 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWanna Hear Your Voice: Adaptive, Effective, and Language-Agnostic Approach in Voice Extraction
Paper and Code
Oct 01, 2024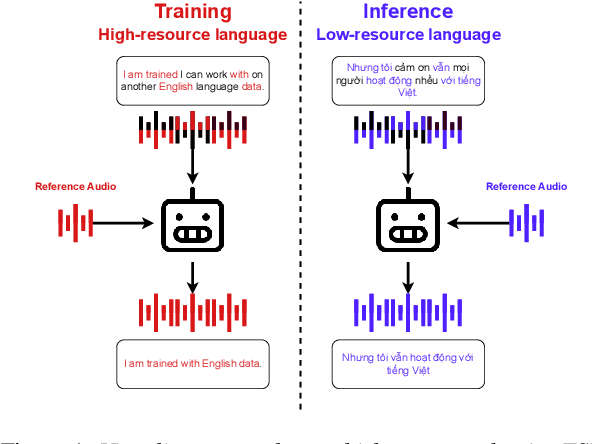

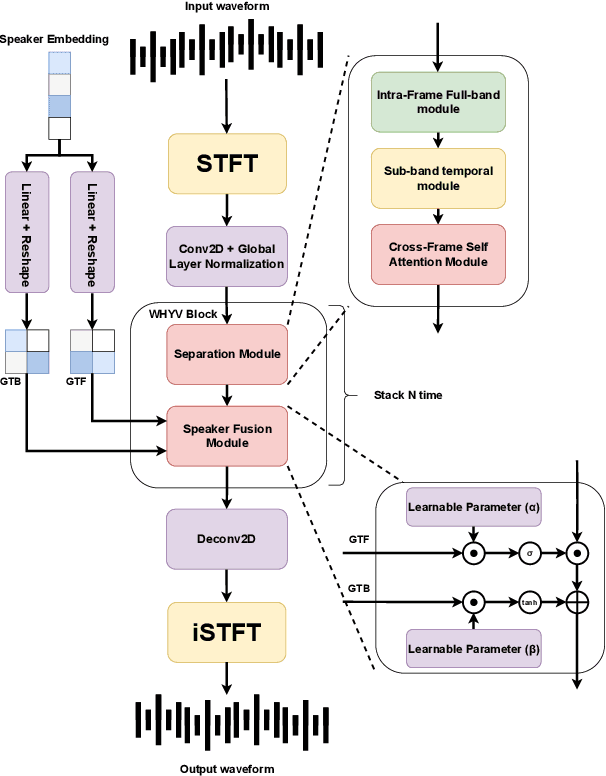
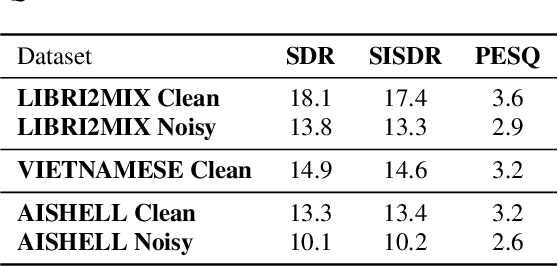
The research on audio clue-based target speaker extraction (TSE) has mostly focused on modeling the mixture and reference speech, achieving high performance in English due to the availability of large datasets. However, less attention has been given to the consistent properties of human speech across languages. To bridge this gap, we introduce WHYV (Wanna Hear Your Voice), which addresses the challenge of transferring TSE models from one language to another without fine-tuning. In this work, we proposed a gating mechanism that be able to modify specific frequencies based on the speaker's acoustic features. The model achieves an SI-SDR of 17.3544 on clean English speech and 13.2032 on clean speech mixed with Wham! noise, outperforming all other models in its ability to adapt to different languages.