 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Stream Scene Understanding on Graph Embedding
Paper and Code
Nov 12, 2023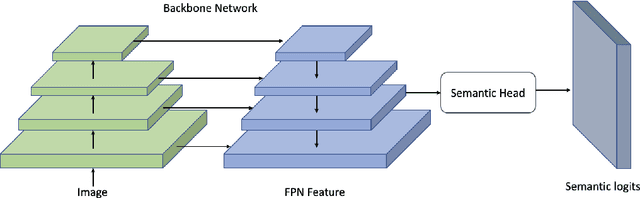
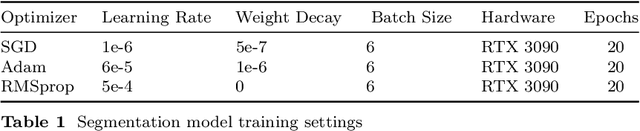
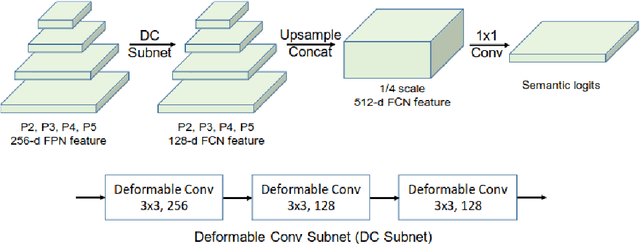

The paper presents a novel two-stream network architecture for enhancing scene understanding in computer vision. This architecture utilizes a graph feature stream and an image feature stream, aiming to merge the strengths of both modalities for improved performance in image classification and scene graph generation tasks. The graph feature stream network comprises a segmentation structure, scene graph generation, and a graph representation module. The segmentation structure employs the UPSNet architecture with a backbone that can be a residual network, Vit, or Swin Transformer. The scene graph generation component focuses on extracting object labels and neighborhood relationships from the semantic map to create a scene graph. Graph Convolutional Networks (GCN), GraphSAGE, and Graph Attention Networks (GAT) are employed for graph representation, with an emphasis on capturing node features and their interconnections. The image feature stream network, on the other hand, focuses on image classification through the use of Vision Transformer and Swin Transformer models. The two streams are fused using various data fusion methods. This fusion is designed to leverage the complementary strengths of graph-based and image-based features.Experiments conducted on the ADE20K dataset demonstrate the effectiveness of the proposed two-stream network in improving image classification accuracy compared to conventional methods. This research provides a significant contribution to the field of computer vision, particularly in the areas of scene understanding and image classification, by effectively combining graph-based and image-based approaches.