 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Kernel Theory of Modern Data Augmentation
Paper and Code
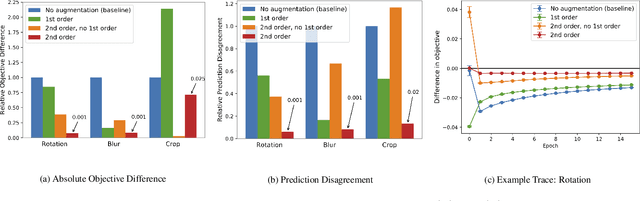
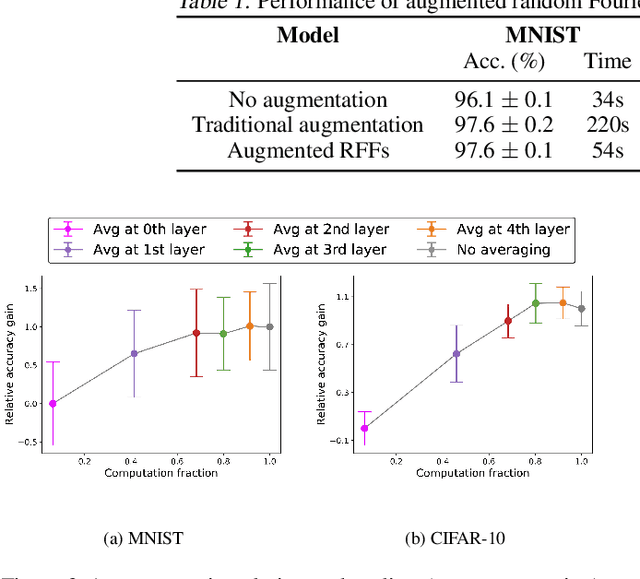
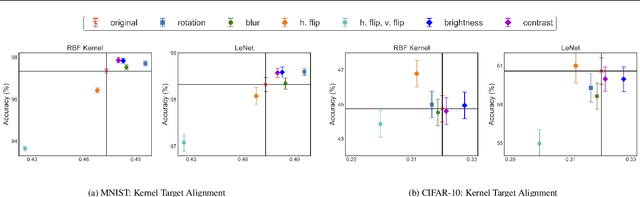
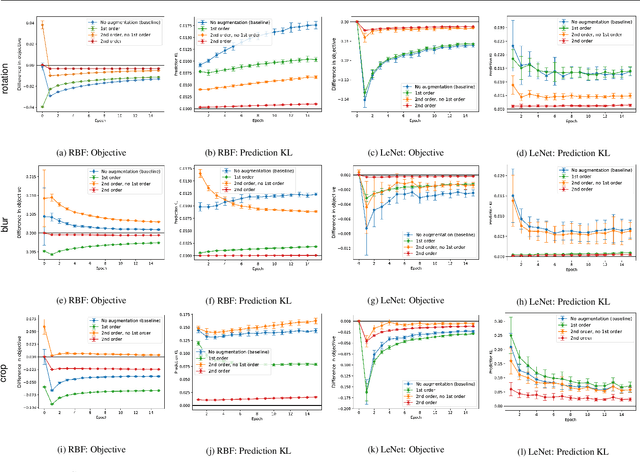
Data augmentation, a technique in which a training set is expanded with class-preserving transformations, is ubiquitous in modern machine learning pipelines. In this paper, we seek to establish a theoretical framework for understanding modern data augmentation techniques. We start by showing that for kernel classifiers, data augmentation can be approximated by first-order feature averaging and second-order variance regularization components. We connect this general approximation framework to prior work in invariant kernels, tangent propagation, and robust optimization. Next, we explicitly tackle the compositional aspect of modern data augmentation techniques, proposing a novel model of data augmentation as a Markov process. Under this model, we show that performing $k$-nearest neighbors with data augmentation is asymptotically equivalent to a kernel classifier. Finally, we illustrate ways in which our theoretical framework can be leveraged to accelerate machine learning workflows in practice, including reducing the amount of computation needed to train on augmented data, and predicting the utility of a transformation prior to training.