 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Stream Scene Understanding on Graph Embedding
Nov 12, 2023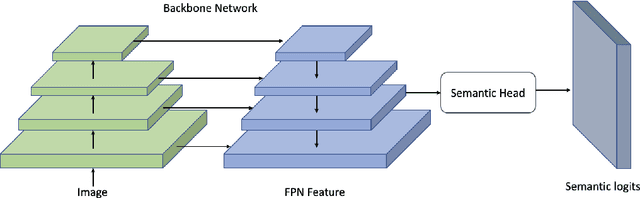
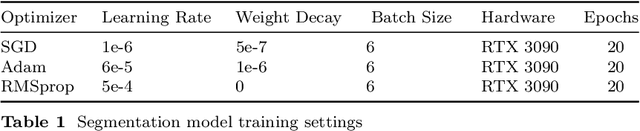
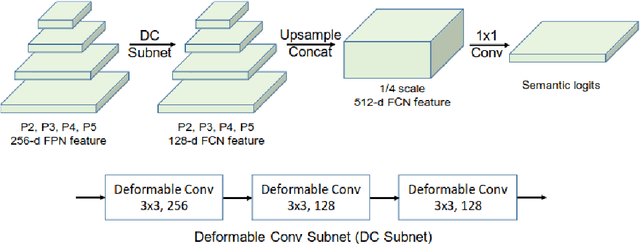

The paper presents a novel two-stream network architecture for enhancing scene understanding in computer vision. This architecture utilizes a graph feature stream and an image feature stream, aiming to merge the strengths of both modalities for improved performance in image classification and scene graph generation tasks. The graph feature stream network comprises a segmentation structure, scene graph generation, and a graph representation module. The segmentation structure employs the UPSNet architecture with a backbone that can be a residual network, Vit, or Swin Transformer. The scene graph generation component focuses on extracting object labels and neighborhood relationships from the semantic map to create a scene graph. Graph Convolutional Networks (GCN), GraphSAGE, and Graph Attention Networks (GAT) are employed for graph representation, with an emphasis on capturing node features and their interconnections. The image feature stream network, on the other hand, focuses on image classification through the use of Vision Transformer and Swin Transformer models. The two streams are fused using various data fusion methods. This fusion is designed to leverage the complementary strengths of graph-based and image-based features.Experiments conducted on the ADE20K dataset demonstrate the effectiveness of the proposed two-stream network in improving image classification accuracy compared to conventional methods. This research provides a significant contribution to the field of computer vision, particularly in the areas of scene understanding and image classification, by effectively combining graph-based and image-based approaches.
3D Face Parsing via Surface Parameterization and 2D Semantic Segmentation Network
Jun 18, 2022
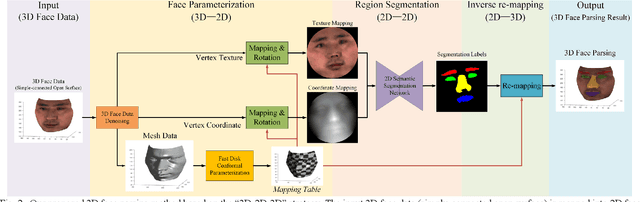
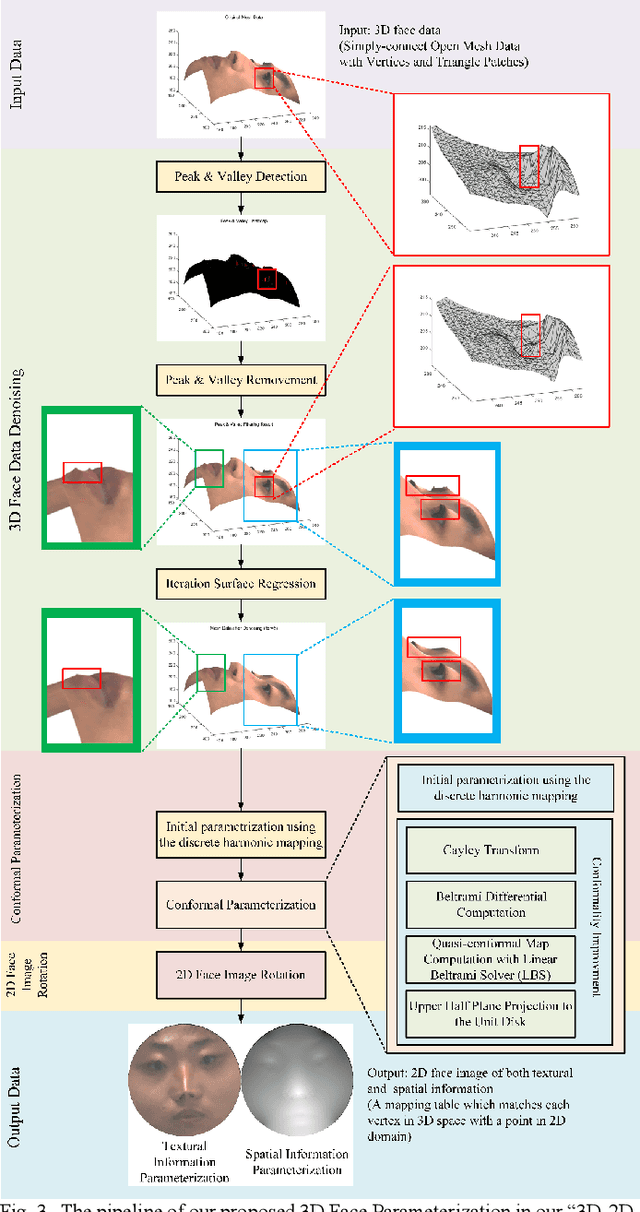
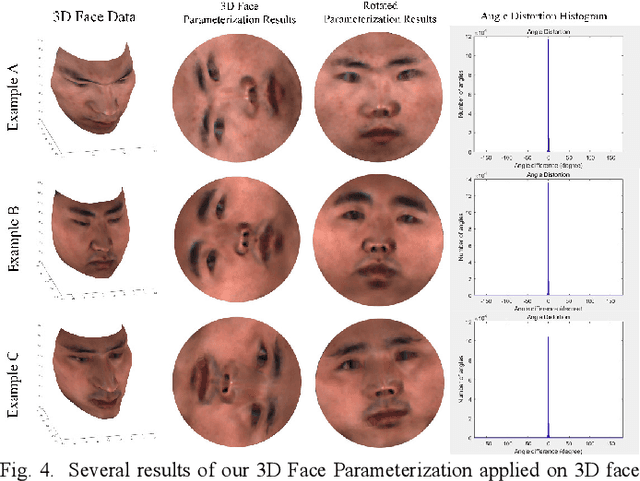
Face parsing assigns pixel-wise semantic labels as the face representation for computers, which is the fundamental part of many advanced face technologies. Compared with 2D face parsing, 3D face parsing shows more potential to achieve better performance and further application, but it is still challenging due to 3D mesh data computation. Recent works introduced different methods for 3D surface segmentation, while the performance is still limited. In this paper, we propose a method based on the "3D-2D-3D" strategy to accomplish 3D face parsing. The topological disk-like 2D face image containing spatial and textural information is transformed from the sampled 3D face data through the face parameterization algorithm, and a specific 2D network called CPFNet is proposed to achieve the semantic segmentation of the 2D parameterized face data with multi-scale technologies and feature aggregation. The 2D semantic result is then inversely re-mapped to 3D face data, which finally achieves the 3D face parsing. Experimental results show that both CPFNet and the "3D-2D-3D" strategy accomplish high-quality 3D face parsing and outperform state-of-the-art 2D networks as well as 3D methods in both qualitative and quantitative comparisons.