 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Universal Representation Property of Spiking Neural Networks
Dec 18, 2025Inspired by biology, spiking neural networks (SNNs) process information via discrete spikes over time, offering an energy-efficient alternative to the classical computing paradigm and classical artificial neural networks (ANNs). In this work, we analyze the representational power of SNNs by viewing them as sequence-to-sequence processors of spikes, i.e., systems that transform a stream of input spikes into a stream of output spikes. We establish the universal representation property for a natural class of spike train functions. Our results are fully quantitative, constructive, and near-optimal in the number of required weights and neurons. The analysis reveals that SNNs are particularly well-suited to represent functions with few inputs, low temporal complexity, or compositions of such functions. The latter is of particular interest, as it indicates that deep SNNs can efficiently capture composite functions via a modular design. As an application of our results, we discuss spike train classification. Overall, these results contribute to a rigorous foundation for understanding the capabilities and limitations of spike-based neuromorphic systems.
Spike-timing-dependent Hebbian learning as noisy gradient descent
May 15, 2025Hebbian learning is a key principle underlying learning in biological neural networks. It postulates that synaptic changes occur locally, depending on the activities of pre- and postsynaptic neurons. While Hebbian learning based on neuronal firing rates is well explored, much less is known about learning rules that account for precise spike-timing. We relate a Hebbian spike-timing-dependent plasticity rule to noisy gradient descent with respect to a natural loss function on the probability simplex. This connection allows us to prove that the learning rule eventually identifies the presynaptic neuron with the highest activity. We also discover an intrinsic connection to noisy mirror descent.
On the expressivity of deep Heaviside networks
Apr 30, 2025



We show that deep Heaviside networks (DHNs) have limited expressiveness but that this can be overcome by including either skip connections or neurons with linear activation. We provide lower and upper bounds for the Vapnik-Chervonenkis (VC) dimensions and approximation rates of these network classes. As an application, we derive statistical convergence rates for DHN fits in the nonparametric regression model.
Training Diagonal Linear Networks with Stochastic Sharpness-Aware Minimization
Mar 14, 2025We analyze the landscape and training dynamics of diagonal linear networks in a linear regression task, with the network parameters being perturbed by small isotropic normal noise. The addition of such noise may be interpreted as a stochastic form of sharpness-aware minimization (SAM) and we prove several results that relate its action on the underlying landscape and training dynamics to the sharpness of the loss. In particular, the noise changes the expected gradient to force balancing of the weight matrices at a fast rate along the descent trajectory. In the diagonal linear model, we show that this equates to minimizing the average sharpness, as well as the trace of the Hessian matrix, among all possible factorizations of the same matrix. Further, the noise forces the gradient descent iterates towards a shrinkage-thresholding of the underlying true parameter, with the noise level explicitly regulating both the shrinkage factor and the threshold.
Improving the Convergence Rates of Forward Gradient Descent with Repeated Sampling
Nov 26, 2024Forward gradient descent (FGD) has been proposed as a biologically more plausible alternative of gradient descent as it can be computed without backward pass. Considering the linear model with $d$ parameters, previous work has found that the prediction error of FGD is, however, by a factor $d$ slower than the prediction error of stochastic gradient descent (SGD). In this paper we show that by computing $\ell$ FGD steps based on each training sample, this suboptimality factor becomes $d/(\ell \wedge d)$ and thus the suboptimality of the rate disappears if $\ell \gtrsim d.$ We also show that FGD with repeated sampling can adapt to low-dimensional structure in the input distribution. The main mathematical challenge lies in controlling the dependencies arising from the repeated sampling process.
Understanding the Effect of GCN Convolutions in Regression Tasks
Oct 26, 2024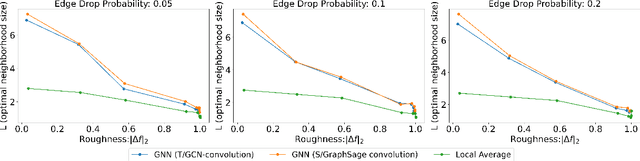
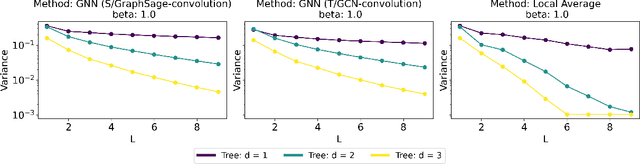
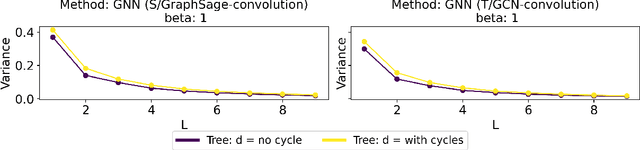
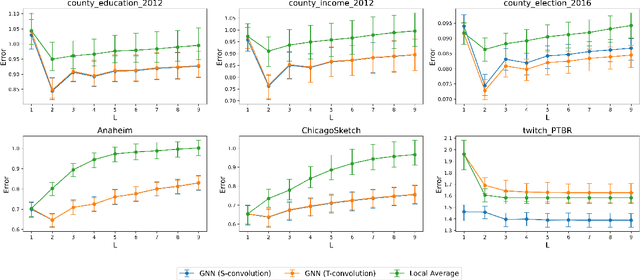
Graph Convolutional Networks (GCNs) have become a pivotal method in machine learning for modeling functions over graphs. Despite their widespread success across various applications, their statistical properties (e.g. consistency, convergence rates) remain ill-characterized. To begin addressing this knowledge gap, in this paper, we provide a formal analysis of the impact of convolution operators on regression tasks over homophilic networks. Focusing on estimators based solely on neighborhood aggregation, we examine how two common convolutions - the original GCN and GraphSage convolutions - affect the learning error as a function of the neighborhood topology and the number of convolutional layers. We explicitly characterize the bias-variance trade-off incurred by GCNs as a function of the neighborhood size and identify specific graph topologies where convolution operators are less effective. Our theoretical findings are corroborated by synthetic experiments, and provide a start to a deeper quantitative understanding of convolutional effects in GCNs for offering rigorous guidelines for practitioners.
On the VC dimension of deep group convolutional neural networks
Oct 21, 2024We study the generalization capabilities of Group Convolutional Neural Networks (GCNNs) with ReLU activation function by deriving upper and lower bounds for their Vapnik-Chervonenkis (VC) dimension. Specifically, we analyze how factors such as the number of layers, weights, and input dimension affect the VC dimension. We further compare the derived bounds to those known for other types of neural networks. Our findings extend previous results on the VC dimension of continuous GCNNs with two layers, thereby providing new insights into the generalization properties of GCNNs, particularly regarding the dependence on the input resolution of the data.
Asymptotics of Stochastic Gradient Descent with Dropout Regularization in Linear Models
Sep 11, 2024This paper proposes an asymptotic theory for online inference of the stochastic gradient descent (SGD) iterates with dropout regularization in linear regression. Specifically, we establish the geometric-moment contraction (GMC) for constant step-size SGD dropout iterates to show the existence of a unique stationary distribution of the dropout recursive function. By the GMC property, we provide quenched central limit theorems (CLT) for the difference between dropout and $\ell^2$-regularized iterates, regardless of initialization. The CLT for the difference between the Ruppert-Polyak averaged SGD (ASGD) with dropout and $\ell^2$-regularized iterates is also presented. Based on these asymptotic normality results, we further introduce an online estimator for the long-run covariance matrix of ASGD dropout to facilitate inference in a recursive manner with efficiency in computational time and memory. The numerical experiments demonstrate that for sufficiently large samples, the proposed confidence intervals for ASGD with dropout nearly achieve the nominal coverage probability.
Convergence guarantees for forward gradient descent in the linear regression model
Sep 26, 2023Renewed interest in the relationship between artificial and biological neural networks motivates the study of gradient-free methods. Considering the linear regression model with random design, we theoretically analyze in this work the biologically motivated (weight-perturbed) forward gradient scheme that is based on random linear combination of the gradient. If d denotes the number of parameters and k the number of samples, we prove that the mean squared error of this method converges for $k\gtrsim d^2\log(d)$ with rate $d^2\log(d)/k.$ Compared to the dimension dependence d for stochastic gradient descent, an additional factor $d\log(d)$ occurs.
Dropout Regularization Versus $\ell_2$-Penalization in the Linear Model
Jun 18, 2023We investigate the statistical behavior of gradient descent iterates with dropout in the linear regression model. In particular, non-asymptotic bounds for expectations and covariance matrices of the iterates are derived. In contrast with the widely cited connection between dropout and $\ell_2$-regularization in expectation, the results indicate a much more subtle relationship, owing to interactions between the gradient descent dynamics and the additional randomness induced by dropout. We also study a simplified variant of dropout which does not have a regularizing effect and converges to the least squares estimator.