 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRAL: Visual In-Context Reasoning via Analogy in Diffusion Transformers
Feb 03, 2026Replicating In-Context Learning (ICL) in computer vision remains challenging due to task heterogeneity. We propose \textbf{VIRAL}, a framework that elicits visual reasoning from a pre-trained image editing model by formulating ICL as conditional generation via visual analogy ($x_s : x_t :: x_q : y_q$). We adapt a frozen Diffusion Transformer (DiT) using role-aware multi-image conditioning and introduce a Mixture-of-Experts LoRA to mitigate gradient interference across diverse tasks. Additionally, to bridge the gaps in current visual context datasets, we curate a large-scale dataset spanning perception, restoration, and editing. Experiments demonstrate that VIRAL outperforms existing methods, validating that a unified V-ICL paradigm can handle the majority of visual tasks, including open-domain editing. Our code is available at https://anonymous.4open.science/r/VIRAL-744A
Spectral Evolution Search: Efficient Inference-Time Scaling for Reward-Aligned Image Generation
Feb 03, 2026Inference-time scaling offers a versatile paradigm for aligning visual generative models with downstream objectives without parameter updates. However, existing approaches that optimize the high-dimensional initial noise suffer from severe inefficiency, as many search directions exert negligible influence on the final generation. We show that this inefficiency is closely related to a spectral bias in generative dynamics: model sensitivity to initial perturbations diminishes rapidly as frequency increases. Building on this insight, we propose Spectral Evolution Search (SES), a plug-and-play framework for initial noise optimization that executes gradient-free evolutionary search within a low-frequency subspace. Theoretically, we derive the Spectral Scaling Prediction from perturbation propagation dynamics, which explains the systematic differences in the impact of perturbations across frequencies. Extensive experiments demonstrate that SES significantly advances the Pareto frontier of generation quality versus computational cost, consistently outperforming strong baselines under equivalent budgets.
Nexus-Gen: A Unified Model for Image Understanding, Generation, and Editing
Apr 30, 2025Unified multimodal large language models (MLLMs) aim to integrate multimodal understanding and generation abilities through a single framework. Despite their versatility, existing open-source unified models exhibit performance gaps against domain-specific architectures. To bridge this gap, we present Nexus-Gen, a unified model that synergizes the language reasoning capabilities of LLMs with the image synthesis power of diffusion models. To align the embedding space of the LLM and diffusion model, we conduct a dual-phase alignment training process. (1) The autoregressive LLM learns to predict image embeddings conditioned on multimodal inputs, while (2) the vision decoder is trained to reconstruct high-fidelity images from these embeddings. During training the LLM, we identified a critical discrepancy between the autoregressive paradigm's training and inference phases, where error accumulation in continuous embedding space severely degrades generation quality. To avoid this issue, we introduce a prefilled autoregression strategy that prefills input sequence with position-embedded special tokens instead of continuous embeddings. Through dual-phase training, Nexus-Gen has developed the integrated capability to comprehensively address the image understanding, generation and editing tasks. All models, datasets, and codes are published at https://github.com/modelscope/Nexus-Gen.git to facilitate further advancements across the field.
EliGen: Entity-Level Controlled Image Generation with Regional Attention
Jan 02, 2025



Recent advancements in diffusion models have significantly advanced text-to-image generation, yet global text prompts alone remain insufficient for achieving fine-grained control over individual entities within an image. To address this limitation, we present EliGen, a novel framework for Entity-Level controlled Image Generation. We introduce regional attention, a mechanism for diffusion transformers that requires no additional parameters, seamlessly integrating entity prompts and arbitrary-shaped spatial masks. By contributing a high-quality dataset with fine-grained spatial and semantic entity-level annotations, we train EliGen to achieve robust and accurate entity-level manipulation, surpassing existing methods in both positional control precision and image quality. Additionally, we propose an inpainting fusion pipeline, extending EliGen to multi-entity image inpainting tasks. We further demonstrate its flexibility by integrating it with community models such as IP-Adapter and MLLM, unlocking new creative possibilities. The source code, dataset, and model will be released publicly.
ArtAug: Enhancing Text-to-Image Generation through Synthesis-Understanding Interaction
Dec 18, 2024



The emergence of diffusion models has significantly advanced image synthesis. The recent studies of model interaction and self-corrective reasoning approach in large language models offer new insights for enhancing text-to-image models. Inspired by these studies, we propose a novel method called ArtAug for enhancing text-to-image models in this paper. To the best of our knowledge, ArtAug is the first one that improves image synthesis models via model interactions with understanding models. In the interactions, we leverage human preferences implicitly learned by image understanding models to provide fine-grained suggestions for image synthesis models. The interactions can modify the image content to make it aesthetically pleasing, such as adjusting exposure, changing shooting angles, and adding atmospheric effects. The enhancements brought by the interaction are iteratively fused into the synthesis model itself through an additional enhancement module. This enables the synthesis model to directly produce aesthetically pleasing images without any extra computational cost. In the experiments, we train the ArtAug enhancement module on existing text-to-image models. Various evaluation metrics consistently demonstrate that ArtAug enhances the generative capabilities of text-to-image models without incurring additional computational costs. The source code and models will be released publicly.
ExVideo: Extending Video Diffusion Models via Parameter-Efficient Post-Tuning
Jun 20, 2024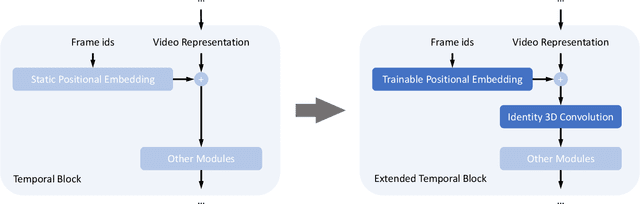



Recently, advancements in video synthesis have attracted significant attention. Video synthesis models such as AnimateDiff and Stable Video Diffusion have demonstrated the practical applicability of diffusion models in creating dynamic visual content. The emergence of SORA has further spotlighted the potential of video generation technologies. Nonetheless, the extension of video lengths has been constrained by the limitations in computational resources. Most existing video synthesis models can only generate short video clips. In this paper, we propose a novel post-tuning methodology for video synthesis models, called ExVideo. This approach is designed to enhance the capability of current video synthesis models, allowing them to produce content over extended temporal durations while incurring lower training expenditures. In particular, we design extension strategies across common temporal model architectures respectively, including 3D convolution, temporal attention, and positional embedding. To evaluate the efficacy of our proposed post-tuning approach, we conduct extension training on the Stable Video Diffusion model. Our approach augments the model's capacity to generate up to $5\times$ its original number of frames, requiring only 1.5k GPU hours of training on a dataset comprising 40k videos. Importantly, the substantial increase in video length doesn't compromise the model's innate generalization capabilities, and the model showcases its advantages in generating videos of diverse styles and resolutions. We will release the source code and the enhanced model publicly.
Diffutoon: High-Resolution Editable Toon Shading via Diffusion Models
Jan 29, 2024Toon shading is a type of non-photorealistic rendering task of animation. Its primary purpose is to render objects with a flat and stylized appearance. As diffusion models have ascended to the forefront of image synthesis methodologies, this paper delves into an innovative form of toon shading based on diffusion models, aiming to directly render photorealistic videos into anime styles. In video stylization, extant methods encounter persistent challenges, notably in maintaining consistency and achieving high visual quality. In this paper, we model the toon shading problem as four subproblems: stylization, consistency enhancement, structure guidance, and colorization. To address the challenges in video stylization, we propose an effective toon shading approach called \textit{Diffutoon}. Diffutoon is capable of rendering remarkably detailed, high-resolution, and extended-duration videos in anime style. It can also edit the content according to prompts via an additional branch. The efficacy of Diffutoon is evaluated through quantitive metrics and human evaluation. Notably, Diffutoon surpasses both open-source and closed-source baseline approaches in our experiments. Our work is accompanied by the release of both the source code and example videos on Github (Project page: https://ecnu-cilab.github.io/DiffutoonProjectPage/).
FastBlend: a Powerful Model-Free Toolkit Making Video Stylization Easier
Nov 15, 2023With the emergence of diffusion models and rapid development in image processing, it has become effortless to generate fancy images in tasks such as style transfer and image editing. However, these impressive image processing approaches face consistency issues in video processing. In this paper, we propose a powerful model-free toolkit called FastBlend to address the consistency problem for video processing. Based on a patch matching algorithm, we design two inference modes, including blending and interpolation. In the blending mode, FastBlend eliminates video flicker by blending the frames within a sliding window. Moreover, we optimize both computational efficiency and video quality according to different application scenarios. In the interpolation mode, given one or more keyframes rendered by diffusion models, FastBlend can render the whole video. Since FastBlend does not modify the generation process of diffusion models, it exhibits excellent compatibility. Extensive experiments have demonstrated the effectiveness of FastBlend. In the blending mode, FastBlend outperforms existing methods for video deflickering and video synthesis. In the interpolation mode, FastBlend surpasses video interpolation and model-based video processing approaches. The source codes have been released on GitHub.
Learning Knowledge-Enhanced Contextual Language Representations for Domain Natural Language Understanding
Nov 12, 2023Knowledge-Enhanced Pre-trained Language Models (KEPLMs) improve the performance of various downstream NLP tasks by injecting knowledge facts from large-scale Knowledge Graphs (KGs). However, existing methods for pre-training KEPLMs with relational triples are difficult to be adapted to close domains due to the lack of sufficient domain graph semantics. In this paper, we propose a Knowledge-enhanced lANGuAge Representation learning framework for various clOsed dOmains (KANGAROO) via capturing the implicit graph structure among the entities. Specifically, since the entity coverage rates of closed-domain KGs can be relatively low and may exhibit the global sparsity phenomenon for knowledge injection, we consider not only the shallow relational representations of triples but also the hyperbolic embeddings of deep hierarchical entity-class structures for effective knowledge fusion.Moreover, as two closed-domain entities under the same entity-class often have locally dense neighbor subgraphs counted by max point biconnected component, we further propose a data augmentation strategy based on contrastive learning over subgraphs to construct hard negative samples of higher quality. It makes the underlying KELPMs better distinguish the semantics of these neighboring entities to further complement the global semantic sparsity. In the experiments, we evaluate KANGAROO over various knowledge-aware and general NLP tasks in both full and few-shot learning settings, outperforming various KEPLM training paradigms performance in closed-domains significantly.
PAI-Diffusion: Constructing and Serving a Family of Open Chinese Diffusion Models for Text-to-image Synthesis on the Cloud
Sep 11, 2023



Text-to-image synthesis for the Chinese language poses unique challenges due to its large vocabulary size, and intricate character relationships. While existing diffusion models have shown promise in generating images from textual descriptions, they often neglect domain-specific contexts and lack robustness in handling the Chinese language. This paper introduces PAI-Diffusion, a comprehensive framework that addresses these limitations. PAI-Diffusion incorporates both general and domain-specific Chinese diffusion models, enabling the generation of contextually relevant images. It explores the potential of using LoRA and ControlNet for fine-grained image style transfer and image editing, empowering users with enhanced control over image generation. Moreover, PAI-Diffusion seamlessly integrates with Alibaba Cloud's Machine Learning Platform for AI, providing accessible and scalable solutions. All the Chinese diffusion model checkpoints, LoRAs, and ControlNets, including domain-specific ones, are publicly available. A user-friendly Chinese WebUI and the diffusers-api elastic inference toolkit, also open-sourced, further facilitate the easy deployment of PAI-Diffusion models in various environments, making it a valuable resource for Chinese text-to-image synthesis.