 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterleaved Transceiver Design for a Continuous- Transmission MIMO-OFDM ISAC System
Aug 14, 2025This paper proposes an interleaved transceiver design method for a multiple-input multiple-output (MIMO) integrated sensing and communication (ISAC) system utilizing orthogonal frequency division multiplexing (OFDM) waveforms. We consider a continuous transmission system and focus on the design of the transmission signal and a receiving filter in the time domain for an interleaved transmission architecture. For communication performance, constructive interference (CI) is integrated into the optimization problem. For radar sensing performance, the integrated mainlobe-to-sidelobe ratio (IMSR) of the beampattern is considered to ensure desirable directivity. Additionally, we tackle the challenges of inter-block interference and eliminate the spurious peaks, which are crucial for accurate target detection. Regarding the hardware implementation aspect, the power of each time sample is constrained to manage the peak-to-average power ratio (PAPR). The design problem is addressed using an alternating optimization (AO) framework, with the subproblem for transmitted waveform design being solved via the successive convex approximation (SCA) method. To further enhance computational efficiency, the alternate direction penalty method (ADPM) is employed to solve the subproblems within the SCA iterations. The convergence of ADPM is established, with convergence of the case of more than two auxiliary variables being established for the first time. Numerical simulations validate the effectiveness of our transceiver design in achieving desirable performance in both radar sensing and communication, with the fast algorithm achieving comparable performance with greater computational efficiency.
Non-contact Pain Recognition from Video Sequences with Remote Physiological Measurements Prediction
May 18, 2021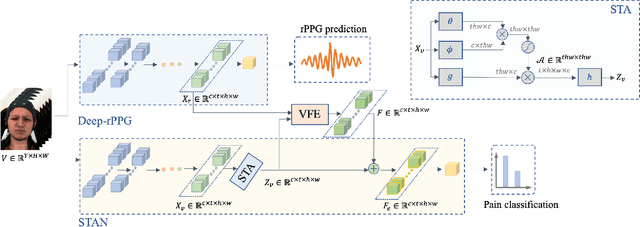
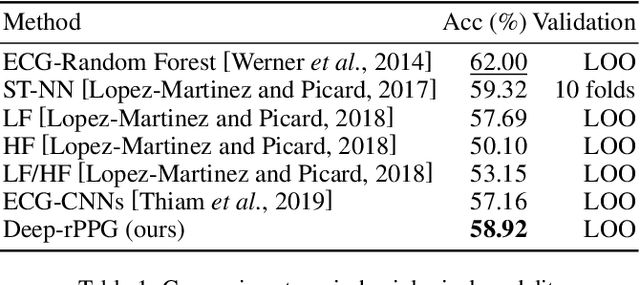


Automatic pain recognition is paramount for medical diagnosis and treatment. The existing works fall into three categories: assessing facial appearance changes, exploiting physiological cues, or fusing them in a multi-modal manner. However, (1) appearance changes are easily affected by subjective factors which impedes objective pain recognition. Besides, the appearance-based approaches ignore long-range spatial-temporal dependencies that are important for modeling expressions over time; (2) the physiological cues are obtained by attaching sensors on human body, which is inconvenient and uncomfortable. In this paper, we present a novel multi-task learning framework which encodes both appearance changes and physiological cues in a non-contact manner for pain recognition. The framework is able to capture both local and long-range dependencies via the proposed attention mechanism for the learned appearance representations, which are further enriched by temporally attended physiological cues (remote photoplethysmography, rPPG) that are recovered from videos in the auxiliary task. This framework is dubbed rPPG-enriched Spatio-Temporal Attention Network (rSTAN) and allows us to establish the state-of-the-art performance of non-contact pain recognition on publicly available pain databases. It demonstrates that rPPG predictions can be used as an auxiliary task to facilitate non-contact automatic pain recognition.
Multi-hierarchical Convolutional Network for Efficient Remote Photoplethysmograph Signal and Heart Rate Estimation from Face Video Clips
Apr 06, 2021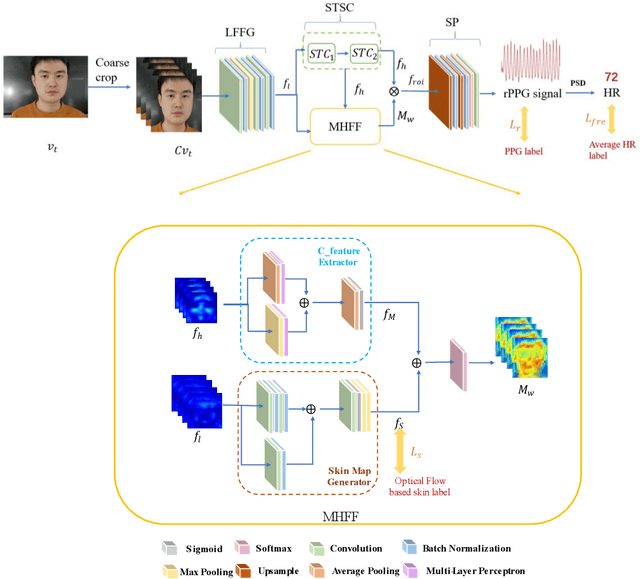
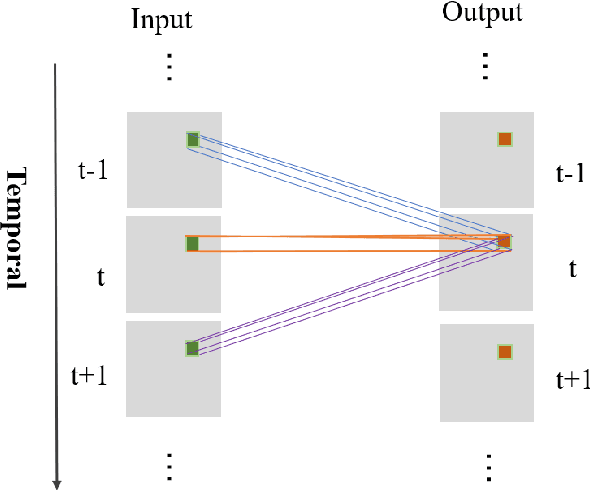
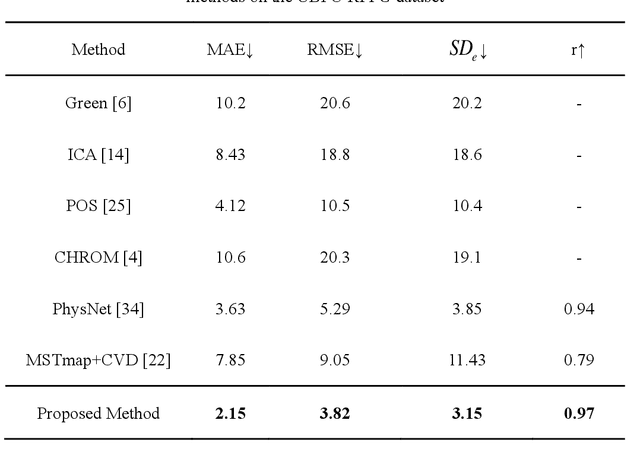
Heart beat rhythm and heart rate (HR) are important physiological parameters of the human body. This study presents an efficient multi-hierarchical spatio-temporal convolutional network that can quickly estimate remote physiological (rPPG) signal and HR from face video clips. First, the facial color distribution characteristics are extracted using a low-level face feature Generation (LFFG) module. Then, the three-dimensional (3D) spatio-temporal stack convolution module (STSC) and multi-hierarchical feature fusion module (MHFF) are used to strengthen the spatio-temporal correlation of multi-channel features. In the MHFF, sparse optical flow is used to capture the tiny motion information of faces between frames and generate a self-adaptive region of interest (ROI) skin mask. Finally, the signal prediction module (SP) is used to extract the estimated rPPG signal. The experimental results on the three datasets show that the proposed network outperforms the state-of-the-art methods.
A relic sketch extraction framework based on detail-aware hierarchical deep network
Jan 17, 2021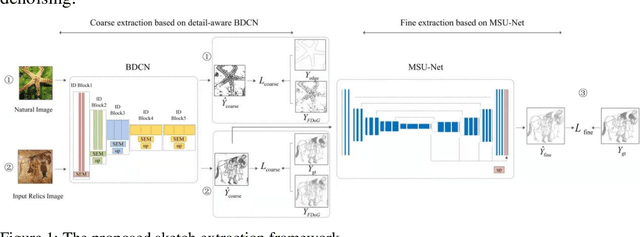
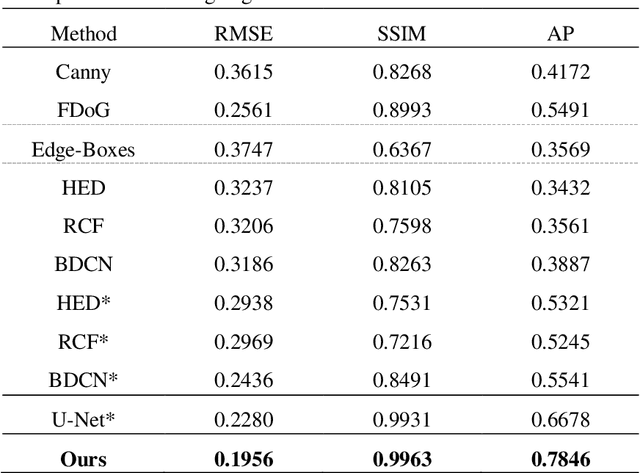
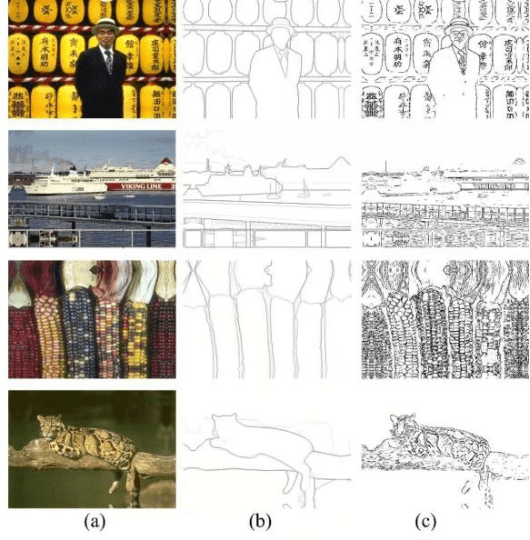

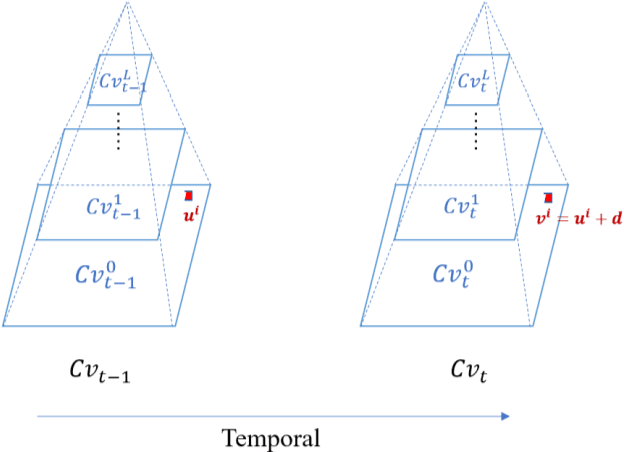
As the first step of the restoration process of painted relics, sketch extraction plays an important role in cultural research. However, sketch extraction suffers from serious disease corrosion, which results in broken lines and noise. To overcome these problems, we propose a deep learning-based hierarchical sketch extraction framework for painted cultural relics. We design the sketch extraction process into two stages: coarse extraction and fine extraction. In the coarse extraction stage, we develop a novel detail-aware bi-directional cascade network that integrates flow-based difference-of-Gaussians (FDoG) edge detection and a bi-directional cascade network (BDCN) under a transfer learning framework. It not only uses the pre-trained strategy to extenuate the requirements of large datasets for deep network training but also guides the network to learn the detail characteristics by the prior knowledge from FDoG. For the fine extraction stage, we design a new multiscale U-Net (MSU-Net) to effectively remove disease noise and refine the sketch. Specifically, all the features extracted from multiple intermediate layers in the decoder of MSU-Net are fused for sketch predication. Experimental results showed that the proposed method outperforms the other seven state-of-the-art methods in terms of visual and quantitative metrics and can also deal with complex backgrounds.
Automatic Image Labelling at Pixel Level
Jul 20, 2020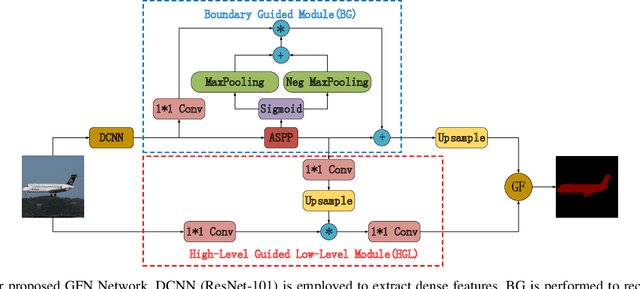



The performance of deep networks for semantic image segmentation largely depends on the availability of large-scale training images which are labelled at the pixel level. Typically, such pixel-level image labellings are obtained manually by a labour-intensive process. To alleviate the burden of manual image labelling, we propose an interesting learning approach to generate pixel-level image labellings automatically. A Guided Filter Network (GFN) is first developed to learn the segmentation knowledge from a source domain, and such GFN then transfers such segmentation knowledge to generate coarse object masks in the target domain. Such coarse object masks are treated as pseudo labels and they are further integrated to optimize/refine the GFN iteratively in the target domain. Our experiments on six image sets have demonstrated that our proposed approach can generate fine-grained object masks (i.e., pixel-level object labellings), whose quality is very comparable to the manually-labelled ones. Our proposed approach can also achieve better performance on semantic image segmentation than most existing weakly-supervised approaches.
Unsupervised Deep Hashing for Large-scale Visual Search
Jan 31, 2016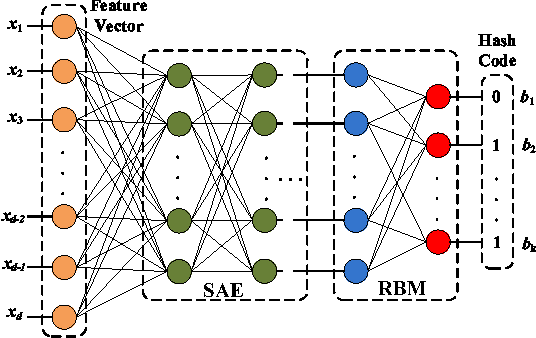
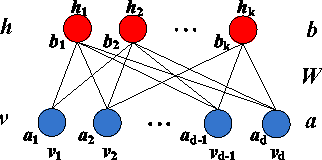
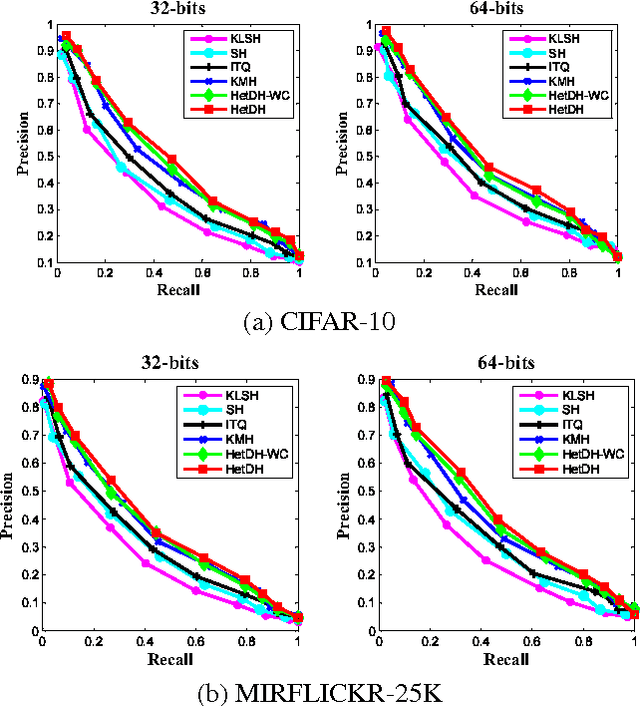
Learning based hashing plays a pivotal role in large-scale visual search. However, most existing hashing algorithms tend to learn shallow models that do not seek representative binary codes. In this paper, we propose a novel hashing approach based on unsupervised deep learning to hierarchically transform features into hash codes. Within the heterogeneous deep hashing framework, the autoencoder layers with specific constraints are considered to model the nonlinear mapping between features and binary codes. Then, a Restricted Boltzmann Machine (RBM) layer with constraints is utilized to reduce the dimension in the hamming space. Extensive experiments on the problem of visual search demonstrate the competitiveness of our proposed approach compared to state-of-the-art.