 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Vision-Language Representation Space with Single-tower Transformer
Paper and Code
Nov 21, 2022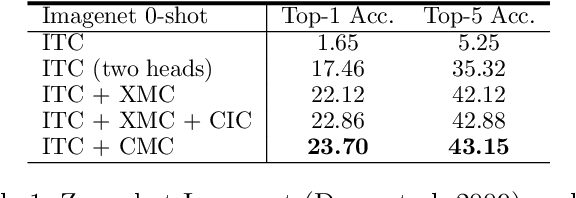
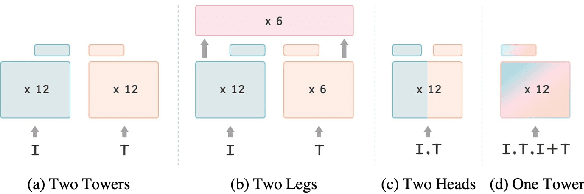
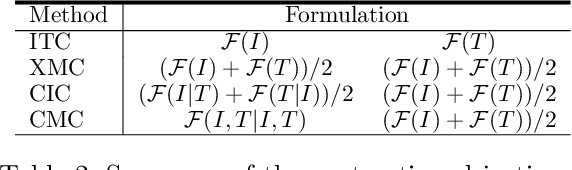

Contrastive learning is a form of distance learning that aims to learn invariant features from two related representations. In this paper, we explore the bold hypothesis that an image and its caption can be simply regarded as two different views of the underlying mutual information, and train a model to learn a unified vision-language representation space that encodes both modalities at once in a modality-agnostic manner. We first identify difficulties in learning a generic one-tower model for vision-language pretraining (VLP), and propose OneR as a simple yet effective framework for our goal. We discover intriguing properties that distinguish OneR from the previous works that learn modality-specific representation spaces such as zero-shot object localization, text-guided visual reasoning and multi-modal retrieval, and present analyses to provide insights into this new form of multi-modal representation learning. Thorough evaluations demonstrate the potential of a unified modality-agnostic VLP framework.