 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTPred: Benchmarking MLLMs for Interpretable Geo-localization and Time-of-capture Prediction
Jan 19, 2026Geo-localization aims to infer the geographic location where an image was captured using observable visual evidence. Traditional methods achieve impressive results through large-scale training on massive image corpora. With the emergence of multi-modal large language models (MLLMs), recent studies have explored their applications in geo-localization, benefiting from improved accuracy and interpretability. However, existing benchmarks largely ignore the temporal information inherent in images, which can further constrain the location. To bridge this gap, we introduce GTPred, a novel benchmark for geo-temporal prediction. GTPred comprises 370 globally distributed images spanning over 120 years. We evaluate MLLM predictions by jointly considering year and hierarchical location sequence matching, and further assess intermediate reasoning chains using meticulously annotated ground-truth reasoning processes. Experiments on 8 proprietary and 7 open-source MLLMs show that, despite strong visual perception, current models remain limited in world knowledge and geo-temporal reasoning. Results also demonstrate that incorporating temporal information significantly enhances location inference performance.
OBIFormer: A Fast Attentive Denoising Framework for Oracle Bone Inscriptions
Apr 18, 2025
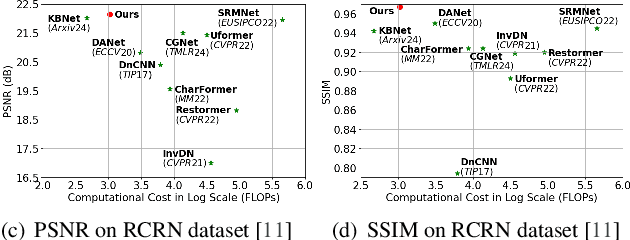
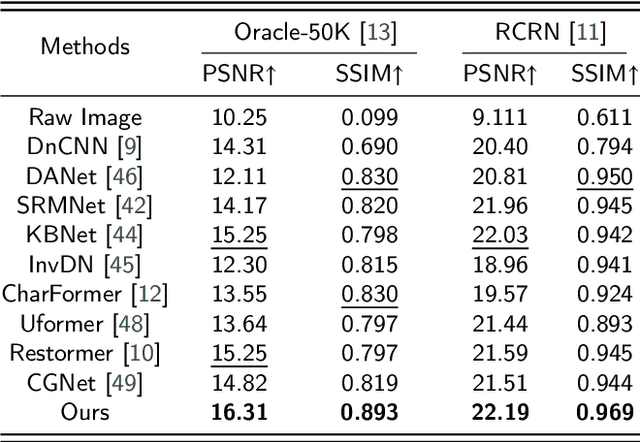
Oracle bone inscriptions (OBIs) are the earliest known form of Chinese characters and serve as a valuable resource for research in anthropology and archaeology. However, most excavated fragments are severely degraded due to thousands of years of natural weathering, corrosion, and man-made destruction, making automatic OBI recognition extremely challenging. Previous methods either focus on pixel-level information or utilize vanilla transformers for glyph-based OBI denoising, which leads to tremendous computational overhead. Therefore, this paper proposes a fast attentive denoising framework for oracle bone inscriptions, i.e., OBIFormer. It leverages channel-wise self-attention, glyph extraction, and selective kernel feature fusion to reconstruct denoised images precisely while being computationally efficient. Our OBIFormer achieves state-of-the-art denoising performance for PSNR and SSIM metrics on synthetic and original OBI datasets. Furthermore, comprehensive experiments on a real oracle dataset demonstrate the great potential of our OBIFormer in assisting automatic OBI recognition. The code will be made available at https://github.com/LJHolyGround/OBIFormer.
Mitigating Long-tail Distribution in Oracle Bone Inscriptions: Dataset, Model, and Benchmark
Apr 16, 2025The oracle bone inscription (OBI) recognition plays a significant role in understanding the history and culture of ancient China. However, the existing OBI datasets suffer from a long-tail distribution problem, leading to biased performance of OBI recognition models across majority and minority classes. With recent advancements in generative models, OBI synthesis-based data augmentation has become a promising avenue to expand the sample size of minority classes. Unfortunately, current OBI datasets lack large-scale structure-aligned image pairs for generative model training. To address these problems, we first present the Oracle-P15K, a structure-aligned OBI dataset for OBI generation and denoising, consisting of 14,542 images infused with domain knowledge from OBI experts. Second, we propose a diffusion model-based pseudo OBI generator, called OBIDiff, to achieve realistic and controllable OBI generation. Given a clean glyph image and a target rubbing-style image, it can effectively transfer the noise style of the original rubbing to the glyph image. Extensive experiments on OBI downstream tasks and user preference studies show the effectiveness of the proposed Oracle-P15K dataset and demonstrate that OBIDiff can accurately preserve inherent glyph structures while transferring authentic rubbing styles effectively.
OBI-Bench: Can LMMs Aid in Study of Ancient Script on Oracle Bones?
Dec 02, 2024



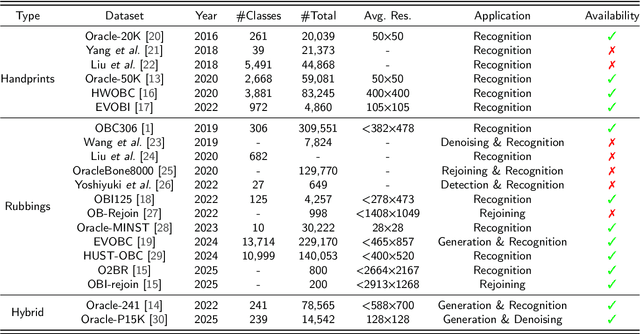
We introduce OBI-Bench, a holistic benchmark crafted to systematically evaluate large multi-modal models (LMMs) on whole-process oracle bone inscriptions (OBI) processing tasks demanding expert-level domain knowledge and deliberate cognition. OBI-Bench includes 5,523 meticulously collected diverse-sourced images, covering five key domain problems: recognition, rejoining, classification, retrieval, and deciphering. These images span centuries of archaeological findings and years of research by front-line scholars, comprising multi-stage font appearances from excavation to synthesis, such as original oracle bone, inked rubbings, oracle bone fragments, cropped single character, and handprinted character. Unlike existing benchmarks, OBI-Bench focuses on advanced visual perception and reasoning with OBI-specific knowledge, challenging LMMs to perform tasks akin to those faced by experts. The evaluation of 6 proprietary LMMs as well as 17 open-source LMMs highlights the substantial challenges and demands posed by OBI-Bench. Even the latest versions of GPT-4o, Gemini 1.5 Pro, and Qwen-VL-Max are still far from public-level humans in some fine-grained perception tasks. However, they perform at a level comparable to untrained humans in deciphering task, indicating remarkable capabilities in offering new interpretative perspectives and generating creative guesses. We hope OBI-Bench can facilitate the community to develop domain-specific multi-modal foundation models towards ancient language research and delve deeper to discover and enhance these untapped potentials of LMMs.