 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeela Zero Score: a Study of a Score-based AlphaGo Zero
Jan 31, 2022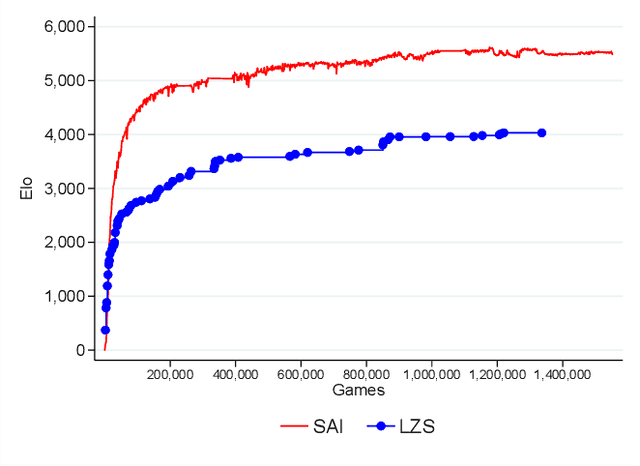
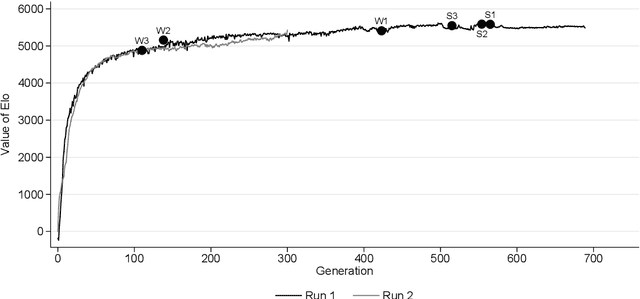
AlphaGo, AlphaGo Zero, and all of their derivatives can play with superhuman strength because they are able to predict the win-lose outcome with great accuracy. However, Go as a game is decided by a final score difference, and in final positions AlphaGo plays suboptimal moves: this is not surprising, since AlphaGo is completely unaware of the final score difference, all winning final positions being equivalent from the winrate perspective. This can be an issue, for instance when trying to learn the "best" move or to play with an initial handicap. Moreover, there is the theoretical quest of the "perfect game", that is, the minimax solution. Thus, a natural question arises: is it possible to train a successful Reinforcement Learning agent to predict score differences instead of winrates? No empirical or theoretical evidence can be found in the literature to support the folklore statement that "this does not work". In this paper we present Leela Zero Score, a software designed to support or disprove the "does not work" statement. Leela Zero Score is designed on the open-source solution known as Leela Zero, and is trained on a 9x9 board to predict score differences instead of winrates. We find that the training produces a rational player, and we analyze its style against a strong amateur human player, to find that it is prone to some mistakes when the outcome is close. We compare its strength against SAI, an AlphaGo Zero-like software working on the 9x9 board, and find that the training of Leela Zero Score has reached a premature convergence to a player weaker than SAI.
SAI: a Sensible Artificial Intelligence that plays with handicap and targets high scores in 9x9 Go (extended version)
May 26, 2019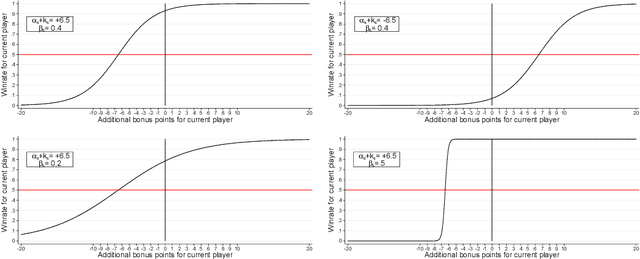
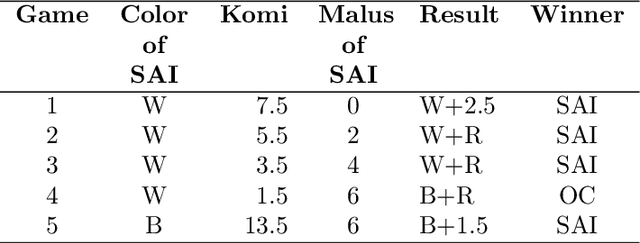
We develop a new model that can be applied to any perfect information two-player zero-sum game to target a high score, and thus a perfect play. We integrate this model into the Monte Carlo tree search-policy iteration learning pipeline introduced by Google DeepMind with AlphaGo. Training this model on 9x9 Go produces a superhuman Go player, thus proving that it is stable and robust. We show that this model can be used to effectively play with both positional and score handicap. We develop a family of agents that can target high scores against any opponent, and recover from very severe disadvantage against weak opponents. To the best of our knowledge, these are the first effective achievements in this direction.
SAI, a Sensible Artificial Intelligence that plays Go
Sep 11, 2018
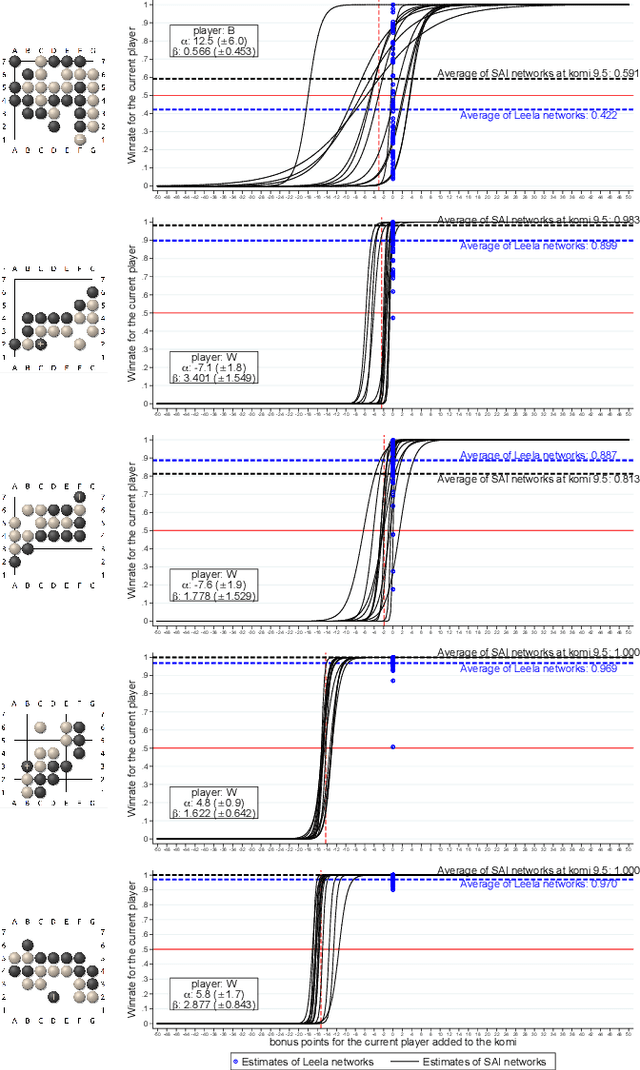
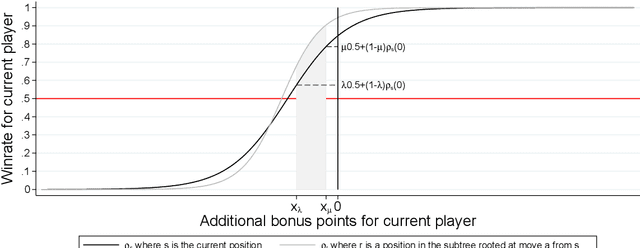
We propose a multiple-komi modification of the AlphaGo Zero/Leela Zero paradigm. The winrate as a function of the komi is modeled with a two-parameters sigmoid function, so that the neural network must predict just one more variable to assess the winrate for all komi values. A second novel feature is that training is based on self-play games that occasionaly branch -with changed komi- when the position is uneven. With this setting, reinforcement learning is showed to work on 7x7 Go, obtaining very strong playing agents. As a useful byproduct, the sigmoid parameters given by the network allow to estimate the score difference on the board, and to evaluate how much the game is decided.