 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Kernel Theory of Modern Data Augmentation
Mar 16, 2018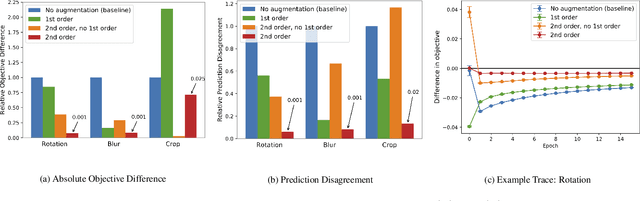
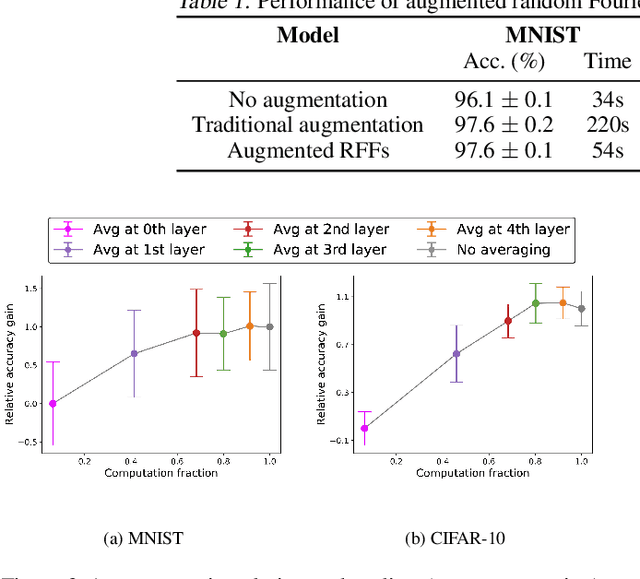
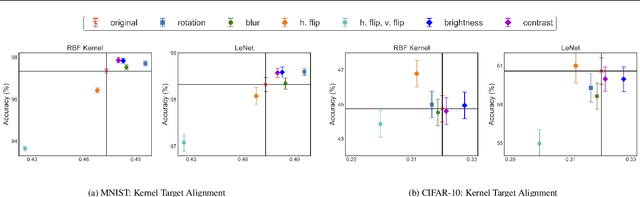
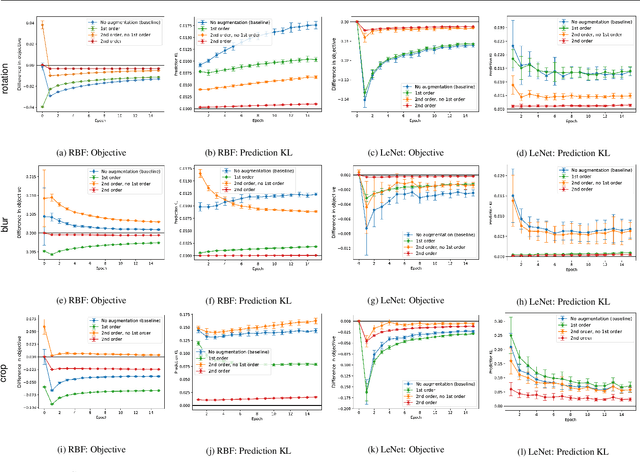
Data augmentation, a technique in which a training set is expanded with class-preserving transformations, is ubiquitous in modern machine learning pipelines. In this paper, we seek to establish a theoretical framework for understanding modern data augmentation techniques. We start by showing that for kernel classifiers, data augmentation can be approximated by first-order feature averaging and second-order variance regularization components. We connect this general approximation framework to prior work in invariant kernels, tangent propagation, and robust optimization. Next, we explicitly tackle the compositional aspect of modern data augmentation techniques, proposing a novel model of data augmentation as a Markov process. Under this model, we show that performing $k$-nearest neighbors with data augmentation is asymptotically equivalent to a kernel classifier. Finally, we illustrate ways in which our theoretical framework can be leveraged to accelerate machine learning workflows in practice, including reducing the amount of computation needed to train on augmented data, and predicting the utility of a transformation prior to training.
Learning to Compose Domain-Specific Transformations for Data Augmentation
Sep 30, 2017
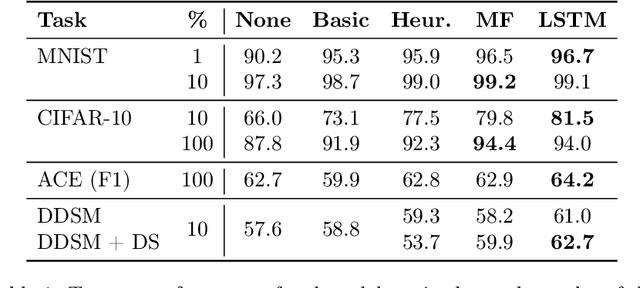
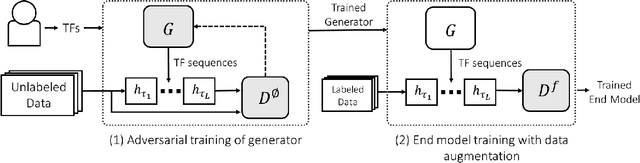

Data augmentation is a ubiquitous technique for increasing the size of labeled training sets by leveraging task-specific data transformations that preserve class labels. While it is often easy for domain experts to specify individual transformations, constructing and tuning the more sophisticated compositions typically needed to achieve state-of-the-art results is a time-consuming manual task in practice. We propose a method for automating this process by learning a generative sequence model over user-specified transformation functions using a generative adversarial approach. Our method can make use of arbitrary, non-deterministic transformation functions, is robust to misspecified user input, and is trained on unlabeled data. The learned transformation model can then be used to perform data augmentation for any end discriminative model. In our experiments, we show the efficacy of our approach on both image and text datasets, achieving improvements of 4.0 accuracy points on CIFAR-10, 1.4 F1 points on the ACE relation extraction task, and 3.4 accuracy points when using domain-specific transformation operations on a medical imaging dataset as compared to standard heuristic augmentation approaches.