 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Seed-Guided Topic Discovery by Integrating Multiple Types of Contexts
Dec 12, 2022Instead of mining coherent topics from a given text corpus in a completely unsupervised manner, seed-guided topic discovery methods leverage user-provided seed words to extract distinctive and coherent topics so that the mined topics can better cater to the user's interest. To model the semantic correlation between words and seeds for discovering topic-indicative terms, existing seed-guided approaches utilize different types of context signals, such as document-level word co-occurrences, sliding window-based local contexts, and generic linguistic knowledge brought by pre-trained language models. In this work, we analyze and show empirically that each type of context information has its value and limitation in modeling word semantics under seed guidance, but combining three types of contexts (i.e., word embeddings learned from local contexts, pre-trained language model representations obtained from general-domain training, and topic-indicative sentences retrieved based on seed information) allows them to complement each other for discovering quality topics. We propose an iterative framework, SeedTopicMine, which jointly learns from the three types of contexts and gradually fuses their context signals via an ensemble ranking process. Under various sets of seeds and on multiple datasets, SeedTopicMine consistently yields more coherent and accurate topics than existing seed-guided topic discovery approaches.
Entity Set Co-Expansion in StackOverflow
Dec 05, 2022
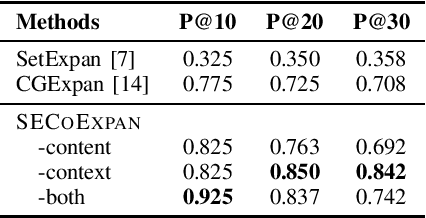
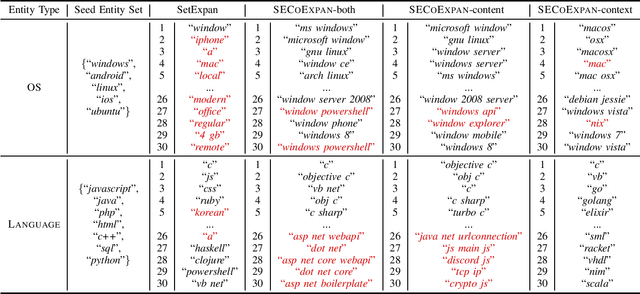
Given a few seed entities of a certain type (e.g., Software or Programming Language), entity set expansion aims to discover an extensive set of entities that share the same type as the seeds. Entity set expansion in software-related domains such as StackOverflow can benefit many downstream tasks (e.g., software knowledge graph construction) and facilitate better IT operations and service management. Meanwhile, existing approaches are less concerned with two problems: (1) How to deal with multiple types of seed entities simultaneously? (2) How to leverage the power of pre-trained language models (PLMs)? Being aware of these two problems, in this paper, we study the entity set co-expansion task in StackOverflow, which extracts Library, OS, Application, and Language entities from StackOverflow question-answer threads. During the co-expansion process, we use PLMs to derive embeddings of candidate entities for calculating similarities between entities. Experimental results show that our proposed SECoExpan framework outperforms previous approaches significantly.
Tuning Language Models as Training Data Generators for Augmentation-Enhanced Few-Shot Learning
Nov 06, 2022Recent studies have revealed the intriguing few-shot learning ability of pretrained language models (PLMs): They can quickly adapt to a new task when fine-tuned on a small amount of labeled data formulated as prompts, without requiring abundant task-specific annotations. Despite their promising performance, most existing few-shot approaches that only learn from the small training set still underperform fully supervised training by nontrivial margins. In this work, we study few-shot learning with PLMs from a different perspective: We first tune an autoregressive PLM on the few-shot samples and then use it as a generator to synthesize a large amount of novel training samples which augment the original training set. To encourage the generator to produce label-discriminative samples, we train it via weighted maximum likelihood where the weight of each token is automatically adjusted based on a discriminative meta-learning objective. A classification PLM can then be fine-tuned on both the few-shot and the synthetic samples with regularization for better generalization and stability. Our approach FewGen achieves an overall better result across seven classification tasks of the GLUE benchmark than existing few-shot learning methods, improving no-augmentation methods by 5+ average points, and outperforming augmentation methods by 3+ average points.