 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting and Explaining Human Semantic Search in a Cognitive Model
Nov 29, 2017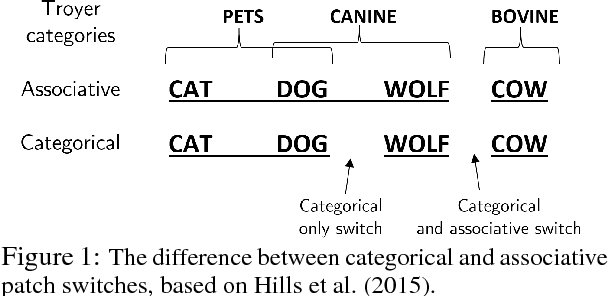

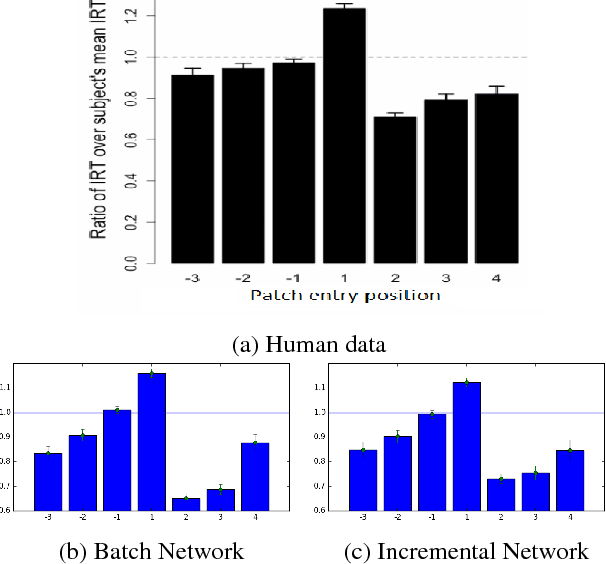
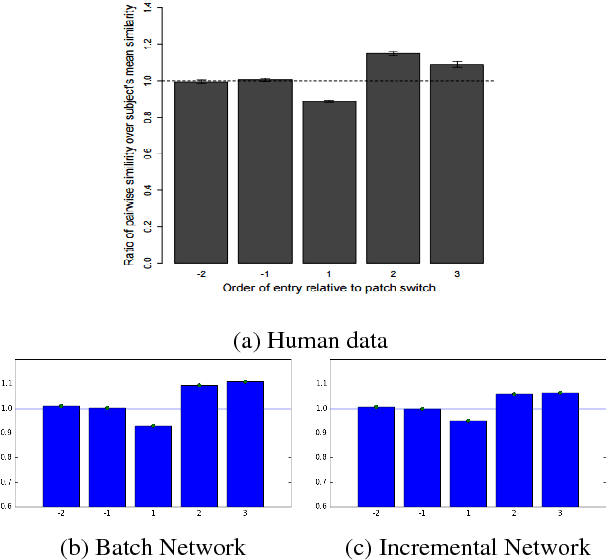
Recent work has attempted to characterize the structure of semantic memory and the search algorithms which, together, best approximate human patterns of search revealed in a semantic fluency task. There are a number of models that seek to capture semantic search processes over networks, but they vary in the cognitive plausibility of their implementation. Existing work has also neglected to consider the constraints that the incremental process of language acquisition must place on the structure of semantic memory. Here we present a model that incrementally updates a semantic network, with limited computational steps, and replicates many patterns found in human semantic fluency using a simple random walk. We also perform thorough analyses showing that a combination of both structural and semantic features are correlated with human performance patterns.
Simple Search Algorithms on Semantic Networks Learned from Language Use
Feb 11, 2016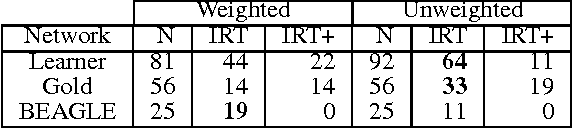
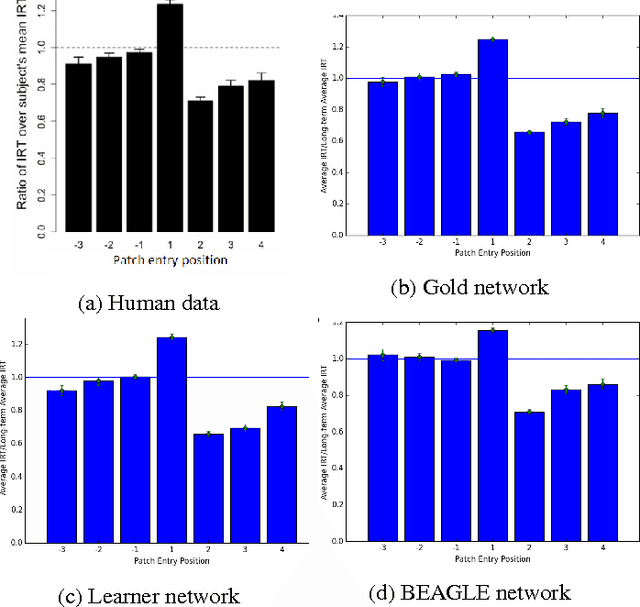
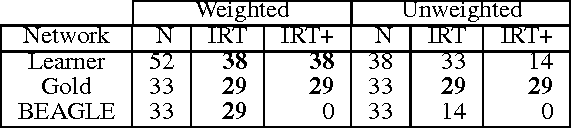
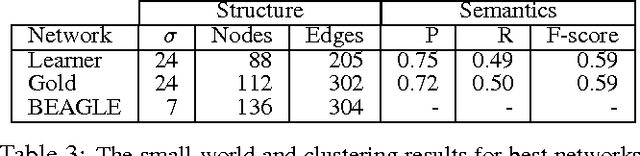
Recent empirical and modeling research has focused on the semantic fluency task because it is informative about semantic memory. An interesting interplay arises between the richness of representations in semantic memory and the complexity of algorithms required to process it. It has remained an open question whether representations of words and their relations learned from language use can enable a simple search algorithm to mimic the observed behavior in the fluency task. Here we show that it is plausible to learn rich representations from naturalistic data for which a very simple search algorithm (a random walk) can replicate the human patterns. We suggest that explicitly structuring knowledge about words into a semantic network plays a crucial role in modeling human behavior in memory search and retrieval; moreover, this is the case across a range of semantic information sources.