 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Beyond Identification: Multi-bit Watermark for Language Models
Paper and Code
Aug 01, 2023


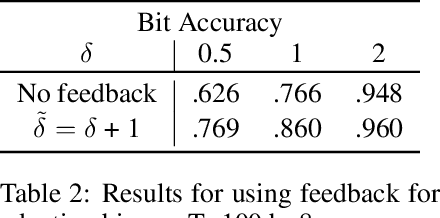
This study aims to proactively tackle misuse of large language models beyond identification of machine-generated text. While existing methods focus on detection, some malicious misuses demand tracing the adversary user for counteracting them. To address this, we propose "Multi-bit Watermark through Color-listing" (COLOR), embedding traceable multi-bit information during language model generation. Leveraging the benefits of zero-bit watermarking (Kirchenbauer et al., 2023a), COLOR enables extraction without model access, on-the-fly embedding, and maintains text quality, while allowing zero-bit detection all at the same time. Preliminary experiments demonstrates successful embedding of 32-bit messages with 91.9% accuracy in moderate-length texts ($\sim$500 tokens). This work advances strategies to counter language model misuse effectively.