 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Imbalance Can Boost Cross-lingual Generalisation
Apr 11, 2024Multilinguality is crucial for extending recent advancements in language modelling to diverse linguistic communities. To maintain high performance while representing multiple languages, multilingual models ideally align representations, allowing what is learned in one language to generalise to others. Prior research has emphasised the importance of parallel data and shared vocabulary elements as key factors for such alignment. In this study, we investigate an unintuitive novel driver of cross-lingual generalisation: language imbalance. In controlled experiments on perfectly equivalent cloned languages, we observe that the existence of a predominant language during training boosts the performance of less frequent languages and leads to stronger alignment of model representations across languages. Furthermore, we find that this trend is amplified with scale: with large enough models or long enough training, we observe that bilingual training data with a 90/10 language split yields better performance on both languages than a balanced 50/50 split. Building on these insights, we design training schemes that can improve performance in all cloned languages, even without altering the training data. As we extend our analysis to real languages, we find that infrequent languages still benefit from frequent ones, yet whether language imbalance causes cross-lingual generalisation there is not conclusive.
On the Effect of Duplicate Subwords in Language Modelling
Apr 09, 2024



Tokenisation is a core part of language models (LMs). It involves splitting a character sequence into subwords which are assigned arbitrary indices before being served to the LM. While typically lossless, however, this process may lead to less sample efficient LM training: as it removes character-level information, it could make it harder for LMs to generalise across similar subwords, such as now and Now. We refer to such subwords as near duplicates. In this paper, we study the impact of near duplicate subwords on LM training efficiency. First, we design an experiment that gives us an upper bound to how much we should expect a model to improve if we could perfectly generalise across near duplicates. We do this by duplicating each subword in our LM's vocabulary, creating perfectly equivalent classes of subwords. Experimentally, we find that LMs need roughly 17% more data when trained in a fully duplicated setting. Second, we investigate the impact of naturally occurring near duplicates on LMs. Here, we see that merging them considerably hurts LM performance. Therefore, although subword duplication negatively impacts LM training efficiency, naturally occurring near duplicates may not be as similar as anticipated, limiting the potential for performance improvements.
Towards Automated Anamnesis Summarization: BERT-based Models for Symptom Extraction
Nov 03, 2020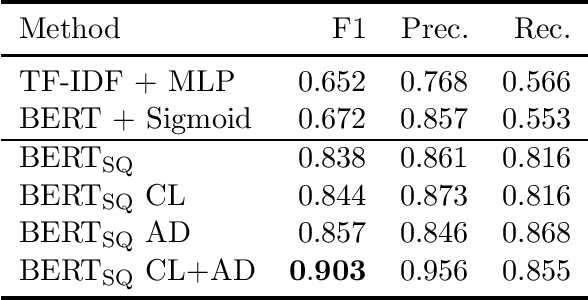
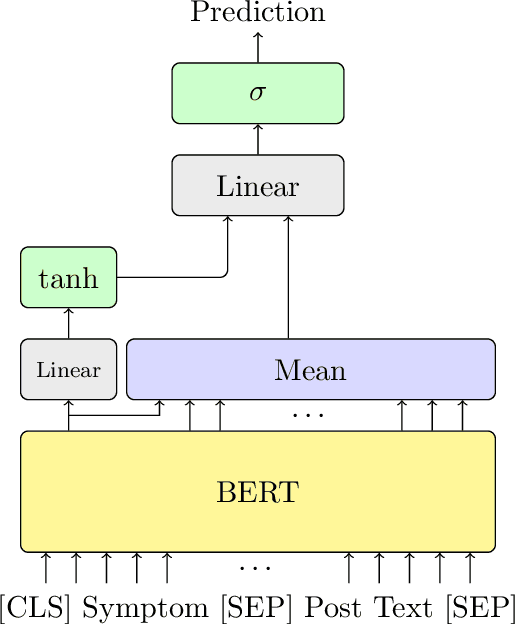
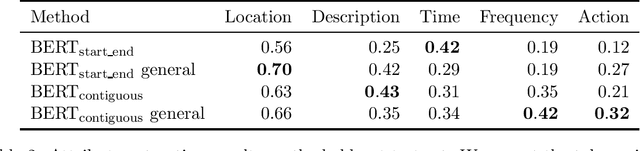
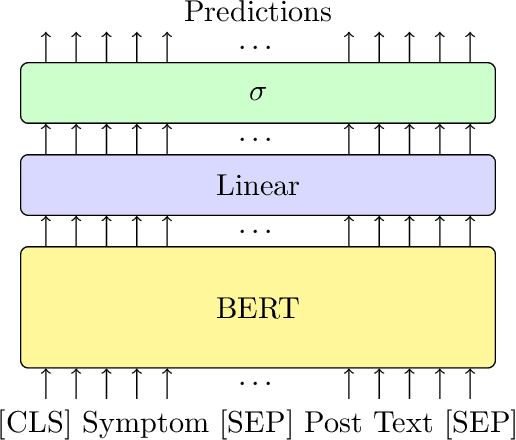
Professionals in modern healthcare systems are increasingly burdened by documentation workloads. Documentation of the initial patient anamnesis is particularly relevant, forming the basis of successful further diagnostic measures. However, manually prepared notes are inherently unstructured and often incomplete. In this paper, we investigate the potential of modern NLP techniques to support doctors in this matter. We present a dataset of German patient monologues, and formulate a well-defined information extraction task under the constraints of real-world utility and practicality. In addition, we propose BERT-based models in order to solve said task. We can demonstrate promising performance of the models in both symptom identification and symptom attribute extraction, significantly outperforming simpler baselines.