 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch and Detect: Training-Free Long Tail Object Detection via Web-Image Retrieval
Sep 26, 2024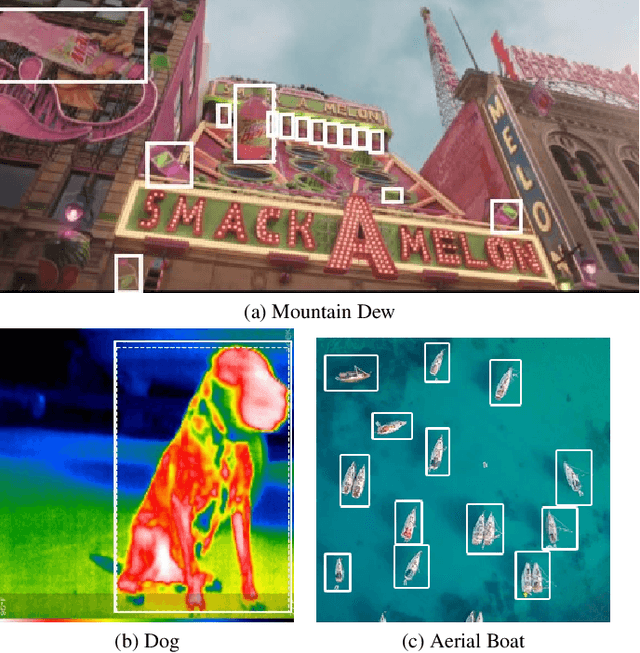
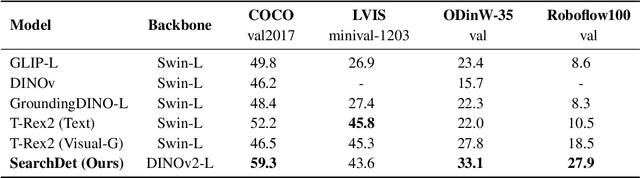
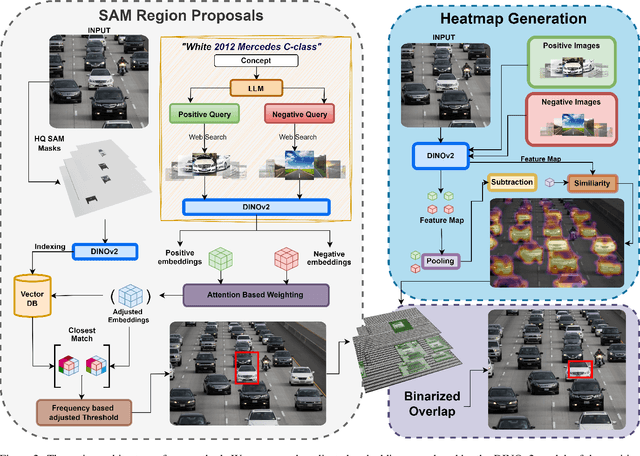
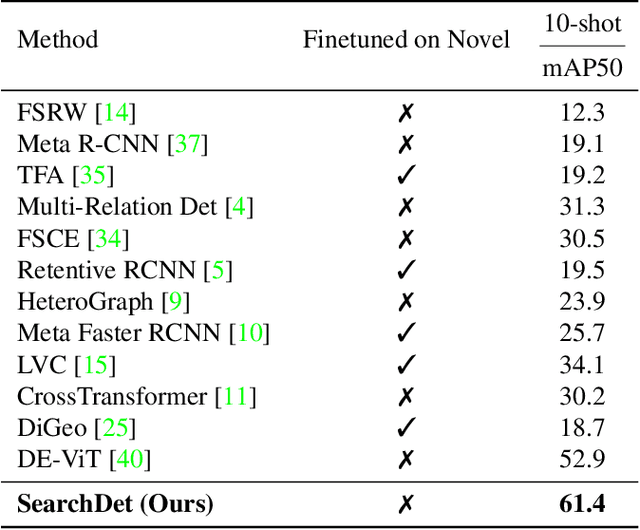
In this paper, we introduce SearchDet, a training-free long-tail object detection framework that significantly enhances open-vocabulary object detection performance. SearchDet retrieves a set of positive and negative images of an object to ground, embeds these images, and computes an input image-weighted query which is used to detect the desired concept in the image. Our proposed method is simple and training-free, yet achieves over 48.7% mAP improvement on ODinW and 59.1% mAP improvement on LVIS compared to state-of-the-art models such as GroundingDINO. We further show that our approach of basing object detection on a set of Web-retrieved exemplars is stable with respect to variations in the exemplars, suggesting a path towards eliminating costly data annotation and training procedures.
C-PMI: Conditional Pointwise Mutual Information for Turn-level Dialogue Evaluation
Jun 27, 2023
Existing reference-free turn-level evaluation metrics for chatbots inadequately capture the interaction between the user and the system. Consequently, they often correlate poorly with human evaluations. To address this issue, we propose a novel model-agnostic approach that leverages Conditional Pointwise Mutual Information (C-PMI) to measure the turn-level interaction between the system and the user based on a given evaluation dimension. Experimental results on the widely used FED dialogue evaluation dataset demonstrate that our approach significantly improves the correlation with human judgment compared with existing evaluation systems. By replacing the negative log-likelihood-based scorer with our proposed C-PMI scorer, we achieve a relative 60.5% higher Spearman correlation on average for the FED evaluation metric. Our code is publicly available at https://github.com/renll/C-PMI.
Meta-review Generation with Checklist-guided Iterative Introspection
May 24, 2023Opinions in the scientific domain can be divergent, leading to controversy or consensus among reviewers. However, current opinion summarization datasets mostly focus on product review domains, which do not account for this variability under the assumption that the input opinions are non-controversial. To address this gap, we propose the task of scientific opinion summarization, where research paper reviews are synthesized into meta-reviews. To facilitate this task, we introduce a new ORSUM dataset covering 10,989 paper meta-reviews and 40,903 paper reviews from 39 conferences. Furthermore, we propose the Checklist-guided Iterative Introspection (CGI$^2$) approach, which breaks down the task into several stages and iteratively refines the summary under the guidance of questions from a checklist. We conclude that (1) human-written summaries are not always reliable since many do not follow the guideline, and (2) the combination of task decomposition and iterative self-refinement shows promising discussion involvement ability and can be applied to other complex text generation using black-box LLM.