 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtAug: Enhancing Text-to-Image Generation through Synthesis-Understanding Interaction
Dec 18, 2024



The emergence of diffusion models has significantly advanced image synthesis. The recent studies of model interaction and self-corrective reasoning approach in large language models offer new insights for enhancing text-to-image models. Inspired by these studies, we propose a novel method called ArtAug for enhancing text-to-image models in this paper. To the best of our knowledge, ArtAug is the first one that improves image synthesis models via model interactions with understanding models. In the interactions, we leverage human preferences implicitly learned by image understanding models to provide fine-grained suggestions for image synthesis models. The interactions can modify the image content to make it aesthetically pleasing, such as adjusting exposure, changing shooting angles, and adding atmospheric effects. The enhancements brought by the interaction are iteratively fused into the synthesis model itself through an additional enhancement module. This enables the synthesis model to directly produce aesthetically pleasing images without any extra computational cost. In the experiments, we train the ArtAug enhancement module on existing text-to-image models. Various evaluation metrics consistently demonstrate that ArtAug enhances the generative capabilities of text-to-image models without incurring additional computational costs. The source code and models will be released publicly.
FedMCP: Parameter-Efficient Federated Learning with Model-Contrastive Personalization
Aug 28, 2024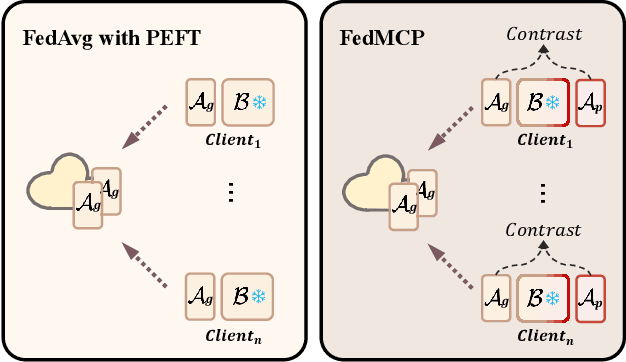
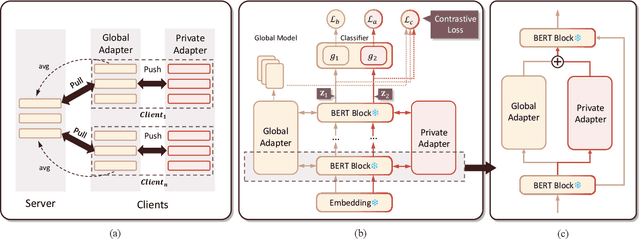
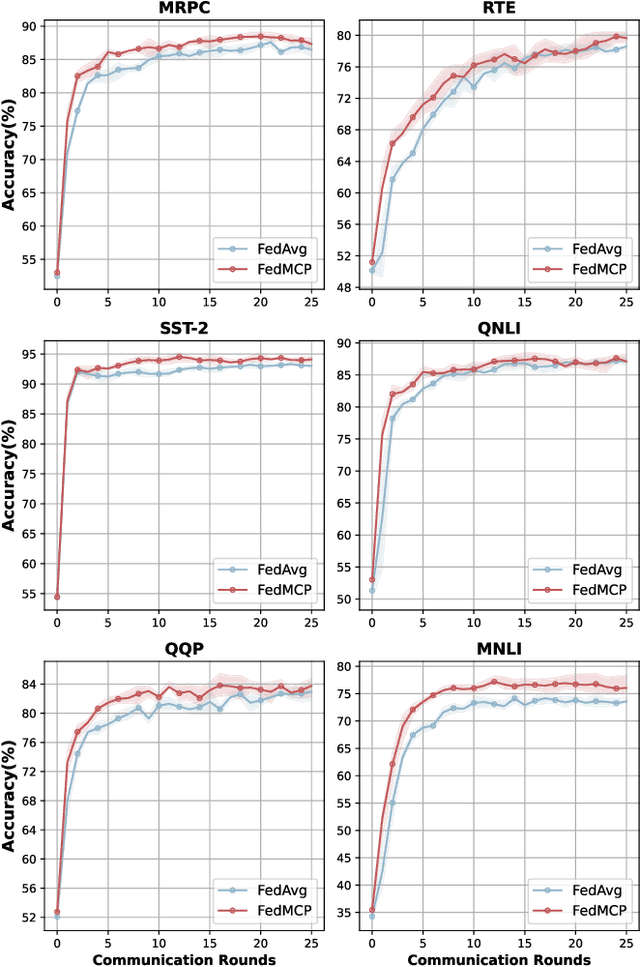
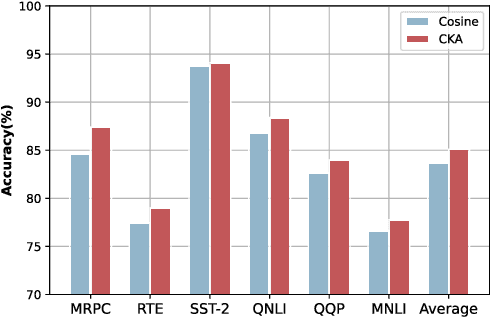
With increasing concerns and regulations on data privacy, fine-tuning pretrained language models (PLMs) in federated learning (FL) has become a common paradigm for NLP tasks. Despite being extensively studied, the existing methods for this problem still face two primary challenges. First, the huge number of parameters in large-scale PLMs leads to excessive communication and computational overhead. Second, the heterogeneity of data and tasks across clients poses a significant obstacle to achieving the desired fine-tuning performance. To address the above problems, we propose FedMCP, a novel parameter-efficient fine-tuning method with model-contrastive personalization for FL. Specifically, FedMCP adds two lightweight adapter modules, i.e., the global adapter and the private adapter, to the frozen PLMs within clients. In a communication round, each client sends only the global adapter to the server for federated aggregation. Furthermore, FedMCP introduces a model-contrastive regularization term between the two adapters. This, on the one hand, encourages the global adapter to assimilate universal knowledge and, on the other hand, the private adapter to capture client-specific knowledge. By leveraging both adapters, FedMCP can effectively provide fine-tuned personalized models tailored to individual clients. Extensive experiments on highly heterogeneous cross-task, cross-silo datasets show that FedMCP achieves substantial performance improvements over state-of-the-art FL fine-tuning approaches for PLMs.