 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Free Recognition with Transformers
Jan 05, 2026Transformers excel on tasks that process well-formed inputs according to some grammar, such as natural language and code. However, it remains unclear how they can process grammatical syntax. In fact, under standard complexity conjectures, standard transformers cannot recognize context-free languages (CFLs), a canonical formalism to describe syntax, or even regular languages, a subclass of CFLs (Merrill et al., 2022). Merrill & Sabharwal (2024) show that $\mathcal{O}(\log n)$ looping layers (w.r.t. input length $n$) allows transformers to recognize regular languages, but the question of context-free recognition remained open. In this work, we show that looped transformers with $\mathcal{O}(\log n)$ looping layers and $\mathcal{O}(n^6)$ padding tokens can recognize all CFLs. However, training and inference with $\mathcal{O}(n^6)$ padding tokens is potentially impractical. Fortunately, we show that, for natural subclasses such as unambiguous CFLs, the recognition problem on transformers becomes more tractable, requiring $\mathcal{O}(n^3)$ padding. We empirically validate our results and show that looping helps on a language that provably requires logarithmic depth. Overall, our results shed light on the intricacy of CFL recognition by transformers: While general recognition may require an intractable amount of padding, natural constraints such as unambiguity yield efficient recognition algorithms.
Unique Hard Attention: A Tale of Two Sides
Mar 18, 2025
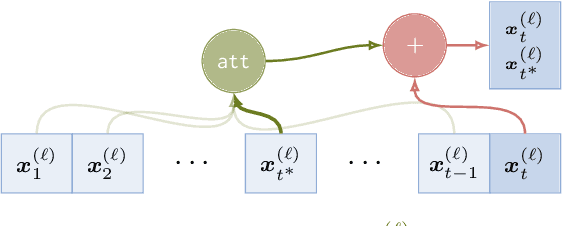
Understanding the expressive power of transformers has recently attracted attention, as it offers insights into their abilities and limitations. Many studies analyze unique hard attention transformers, where attention selects a single position that maximizes the attention scores. When multiple positions achieve the maximum score, either the rightmost or the leftmost of those is chosen. In this paper, we highlight the importance of this seeming triviality. Recently, finite-precision transformers with both leftmost- and rightmost-hard attention were shown to be equivalent to Linear Temporal Logic (LTL). We show that this no longer holds with only leftmost-hard attention -- in that case, they correspond to a \emph{strictly weaker} fragment of LTL. Furthermore, we show that models with leftmost-hard attention are equivalent to \emph{soft} attention, suggesting they may better approximate real-world transformers than right-attention models. These findings refine the landscape of transformer expressivity and underscore the role of attention directionality.