 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEED: Feature-level Ensemble for Knowledge Distillation
Paper and Code
Sep 24, 2019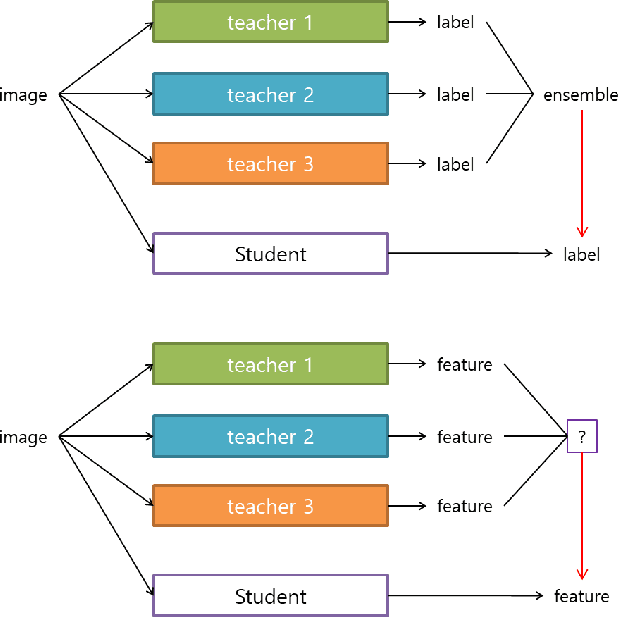
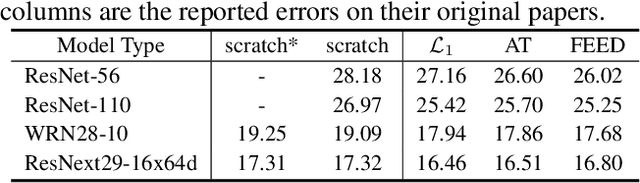
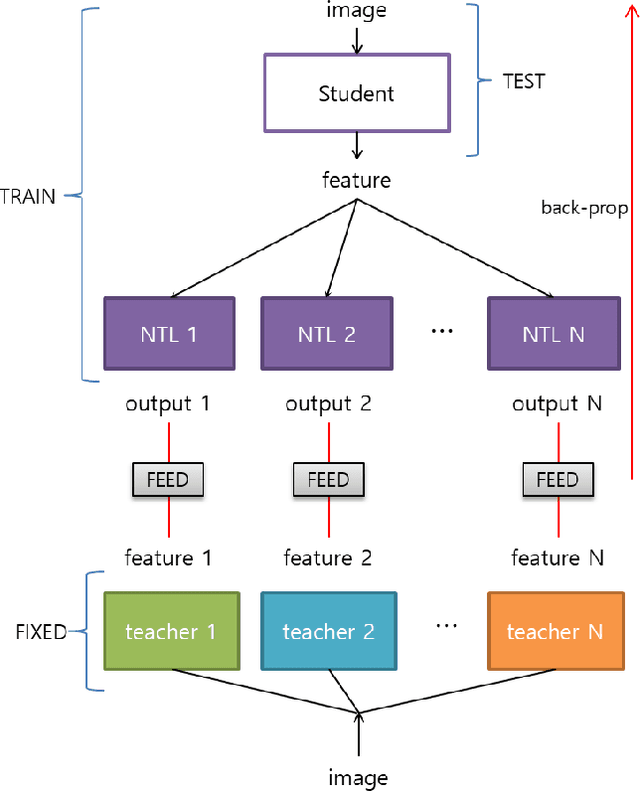

Knowledge Distillation (KD) aims to transfer knowledge in a teacher-student framework, by providing the predictions of the teacher network to the student network in the training stage to help the student network generalize better. It can use either a teacher with high capacity or {an} ensemble of multiple teachers. However, the latter is not convenient when one wants to use feature-map-based distillation methods. For a solution, this paper proposes a versatile and powerful training algorithm named FEature-level Ensemble for knowledge Distillation (FEED), which aims to transfer the ensemble knowledge using multiple teacher networks. We introduce a couple of training algorithms that transfer ensemble knowledge to the student at the feature map level. Among the feature-map-based distillation methods, using several non-linear transformations in parallel for transferring the knowledge of the multiple teacher{s} helps the student find more generalized solutions. We name this method as parallel FEED, andexperimental results on CIFAR-100 and ImageNet show that our method has clear performance enhancements, without introducing any additional parameters or computations at test time. We also show the experimental results of sequentially feeding teacher's information to the student, hence the name sequential FEED, and discuss the lessons obtained. Additionally, the empirical results on measuring the reconstruction errors at the feature map give hints for the enhancements.