 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSC: A Marine Wildlife Video Dataset with Grounded Segmentation and Clip-Level Captioning
Aug 06, 2025Marine videos present significant challenges for video understanding due to the dynamics of marine objects and the surrounding environment, camera motion, and the complexity of underwater scenes. Existing video captioning datasets, typically focused on generic or human-centric domains, often fail to generalize to the complexities of the marine environment and gain insights about marine life. To address these limitations, we propose a two-stage marine object-oriented video captioning pipeline. We introduce a comprehensive video understanding benchmark that leverages the triplets of video, text, and segmentation masks to facilitate visual grounding and captioning, leading to improved marine video understanding and analysis, and marine video generation. Additionally, we highlight the effectiveness of video splitting in order to detect salient object transitions in scene changes, which significantly enrich the semantics of captioning content. Our dataset and code have been released at https://msc.hkustvgd.com.
Self-supervised Video Object Segmentation with Distillation Learning of Deformable Attention
Jan 25, 2024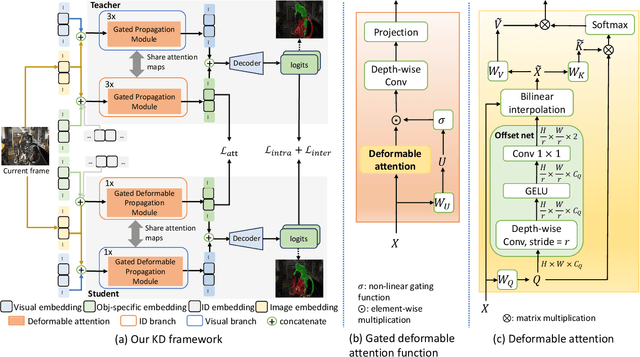



Video object segmentation is a fundamental research problem in computer vision. Recent techniques have often applied attention mechanism to object representation learning from video sequences. However, due to temporal changes in the video data, attention maps may not well align with the objects of interest across video frames, causing accumulated errors in long-term video processing. In addition, existing techniques have utilised complex architectures, requiring highly computational complexity and hence limiting the ability to integrate video object segmentation into low-powered devices. To address these issues, we propose a new method for self-supervised video object segmentation based on distillation learning of deformable attention. Specifically, we devise a lightweight architecture for video object segmentation that is effectively adapted to temporal changes. This is enabled by deformable attention mechanism, where the keys and values capturing the memory of a video sequence in the attention module have flexible locations updated across frames. The learnt object representations are thus adaptive to both the spatial and temporal dimensions. We train the proposed architecture in a self-supervised fashion through a new knowledge distillation paradigm where deformable attention maps are integrated into the distillation loss. We qualitatively and quantitatively evaluate our method and compare it with existing methods on benchmark datasets including DAVIS 2016/2017 and YouTube-VOS 2018/2019. Experimental results verify the superiority of our method via its achieved state-of-the-art performance and optimal memory usage.
Marine Video Kit: A New Marine Video Dataset for Content-based Analysis and Retrieval
Sep 23, 2022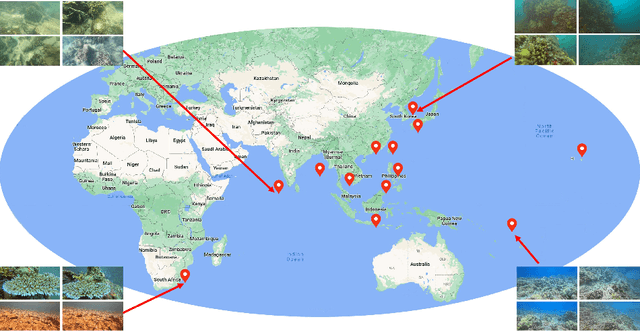
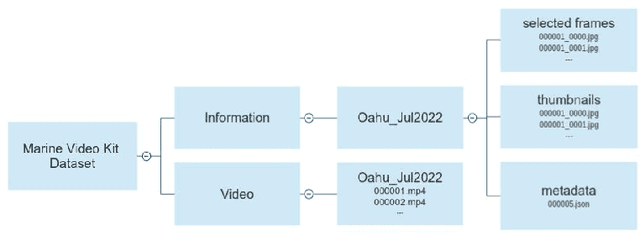
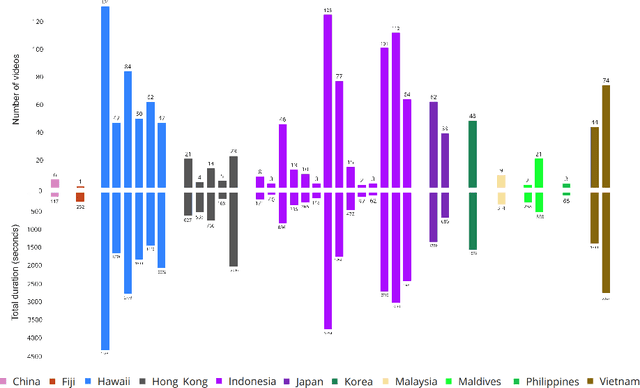
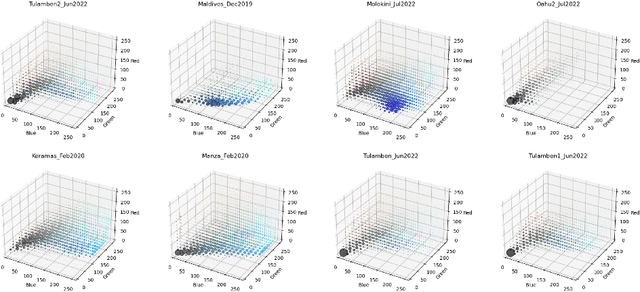
Effective analysis of unusual domain specific video collections represents an important practical problem, where state-of-the-art general purpose models still face limitations. Hence, it is desirable to design benchmark datasets that challenge novel powerful models for specific domains with additional constraints. It is important to remember that domain specific data may be noisier (e.g., endoscopic or underwater videos) and often require more experienced users for effective search. In this paper, we focus on single-shot videos taken from moving cameras in underwater environments which constitute a nontrivial challenge for research purposes. The first shard of a new Marine Video Kit dataset is presented to serve for video retrieval and other computer vision challenges. In addition to basic meta-data statistics, we present several insights and reference graphs based on low-level features as well as semantic annotations of selected keyframes. The analysis contains also experiments showing limitations of respected general purpose models for retrieval.
SideInfNet: A Deep Neural Network for Semi-Automatic Semantic Segmentation with Side Information
Mar 15, 2020
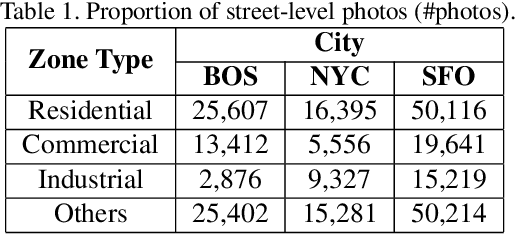

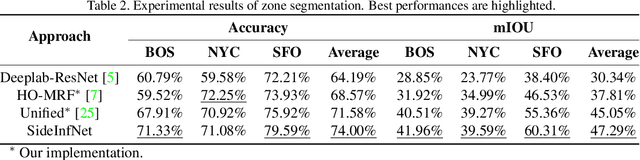
Fully-automatic execution is the ultimate goal for many Computer Vision applications. However, this objective is not always realistic in tasks associated with high failure costs, such as medical applications. For these tasks, a compromise between fully-automatic execution and user interactions is often preferred due to desirable accuracy and performance. Semi-automatic methods require minimal effort from experts by allowing them to provide cues that guide computer algorithms. Inspired by the practicality and applicability of the semi-automatic approach, this paper proposes a novel deep neural network architecture, namely SideInfNet that effectively integrates features learnt from images with side information extracted from user annotations to produce high quality semantic segmentation results. To evaluate our method, we applied the proposed network to three semantic segmentation tasks and conducted extensive experiments on benchmark datasets. Experimental results and comparison with prior work have verified the superiority of our model, suggesting the generality and effectiveness of the model in semi-automatic semantic segmentation.