 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeela Zero Score: a Study of a Score-based AlphaGo Zero
Jan 31, 2022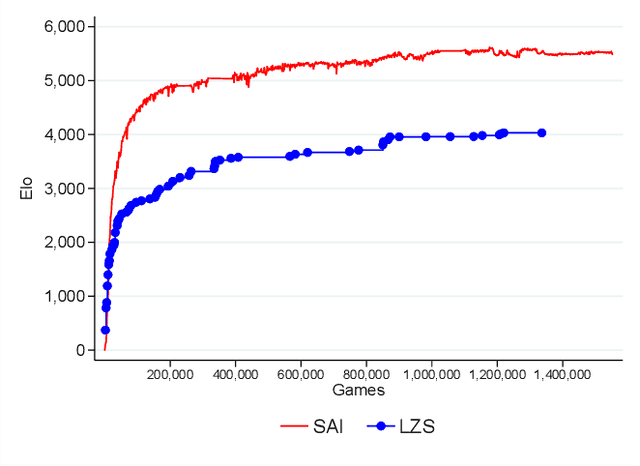
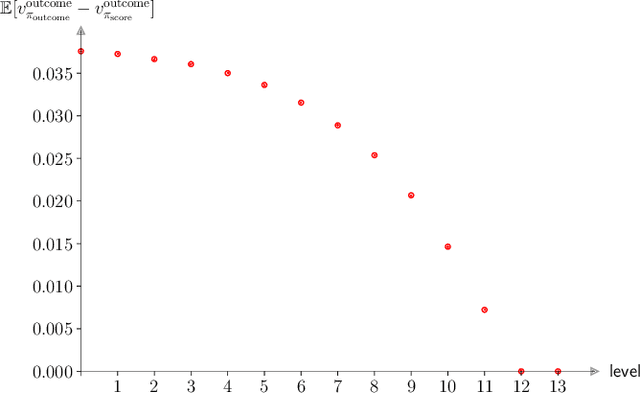
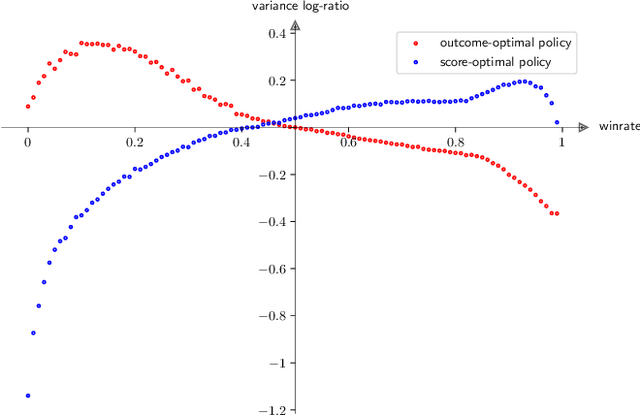
AlphaGo, AlphaGo Zero, and all of their derivatives can play with superhuman strength because they are able to predict the win-lose outcome with great accuracy. However, Go as a game is decided by a final score difference, and in final positions AlphaGo plays suboptimal moves: this is not surprising, since AlphaGo is completely unaware of the final score difference, all winning final positions being equivalent from the winrate perspective. This can be an issue, for instance when trying to learn the "best" move or to play with an initial handicap. Moreover, there is the theoretical quest of the "perfect game", that is, the minimax solution. Thus, a natural question arises: is it possible to train a successful Reinforcement Learning agent to predict score differences instead of winrates? No empirical or theoretical evidence can be found in the literature to support the folklore statement that "this does not work". In this paper we present Leela Zero Score, a software designed to support or disprove the "does not work" statement. Leela Zero Score is designed on the open-source solution known as Leela Zero, and is trained on a 9x9 board to predict score differences instead of winrates. We find that the training produces a rational player, and we analyze its style against a strong amateur human player, to find that it is prone to some mistakes when the outcome is close. We compare its strength against SAI, an AlphaGo Zero-like software working on the 9x9 board, and find that the training of Leela Zero Score has reached a premature convergence to a player weaker than SAI.
Messing Up 3D Virtual Environments: Transferable Adversarial 3D Objects
Sep 17, 2021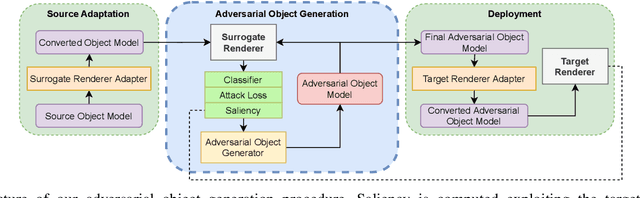



In the last few years, the scientific community showed a remarkable and increasing interest towards 3D Virtual Environments, training and testing Machine Learning-based models in realistic virtual worlds. On one hand, these environments could also become a mean to study the weaknesses of Machine Learning algorithms, or to simulate training settings that allow Machine Learning models to gain robustness to 3D adversarial attacks. On the other hand, their growing popularity might also attract those that aim at creating adversarial conditions to invalidate the benchmarking process, especially in the case of public environments that allow the contribution from a large community of people. Most of the existing Adversarial Machine Learning approaches are focused on static images, and little work has been done in studying how to deal with 3D environments and how a 3D object should be altered to fool a classifier that observes it. In this paper, we study how to craft adversarial 3D objects by altering their textures, using a tool chain composed of easily accessible elements. We show that it is possible, and indeed simple, to create adversarial objects using off-the-shelf limited surrogate renderers that can compute gradients with respect to the parameters of the rendering process, and, to a certain extent, to transfer the attacks to more advanced 3D engines. We propose a saliency-based attack that intersects the two classes of renderers in order to focus the alteration to those texture elements that are estimated to be effective in the target engine, evaluating its impact in popular neural classifiers.
Deep Reinforcement Learning for URLLC data management on top of scheduled eMBB traffic
Mar 02, 2021

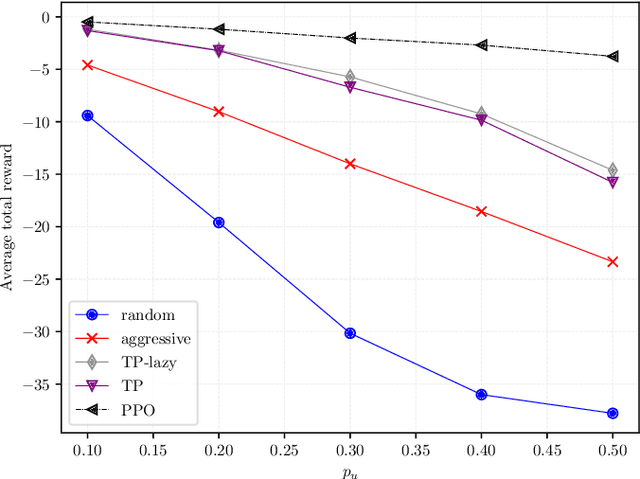

With the advent of 5G and the research into beyond 5G (B5G) networks, a novel and very relevant research issue is how to manage the coexistence of different types of traffic, each with very stringent but completely different requirements. In this paper we propose a deep reinforcement learning (DRL) algorithm to slice the available physical layer resources between ultra-reliable low-latency communications (URLLC) and enhanced Mobile BroadBand (eMBB) traffic. Specifically, in our setting the time-frequency resource grid is fully occupied by eMBB traffic and we train the DRL agent to employ proximal policy optimization (PPO), a state-of-the-art DRL algorithm, to dynamically allocate the incoming URLLC traffic by puncturing eMBB codewords. Assuming that each eMBB codeword can tolerate a certain limited amount of puncturing beyond which is in outage, we show that the policy devised by the DRL agent never violates the latency requirement of URLLC traffic and, at the same time, manages to keep the number of eMBB codewords in outage at minimum levels, when compared to other state-of-the-art schemes.
Generate and Revise: Reinforcement Learning in Neural Poetry
Feb 08, 2021



Writers, poets, singers usually do not create their compositions in just one breath. Text is revisited, adjusted, modified, rephrased, even multiple times, in order to better convey meanings, emotions and feelings that the author wants to express. Amongst the noble written arts, Poetry is probably the one that needs to be elaborated the most, since the composition has to formally respect predefined meter and rhyming schemes. In this paper, we propose a framework to generate poems that are repeatedly revisited and corrected, as humans do, in order to improve their overall quality. We frame the problem of revising poems in the context of Reinforcement Learning and, in particular, using Proximal Policy Optimization. Our model generates poems from scratch and it learns to progressively adjust the generated text in order to match a target criterion. We evaluate this approach in the case of matching a rhyming scheme, without having any information on which words are responsible of creating rhymes and on how to coherently alter the poem words. The proposed framework is general and, with an appropriate reward shaping, it can be applied to other text generation problems.
Pseudo Random Number Generation through Reinforcement Learning and Recurrent Neural Networks
Oct 31, 2020
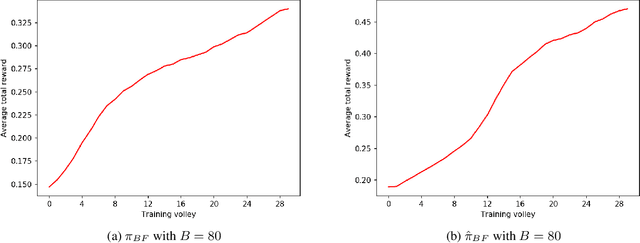
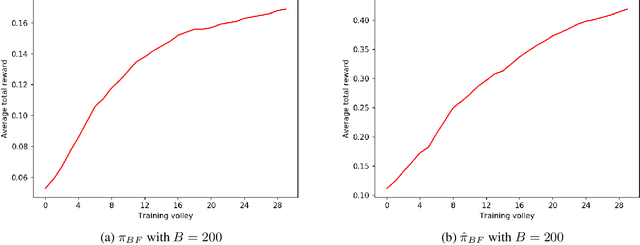
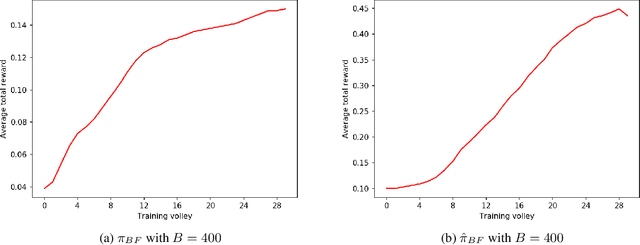
A Pseudo-Random Number Generator (PRNG) is any algorithm generating a sequence of numbers approximating properties of random numbers. These numbers are widely employed in mid-level cryptography and in software applications. Test suites are used to evaluate PRNGs quality by checking statistical properties of the generated sequences. These sequences are commonly represented bit by bit. This paper proposes a Reinforcement Learning (RL) approach to the task of generating PRNGs from scratch by learning a policy to solve a partially observable Markov Decision Process (MDP), where the full state is the period of the generated sequence and the observation at each time step is the last sequence of bits appended to such state. We use a Long-Short Term Memory (LSTM) architecture to model the temporal relationship between observations at different time steps, by tasking the LSTM memory with the extraction of significant features of the hidden portion of the MDP's states. We show that modeling a PRNG with a partially observable MDP and a LSTM architecture largely improves the results of the fully observable feedforward RL approach introduced in previous work.
SAILenv: Learning in Virtual Visual Environments Made Simple
Jul 20, 2020
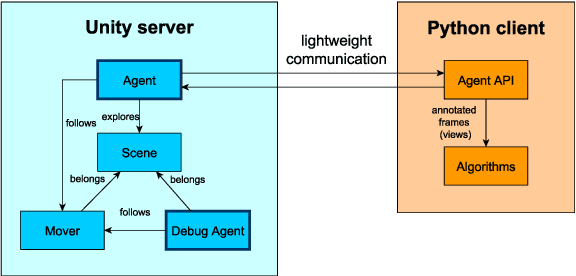


Recently, researchers in Machine Learning algorithms, Computer Vision scientists, engineers and others, showed a growing interest in 3D simulators as a mean to artificially create experimental settings that are very close to those in the real world. However, most of the existing platforms to interface algorithms with 3D environments are often designed to setup navigation-related experiments, to study physical interactions, or to handle ad-hoc cases that are not thought to be customized, sometimes lacking a strong photorealistic appearance and an easy-to-use software interface. In this paper, we present a novel platform, SAILenv, that is specifically designed to be simple and customizable, and that allows researchers to experiment visual recognition in virtual 3D scenes. A few lines of code are needed to interface every algorithm with the virtual world, and non-3D-graphics experts can easily customize the 3D environment itself, exploiting a collection of photorealistic objects. Our framework yields pixel-level semantic and instance labeling, depth, and, to the best of our knowledge, it is the only one that provides motion-related information directly inherited from the 3D engine. The client-server communication operates at a low level, avoiding the overhead of HTTP-based data exchanges. We perform experiments using a state-of-the-art object detector trained on real-world images, showing that it is able to recognize the photorealistic 3D objects of our environment. The computational burden of the optical flow compares favourably with the estimation performed using modern GPU-based convolutional networks or more classic implementations. We believe that the scientific community will benefit from the easiness and high-quality of our framework to evaluate newly proposed algorithms in their own customized realistic conditions.
Pseudo Random Number Generation: a Reinforcement Learning approach
Dec 15, 2019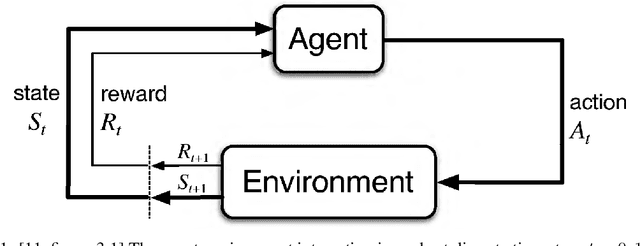

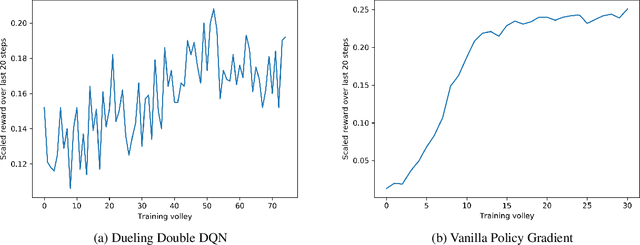
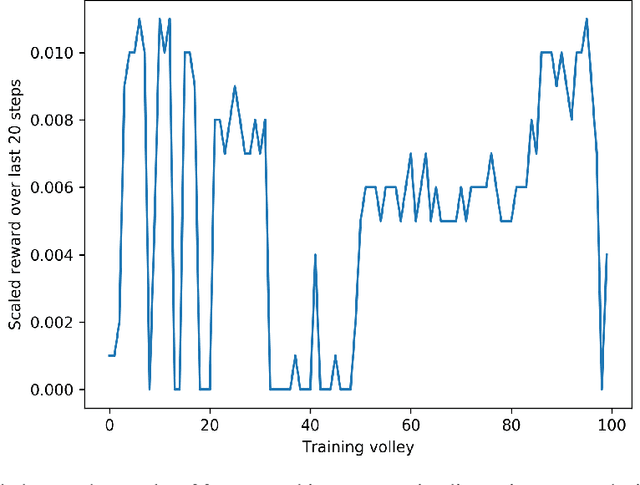
Pseudo-Random Numbers Generators (PRNGs) are algorithms produced to generate long sequences of statistically uncorrelated numbers, i.e. Pseudo-Random Numbers (PRNs). These numbers are widely employed in mid-level cryptography and in software applications. Test suites are used to evaluate PRNGs quality by checking statistical properties of the generated sequences. Machine learning techniques are often used to break these generators, for instance approximating a certain generator or a certain sequence using a neural network. But what about using machine learning to generate PRNs generators? This paper proposes a Reinforcement Learning (RL) approach to the task of generating PRNGs from scratch by learning a policy to solve an N-dimensional navigation problem. In this context, N is the length of the period of the generated sequence, and the policy is iteratively improved using the average value of an appropriate test suite run over that period. Aim of this work is to demonstrate the feasibility of the proposed approach, to compare it with classical methods, and to lay the foundation of a research path which combines RL and PRNGs.