 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Affine Homotopy between Language Encoders
Paper and Code
Jun 04, 2024
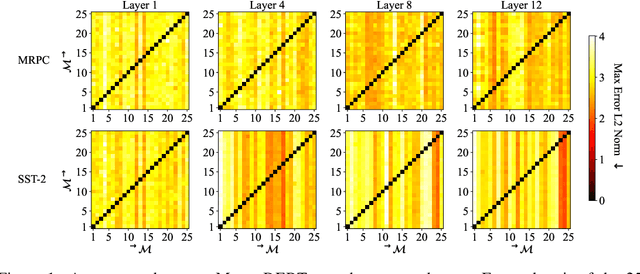
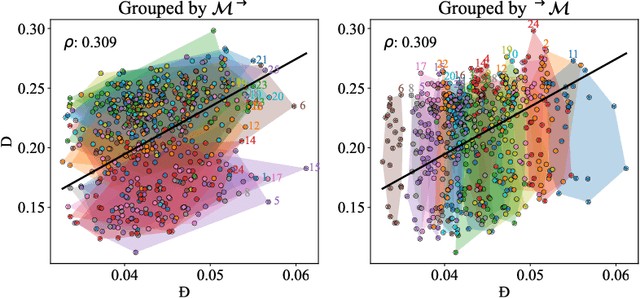
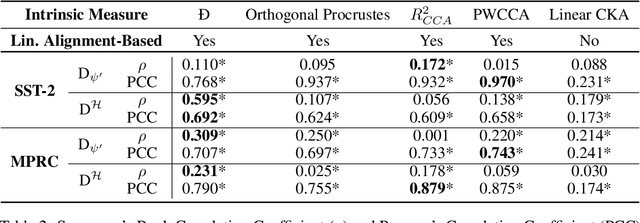
Pre-trained language encoders -- functions that represent text as vectors -- are an integral component of many NLP tasks. We tackle a natural question in language encoder analysis: What does it mean for two encoders to be similar? We contend that a faithful measure of similarity needs to be \emph{intrinsic}, that is, task-independent, yet still be informative of \emph{extrinsic} similarity -- the performance on downstream tasks. It is common to consider two encoders similar if they are \emph{homotopic}, i.e., if they can be aligned through some transformation. In this spirit, we study the properties of \emph{affine} alignment of language encoders and its implications on extrinsic similarity. We find that while affine alignment is fundamentally an asymmetric notion of similarity, it is still informative of extrinsic similarity. We confirm this on datasets of natural language representations. Beyond providing useful bounds on extrinsic similarity, affine intrinsic similarity also allows us to begin uncovering the structure of the space of pre-trained encoders by defining an order over them.