 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Attacks in Federated Learning by Rare Embeddings and Gradient Ensembling
Paper and Code
Apr 29, 2022
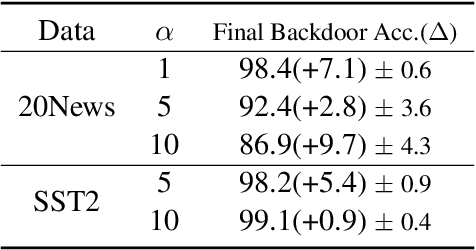
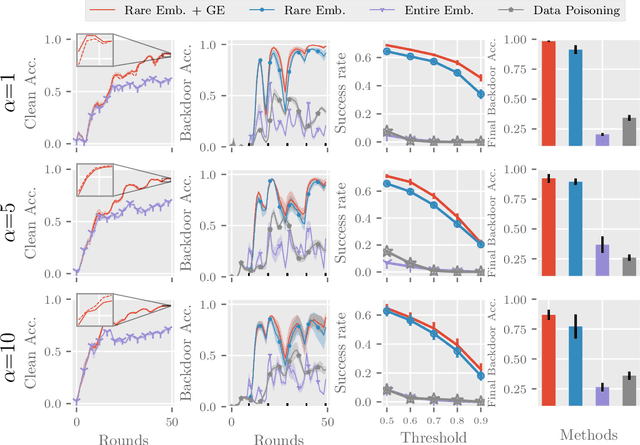

Recent advances in federated learning have demonstrated its promising capability to learn on decentralized datasets. However, a considerable amount of work has raised concerns due to the potential risks of adversaries participating in the framework to poison the global model for an adversarial purpose. This paper investigates the feasibility of model poisoning for backdoor attacks through \textit{rare word embeddings of NLP models} in text classification and sequence-to-sequence tasks. In text classification, less than 1\% of adversary clients suffices to manipulate the model output without any drop in the performance of clean sentences. For a less complex dataset, a mere 0.1\% of adversary clients is enough to poison the global model effectively. We also propose a technique specialized in the federated learning scheme called gradient ensemble, which enhances the backdoor performance in all experimental settings.