 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpandable Decision-Making States for Multi-Agent Deep Reinforcement Learning in Soccer Tactical Analysis
Oct 01, 2025Invasion team sports such as soccer produce a high-dimensional, strongly coupled state space as many players continuously interact on a shared field, challenging quantitative tactical analysis. Traditional rule-based analyses are intuitive, while modern predictive machine learning models often perform pattern-matching without explicit agent representations. The problem we address is how to build player-level agent models from data, whose learned values and policies are both tactically interpretable and robust across heterogeneous data sources. Here, we propose Expandable Decision-Making States (EDMS), a semantically enriched state representation that augments raw positions and velocities with relational variables (e.g., scoring of space, pass, and score), combined with an action-masking scheme that gives on-ball and off-ball agents distinct decision sets. Compared to prior work, EDMS maps learned value functions and action policies to human-interpretable tactical concepts (e.g., marking pressure, passing lanes, ball accessibility) instead of raw coordinate features, and aligns agent choices with the rules of play. In the experiments, EDMS with action masking consistently reduced both action-prediction loss and temporal-difference (TD) error compared to the baseline. Qualitative case studies and Q-value visualizations further indicate that EDMS highlights high-risk, high-reward tactical patterns (e.g., fast counterattacks and defensive breakthroughs). We also integrated our approach into an open-source library and demonstrated compatibility with multiple commercial and open datasets, enabling cross-provider evaluation and reproducible experiments.
Information Locality as an Inductive Bias for Neural Language Models
Jun 05, 2025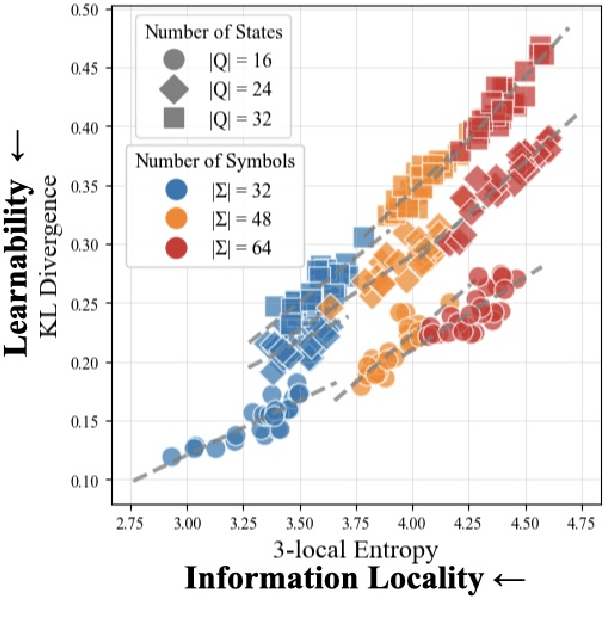
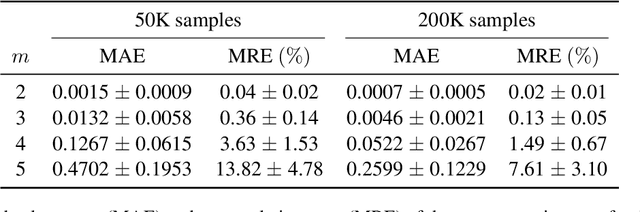
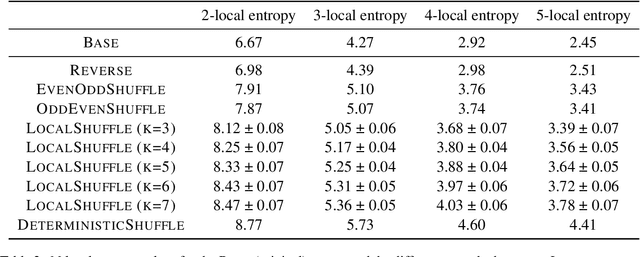
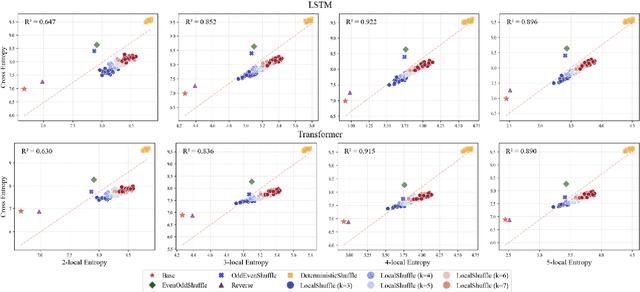
Inductive biases are inherent in every machine learning system, shaping how models generalize from finite data. In the case of neural language models (LMs), debates persist as to whether these biases align with or diverge from human processing constraints. To address this issue, we propose a quantitative framework that allows for controlled investigations into the nature of these biases. Within our framework, we introduce $m$-local entropy$\unicode{x2013}$an information-theoretic measure derived from average lossy-context surprisal$\unicode{x2013}$that captures the local uncertainty of a language by quantifying how effectively the $m-1$ preceding symbols disambiguate the next symbol. In experiments on both perturbed natural language corpora and languages defined by probabilistic finite-state automata (PFSAs), we show that languages with higher $m$-local entropy are more difficult for Transformer and LSTM LMs to learn. These results suggest that neural LMs, much like humans, are highly sensitive to the local statistical structure of a language.
If Attention Serves as a Cognitive Model of Human Memory Retrieval, What is the Plausible Memory Representation?
Feb 17, 2025Recent work in computational psycholinguistics has revealed intriguing parallels between attention mechanisms and human memory retrieval, focusing primarily on Transformer architectures that operate on token-level representations. However, computational psycholinguistic research has also established that syntactic structures provide compelling explanations for human sentence processing that word-level factors alone cannot fully account for. In this study, we investigate whether the attention mechanism of Transformer Grammar (TG), which uniquely operates on syntactic structures as representational units, can serve as a cognitive model of human memory retrieval, using Normalized Attention Entropy (NAE) as a linking hypothesis between model behavior and human processing difficulty. Our experiments demonstrate that TG's attention achieves superior predictive power for self-paced reading times compared to vanilla Transformer's, with further analyses revealing independent contributions from both models. These findings suggest that human sentence processing involves dual memory representations -- one based on syntactic structures and another on token sequences -- with attention serving as the general retrieval algorithm, while highlighting the importance of incorporating syntactic structures as representational units.
OpenSTARLab: Open Approach for Spatio-Temporal Agent Data Analysis in Soccer
Feb 06, 2025



Sports analytics has become both more professional and sophisticated, driven by the growing availability of detailed performance data. This progress enables applications such as match outcome prediction, player scouting, and tactical analysis. In soccer, the effective utilization of event and tracking data is fundamental for capturing and analyzing the dynamics of the game. However, there are two primary challenges: the limited availability of event data, primarily restricted to top-tier teams and leagues, and the scarcity and high cost of tracking data, which complicates its integration with event data for comprehensive analysis. Here we propose OpenSTARLab, an open-source framework designed to democratize spatio-temporal agent data analysis in sports by addressing these key challenges. OpenSTARLab includes the Pre-processing Package that standardizes event and tracking data through Unified and Integrated Event Data and State-Action-Reward formats, the Event Modeling Package that implements deep learning-based event prediction, alongside the RLearn Package for reinforcement learning tasks. These technical components facilitate the handling of diverse data sources and support advanced analytical tasks, thereby enhancing the overall functionality and usability of the framework. To assess OpenSTARLab's effectiveness, we conducted several experimental evaluations. These demonstrate the superior performance of the specific event prediction model in terms of action and time prediction accuracies and maintained its robust event simulation performance. Furthermore, reinforcement learning experiments reveal a trade-off between action accuracy and temporal difference loss and show comprehensive visualization. Overall, OpenSTARLab serves as a robust platform for researchers and practitioners, enhancing innovation and collaboration in the field of soccer data analytics.
Tree-Planted Transformers: Large Language Models with Implicit Syntactic Supervision
Feb 20, 2024Large Language Models (LLMs) have achieved remarkable success thanks to scalability on large text corpora, but have some drawback in training efficiency. In contrast, Syntactic Language Models (SLMs) can be trained efficiently to reach relatively high performance thanks to syntactic supervision, but have trouble with scalability. Thus, given these complementary advantages of LLMs and SLMs, it is necessary to develop an architecture that integrates the scalability of LLMs with the training efficiency of SLMs, namely Syntactic Large Language Models (SLLM). In this paper, we propose a novel method dubbed tree-planting: implicitly "plant" trees into attention weights of Transformer LMs to reflect syntactic structures of natural language. Specifically, Transformer LMs trained with tree-planting will be called Tree-Planted Transformers (TPT), which learn syntax on small treebanks via tree-planting and then scale on large text corpora via continual learning with syntactic scaffolding. Targeted syntactic evaluations on the SyntaxGym benchmark demonstrated that TPTs, despite the lack of explicit syntactic supervision, significantly outperformed various SLMs with explicit syntactic supervision that generate hundreds of syntactic structures in parallel, suggesting that tree-planting and TPTs are the promising foundation for SLLMs.
JCoLA: Japanese Corpus of Linguistic Acceptability
Sep 22, 2023



Neural language models have exhibited outstanding performance in a range of downstream tasks. However, there is limited understanding regarding the extent to which these models internalize syntactic knowledge, so that various datasets have recently been constructed to facilitate syntactic evaluation of language models across languages. In this paper, we introduce JCoLA (Japanese Corpus of Linguistic Acceptability), which consists of 10,020 sentences annotated with binary acceptability judgments. Specifically, those sentences are manually extracted from linguistics textbooks, handbooks and journal articles, and split into in-domain data (86 %; relatively simple acceptability judgments extracted from textbooks and handbooks) and out-of-domain data (14 %; theoretically significant acceptability judgments extracted from journal articles), the latter of which is categorized by 12 linguistic phenomena. We then evaluate the syntactic knowledge of 9 different types of Japanese language models on JCoLA. The results demonstrated that several models could surpass human performance for the in-domain data, while no models were able to exceed human performance for the out-of-domain data. Error analyses by linguistic phenomena further revealed that although neural language models are adept at handling local syntactic dependencies like argument structure, their performance wanes when confronted with long-distance syntactic dependencies like verbal agreement and NPI licensing.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.