 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning of Conjugated Visual Representations through Higher-order Motion Flows
Sep 16, 2024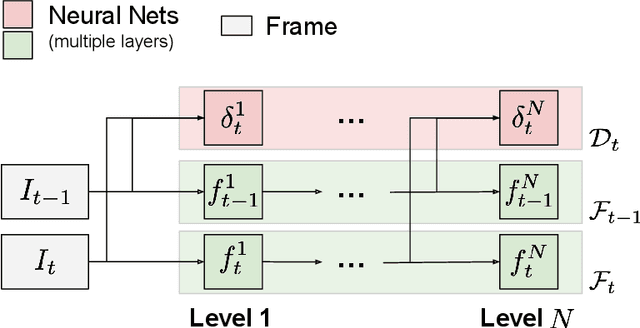
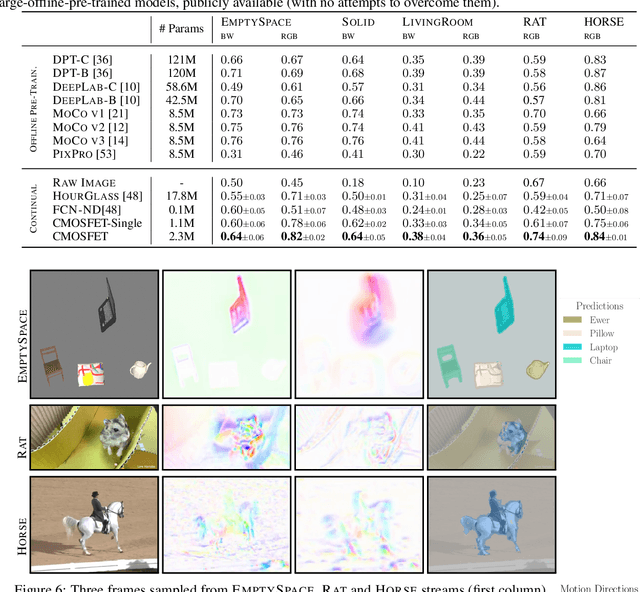
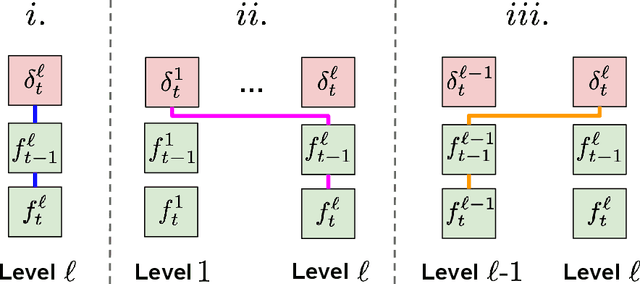

Learning with neural networks from a continuous stream of visual information presents several challenges due to the non-i.i.d. nature of the data. However, it also offers novel opportunities to develop representations that are consistent with the information flow. In this paper we investigate the case of unsupervised continual learning of pixel-wise features subject to multiple motion-induced constraints, therefore named motion-conjugated feature representations. Differently from existing approaches, motion is not a given signal (either ground-truth or estimated by external modules), but is the outcome of a progressive and autonomous learning process, occurring at various levels of the feature hierarchy. Multiple motion flows are estimated with neural networks and characterized by different levels of abstractions, spanning from traditional optical flow to other latent signals originating from higher-level features, hence called higher-order motions. Continuously learning to develop consistent multi-order flows and representations is prone to trivial solutions, which we counteract by introducing a self-supervised contrastive loss, spatially-aware and based on flow-induced similarity. We assess our model on photorealistic synthetic streams and real-world videos, comparing to pre-trained state-of-the art feature extractors (also based on Transformers) and to recent unsupervised learning models, significantly outperforming these alternatives.
Neural Time-Reversed Generalized Riccati Equation
Dec 14, 2023


Optimal control deals with optimization problems in which variables steer a dynamical system, and its outcome contributes to the objective function. Two classical approaches to solving these problems are Dynamic Programming and the Pontryagin Maximum Principle. In both approaches, Hamiltonian equations offer an interpretation of optimality through auxiliary variables known as costates. However, Hamiltonian equations are rarely used due to their reliance on forward-backward algorithms across the entire temporal domain. This paper introduces a novel neural-based approach to optimal control, with the aim of working forward-in-time. Neural networks are employed not only for implementing state dynamics but also for estimating costate variables. The parameters of the latter network are determined at each time step using a newly introduced local policy referred to as the time-reversed generalized Riccati equation. This policy is inspired by a result discussed in the Linear Quadratic (LQ) problem, which we conjecture stabilizes state dynamics. We support this conjecture by discussing experimental results from a range of optimal control case studies.
Continual Learning with Pretrained Backbones by Tuning in the Input Space
Jun 08, 2023The intrinsic difficulty in adapting deep learning models to non-stationary environments limits the applicability of neural networks to real-world tasks. This issue is critical in practical supervised learning settings, such as the ones in which a pre-trained model computes projections toward a latent space where different task predictors are sequentially learned over time. As a matter of fact, incrementally fine-tuning the whole model to better adapt to new tasks usually results in catastrophic forgetting, with decreasing performance over the past experiences and losing valuable knowledge from the pre-training stage. In this paper, we propose a novel strategy to make the fine-tuning procedure more effective, by avoiding to update the pre-trained part of the network and learning not only the usual classification head, but also a set of newly-introduced learnable parameters that are responsible for transforming the input data. This process allows the network to effectively leverage the pre-training knowledge and find a good trade-off between plasticity and stability with modest computational efforts, thus especially suitable for on-the-edge settings. Our experiments on four image classification problems in a continual learning setting confirm the quality of the proposed approach when compared to several fine-tuning procedures and to popular continual learning methods.
PARTIME: Scalable and Parallel Processing Over Time with Deep Neural Networks
Oct 17, 2022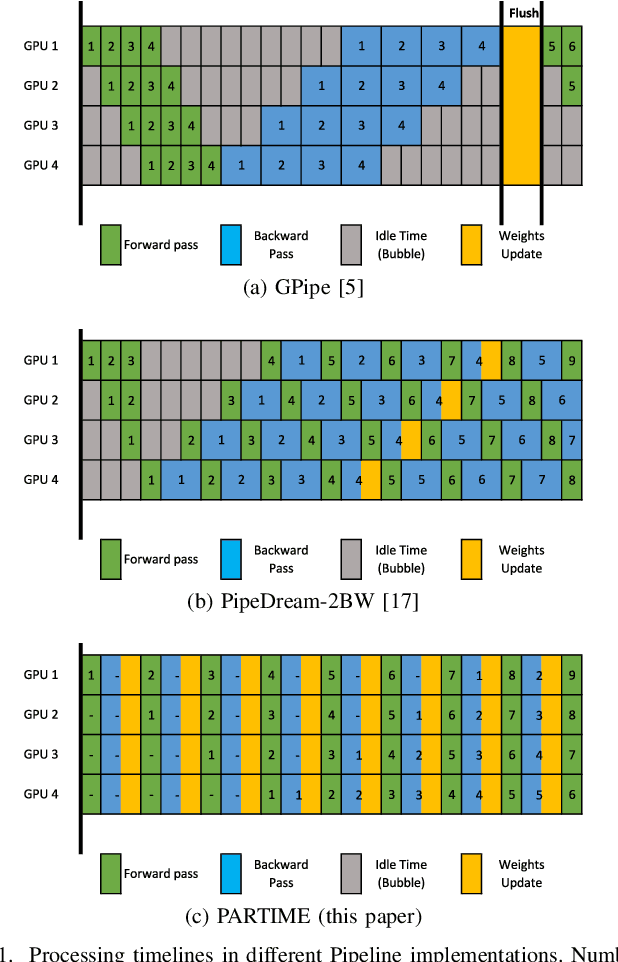

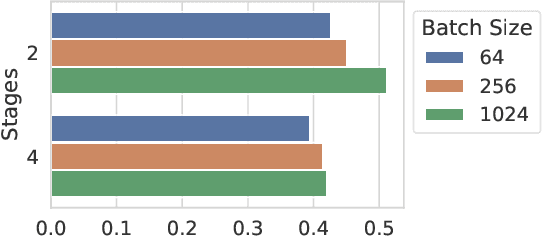

In this paper, we present PARTIME, a software library written in Python and based on PyTorch, designed specifically to speed up neural networks whenever data is continuously streamed over time, for both learning and inference. Existing libraries are designed to exploit data-level parallelism, assuming that samples are batched, a condition that is not naturally met in applications that are based on streamed data. Differently, PARTIME starts processing each data sample at the time in which it becomes available from the stream. PARTIME wraps the code that implements a feed-forward multi-layer network and it distributes the layer-wise processing among multiple devices, such as Graphics Processing Units (GPUs). Thanks to its pipeline-based computational scheme, PARTIME allows the devices to perform computations in parallel. At inference time this results in scaling capabilities that are theoretically linear with respect to the number of devices. During the learning stage, PARTIME can leverage the non-i.i.d. nature of the streamed data with samples that are smoothly evolving over time for efficient gradient computations. Experiments are performed in order to empirically compare PARTIME with classic non-parallel neural computations in online learning, distributing operations on up to 8 NVIDIA GPUs, showing significant speedups that are almost linear in the number of devices, mitigating the impact of the data transfer overhead.
Stochastic Coherence Over Attention Trajectory For Continuous Learning In Video Streams
Apr 26, 2022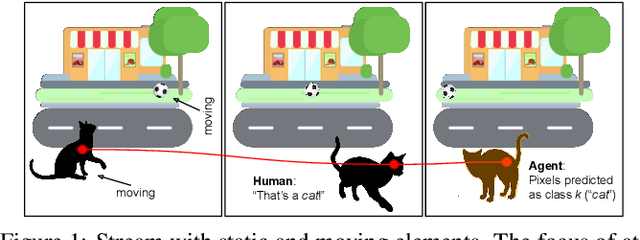
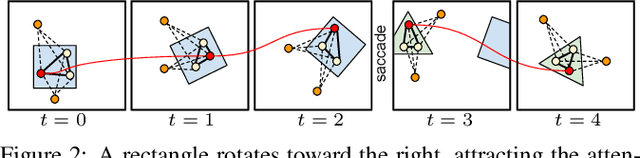
Devising intelligent agents able to live in an environment and learn by observing the surroundings is a longstanding goal of Artificial Intelligence. From a bare Machine Learning perspective, challenges arise when the agent is prevented from leveraging large fully-annotated dataset, but rather the interactions with supervisory signals are sparsely distributed over space and time. This paper proposes a novel neural-network-based approach to progressively and autonomously develop pixel-wise representations in a video stream. The proposed method is based on a human-like attention mechanism that allows the agent to learn by observing what is moving in the attended locations. Spatio-temporal stochastic coherence along the attention trajectory, paired with a contrastive term, leads to an unsupervised learning criterion that naturally copes with the considered setting. Differently from most existing works, the learned representations are used in open-set class-incremental classification of each frame pixel, relying on few supervisions. Our experiments leverage 3D virtual environments and they show that the proposed agents can learn to distinguish objects just by observing the video stream. Inheriting features from state-of-the art models is not as powerful as one might expect.
Being Friends Instead of Adversaries: Deep Networks Learn from Data Simplified by Other Networks
Dec 18, 2021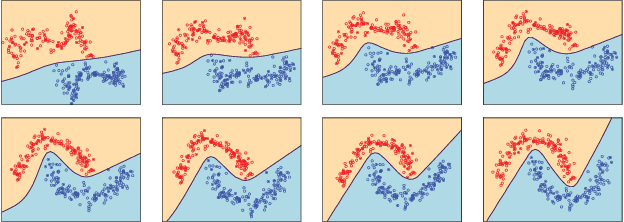
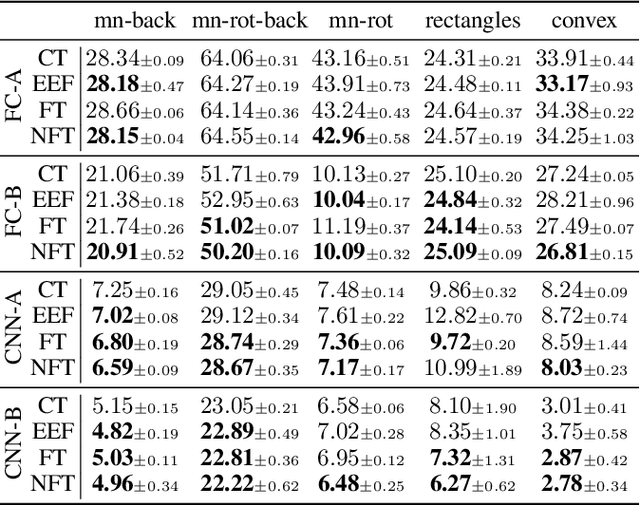
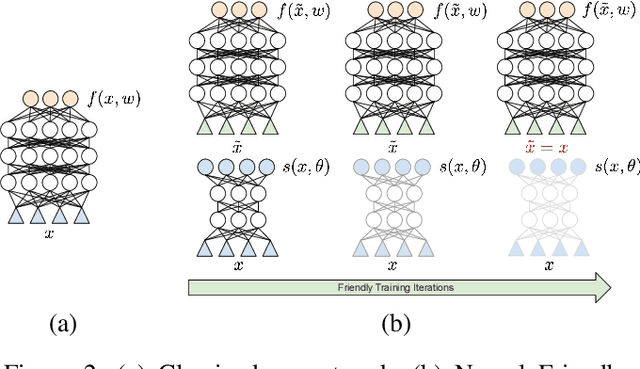

Amongst a variety of approaches aimed at making the learning procedure of neural networks more effective, the scientific community developed strategies to order the examples according to their estimated complexity, to distil knowledge from larger networks, or to exploit the principles behind adversarial machine learning. A different idea has been recently proposed, named Friendly Training, which consists in altering the input data by adding an automatically estimated perturbation, with the goal of facilitating the learning process of a neural classifier. The transformation progressively fades-out as long as training proceeds, until it completely vanishes. In this work we revisit and extend this idea, introducing a radically different and novel approach inspired by the effectiveness of neural generators in the context of Adversarial Machine Learning. We propose an auxiliary multi-layer network that is responsible of altering the input data to make them easier to be handled by the classifier at the current stage of the training procedure. The auxiliary network is trained jointly with the neural classifier, thus intrinsically increasing the 'depth' of the classifier, and it is expected to spot general regularities in the data alteration process. The effect of the auxiliary network is progressively reduced up to the end of training, when it is fully dropped and the classifier is deployed for applications. We refer to this approach as Neural Friendly Training. An extended experimental procedure involving several datasets and different neural architectures shows that Neural Friendly Training overcomes the originally proposed Friendly Training technique, improving the generalization of the classifier, especially in the case of noisy data.
Evaluating Continual Learning Algorithms by Generating 3D Virtual Environments
Sep 16, 2021



Continual learning refers to the ability of humans and animals to incrementally learn over time in a given environment. Trying to simulate this learning process in machines is a challenging task, also due to the inherent difficulty in creating conditions for designing continuously evolving dynamics that are typical of the real-world. Many existing research works usually involve training and testing of virtual agents on datasets of static images or short videos, considering sequences of distinct learning tasks. However, in order to devise continual learning algorithms that operate in more realistic conditions, it is fundamental to gain access to rich, fully customizable and controlled experimental playgrounds. Focussing on the specific case of vision, we thus propose to leverage recent advances in 3D virtual environments in order to approach the automatic generation of potentially life-long dynamic scenes with photo-realistic appearance. Scenes are composed of objects that move along variable routes with different and fully customizable timings, and randomness can also be included in their evolution. A novel element of this paper is that scenes are described in a parametric way, thus allowing the user to fully control the visual complexity of the input stream the agent perceives. These general principles are concretely implemented exploiting a recently published 3D virtual environment. The user can generate scenes without the need of having strong skills in computer graphics, since all the generation facilities are exposed through a simple high-level Python interface. We publicly share the proposed generator.
Friendly Training: Neural Networks Can Adapt Data To Make Learning Easier
Jun 21, 2021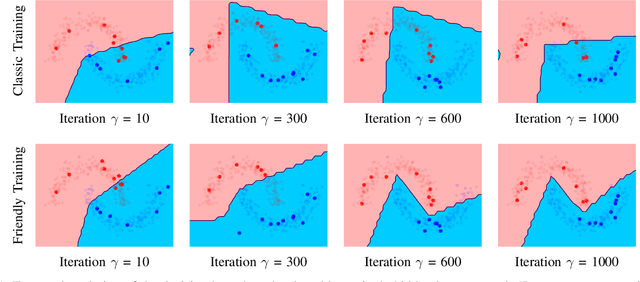

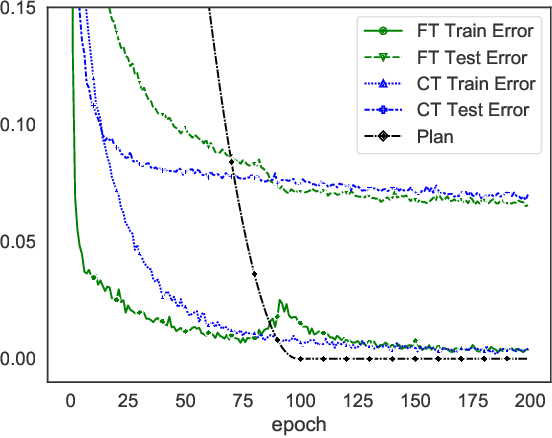
In the last decade, motivated by the success of Deep Learning, the scientific community proposed several approaches to make the learning procedure of Neural Networks more effective. When focussing on the way in which the training data are provided to the learning machine, we can distinguish between the classic random selection of stochastic gradient-based optimization and more involved techniques that devise curricula to organize data, and progressively increase the complexity of the training set. In this paper, we propose a novel training procedure named Friendly Training that, differently from the aforementioned approaches, involves altering the training examples in order to help the model to better fulfil its learning criterion. The model is allowed to simplify those examples that are too hard to be classified at a certain stage of the training procedure. The data transformation is controlled by a developmental plan that progressively reduces its impact during training, until it completely vanishes. In a sense, this is the opposite of what is commonly done in order to increase robustness against adversarial examples, i.e., Adversarial Training. Experiments on multiple datasets are provided, showing that Friendly Training yields improvements with respect to informed data sub-selection routines and random selection, especially in deep convolutional architectures. Results suggest that adapting the input data is a feasible way to stabilize learning and improve the generalization skills of the network.
Developing Constrained Neural Units Over Time
Sep 01, 2020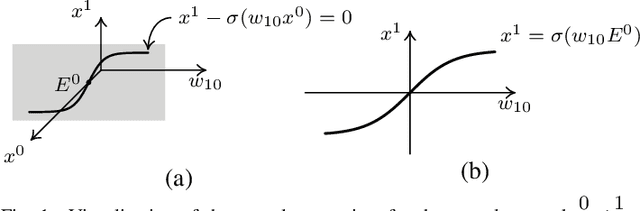
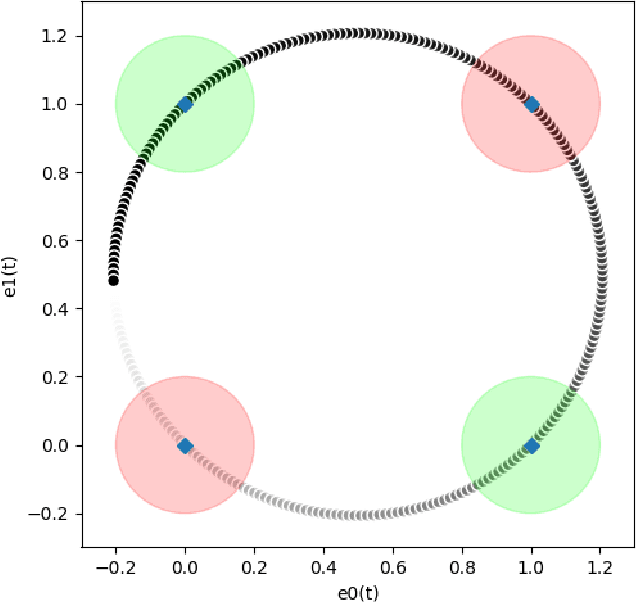
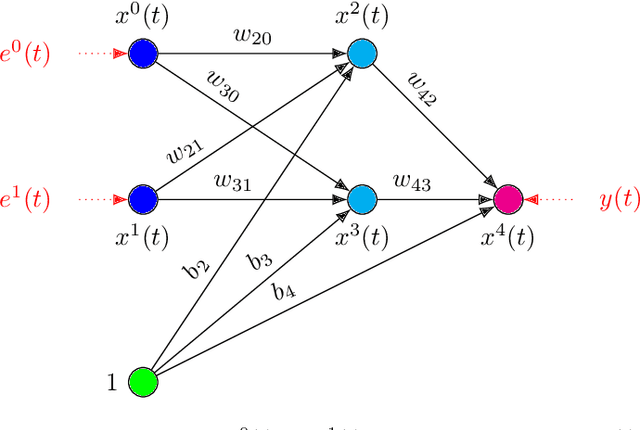
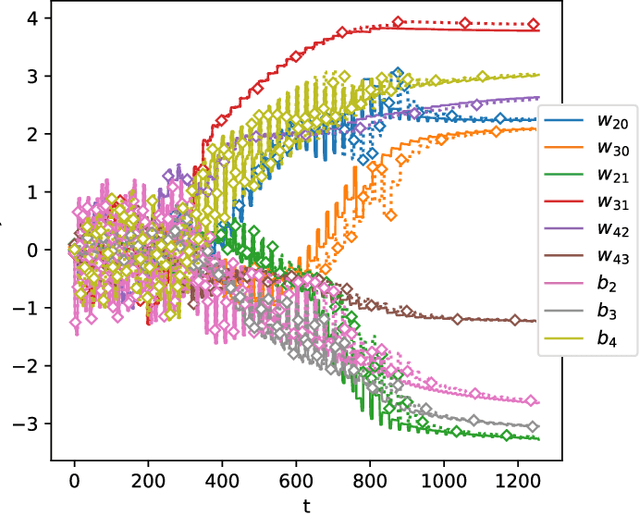
In this paper we present a foundational study on a constrained method that defines learning problems with Neural Networks in the context of the principle of least cognitive action, which very much resembles the principle of least action in mechanics. Starting from a general approach to enforce constraints into the dynamical laws of learning, this work focuses on an alternative way of defining Neural Networks, that is different from the majority of existing approaches. In particular, the structure of the neural architecture is defined by means of a special class of constraints that are extended also to the interaction with data, leading to "architectural" and "input-related" constraints, respectively. The proposed theory is cast into the time domain, in which data are presented to the network in an ordered manner, that makes this study an important step toward alternative ways of processing continuous streams of data with Neural Networks. The connection with the classic Backpropagation-based update rule of the weights of networks is discussed, showing that there are conditions under which our approach degenerates to Backpropagation. Moreover, the theory is experimentally evaluated on a simple problem that allows us to deeply study several aspects of the theory itself and to show the soundness of the model.