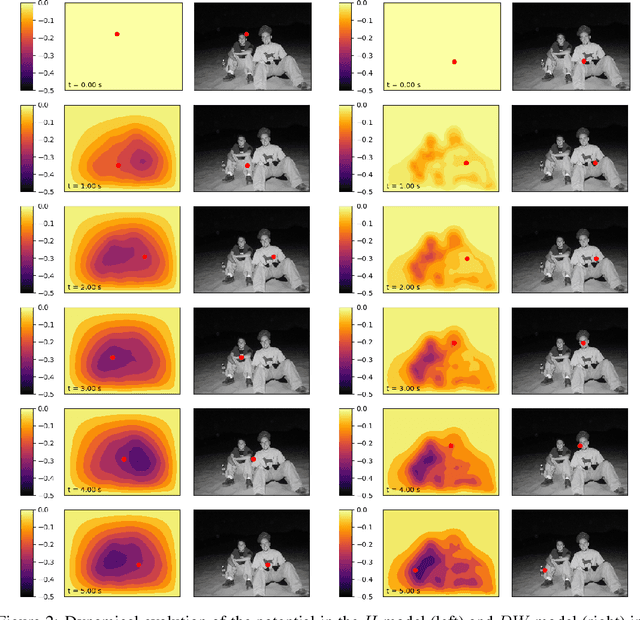
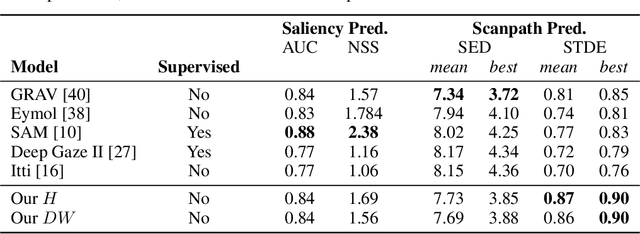
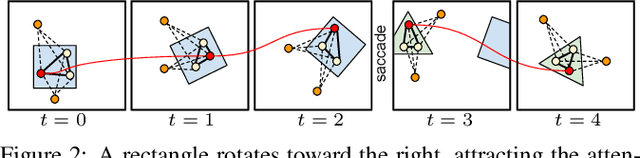
Fast reactions to changes in the surrounding visual environment require efficient attention mechanisms to reallocate computational resources to most relevant locations in the visual field. While current computational models keep improving their predictive ability thanks to the increasing availability of data, they still struggle approximating the effectiveness and efficiency exhibited by foveated animals. In this paper, we present a biologically-plausible computational model of focus of attention that exhibits spatiotemporal locality and that is very well-suited for parallel and distributed implementations. Attention emerges as a wave propagation process originated by visual stimuli corresponding to details and motion information. The resulting field obeys the principle of "inhibition of return" so as not to get stuck in potential holes. An accurate experimentation of the model shows that it achieves top level performance in scanpath prediction tasks. This can easily be understood at the light of a theoretical result that we establish in the paper, where we prove that as the velocity of wave propagation goes to infinity, the proposed model reduces to recently proposed state of the art gravitational models of focus of attention.