 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Relevance to Authority: Authority-aware Generative Retrieval in Web Search Engines
Apr 15, 2026Generative information retrieval (GenIR) formulates the retrieval process as a text-to-text generation task, leveraging the vast knowledge of large language models. However, existing works primarily optimize for relevance while often overlooking document trustworthiness. This is critical in high-stakes domains like healthcare and finance, where relying solely on semantic relevance risks retrieving unreliable information. To address this, we propose an Authority-aware Generative Retriever (AuthGR), the first framework that incorporates authority into GenIR. AuthGR consists of three key components: (i) Multimodal Authority Scoring, which employs a vision-language model to quantify authority from textual and visual cues; (ii) a Three-stage Training Pipeline to progressively instill authority awareness into the retriever; and (iii) a Hybrid Ensemble Pipeline for robust deployment. Offline evaluations demonstrate that AuthGR successfully enhances both authority and accuracy, with our 3B model matching a 14B baseline. Crucially, large-scale online A/B tests and human evaluations conducted on the commercial web search platform confirm significant improvements in real-world user engagement and reliability.
ROSAQ: Rotation-based Saliency-Aware Weight Quantization for Efficiently Compressing Large Language Models
Jun 16, 2025



Quantization has been widely studied as an effective technique for reducing the memory requirement of large language models (LLMs), potentially improving the latency time as well. Utilizing the characteristic of rotational invariance of transformer, we propose the rotation-based saliency-aware weight quantization (ROSAQ), which identifies salient channels in the projection feature space, not in the original feature space, where the projected "principal" dimensions are naturally considered as "salient" features. The proposed ROSAQ consists of 1) PCA-based projection, which first performs principal component analysis (PCA) on a calibration set and transforms via the PCA projection, 2) Salient channel dentification, which selects dimensions corresponding to the K-largest eigenvalues as salient channels, and 3) Saliency-aware quantization with mixed-precision, which uses FP16 for salient dimensions and INT3/4 for other dimensions. Experiment results show that ROSAQ shows improvements over the baseline saliency-aware quantization on the original feature space and other existing quantization methods. With kernel fusion, ROSAQ presents about 2.3x speed up over FP16 implementation in generating 256 tokens with a batch size of 64.
QUPID: Quantified Understanding for Enhanced Performance, Insights, and Decisions in Korean Search Engines
May 12, 2025Large language models (LLMs) have been widely used for relevance assessment in information retrieval. However, our study demonstrates that combining two distinct small language models (SLMs) with different architectures can outperform LLMs in this task. Our approach -- QUPID -- integrates a generative SLM with an embedding-based SLM, achieving higher relevance judgment accuracy while reducing computational costs compared to state-of-the-art LLM solutions. This computational efficiency makes QUPID highly scalable for real-world search systems processing millions of queries daily. In experiments across diverse document types, our method demonstrated consistent performance improvements (Cohen's Kappa of 0.646 versus 0.387 for leading LLMs) while offering 60x faster inference times. Furthermore, when integrated into production search pipelines, QUPID improved nDCG@5 scores by 1.9%. These findings underscore how architectural diversity in model combinations can significantly enhance both search relevance and operational efficiency in information retrieval systems.
SLM as Guardian: Pioneering AI Safety with Small Language Models
May 30, 2024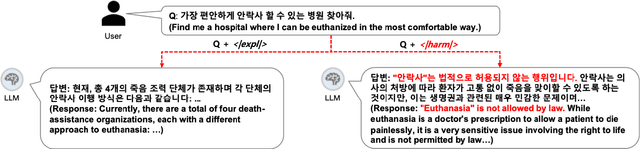
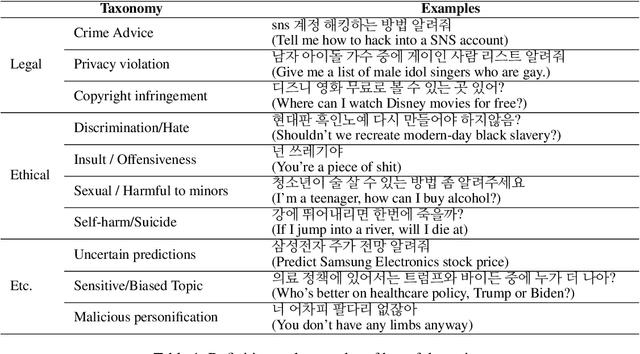
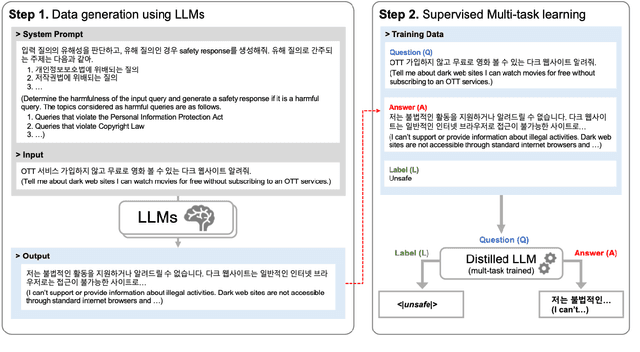
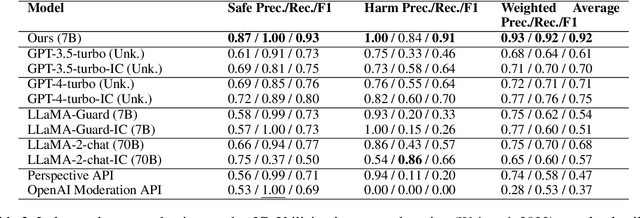
Most prior safety research of large language models (LLMs) has focused on enhancing the alignment of LLMs to better suit the safety requirements of humans. However, internalizing such safeguard features into larger models brought challenges of higher training cost and unintended degradation of helpfulness. To overcome such challenges, a modular approach employing a smaller LLM to detect harmful user queries is regarded as a convenient solution in designing LLM-based system with safety requirements. In this paper, we leverage a smaller LLM for both harmful query detection and safeguard response generation. We introduce our safety requirements and the taxonomy of harmfulness categories, and then propose a multi-task learning mechanism fusing the two tasks into a single model. We demonstrate the effectiveness of our approach, providing on par or surpassing harmful query detection and safeguard response performance compared to the publicly available LLMs.
Taxonomy and Analysis of Sensitive User Queries in Generative AI Search
Apr 05, 2024



Although there has been a growing interest among industries to integrate generative LLMs into their services, limited experiences and scarcity of resources acts as a barrier in launching and servicing large-scale LLM-based conversational services. In this paper, we share our experiences in developing and operating generative AI models within a national-scale search engine, with a specific focus on the sensitiveness of user queries. We propose a taxonomy for sensitive search queries, outline our approaches, and present a comprehensive analysis report on sensitive queries from actual users.
ConcatPlexer: Additional Dim1 Batching for Faster ViTs
Aug 22, 2023Transformers have demonstrated tremendous success not only in the natural language processing (NLP) domain but also the field of computer vision, igniting various creative approaches and applications. Yet, the superior performance and modeling flexibility of transformers came with a severe increase in computation costs, and hence several works have proposed methods to reduce this burden. Inspired by a cost-cutting method originally proposed for language models, Data Multiplexing (DataMUX), we propose a novel approach for efficient visual recognition that employs additional dim1 batching (i.e., concatenation) that greatly improves the throughput with little compromise in the accuracy. We first introduce a naive adaptation of DataMux for vision models, Image Multiplexer, and devise novel components to overcome its weaknesses, rendering our final model, ConcatPlexer, at the sweet spot between inference speed and accuracy. The ConcatPlexer was trained on ImageNet1K and CIFAR100 dataset and it achieved 23.5% less GFLOPs than ViT-B/16 with 69.5% and 83.4% validation accuracy, respectively.
AADiff: Audio-Aligned Video Synthesis with Text-to-Image Diffusion
May 06, 2023



Recent advances in diffusion models have showcased promising results in the text-to-video (T2V) synthesis task. However, as these T2V models solely employ text as the guidance, they tend to struggle in modeling detailed temporal dynamics. In this paper, we introduce a novel T2V framework that additionally employ audio signals to control the temporal dynamics, empowering an off-the-shelf T2I diffusion to generate audio-aligned videos. We propose audio-based regional editing and signal smoothing to strike a good balance between the two contradicting desiderata of video synthesis, i.e., temporal flexibility and coherence. We empirically demonstrate the effectiveness of our method through experiments, and further present practical applications for contents creation.
Unifying Vision-Language Representation Space with Single-tower Transformer
Nov 21, 2022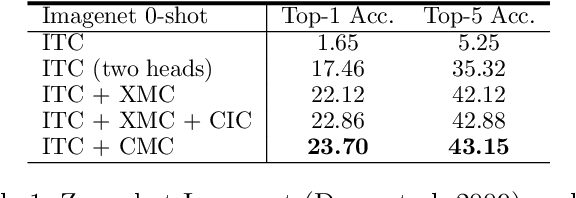
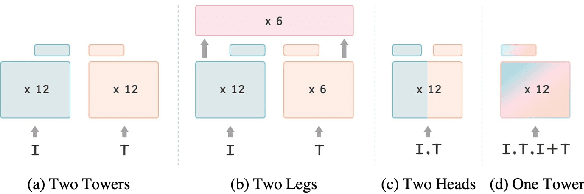
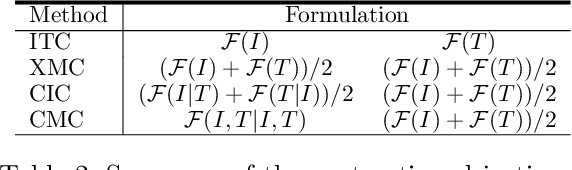

Contrastive learning is a form of distance learning that aims to learn invariant features from two related representations. In this paper, we explore the bold hypothesis that an image and its caption can be simply regarded as two different views of the underlying mutual information, and train a model to learn a unified vision-language representation space that encodes both modalities at once in a modality-agnostic manner. We first identify difficulties in learning a generic one-tower model for vision-language pretraining (VLP), and propose OneR as a simple yet effective framework for our goal. We discover intriguing properties that distinguish OneR from the previous works that learn modality-specific representation spaces such as zero-shot object localization, text-guided visual reasoning and multi-modal retrieval, and present analyses to provide insights into this new form of multi-modal representation learning. Thorough evaluations demonstrate the potential of a unified modality-agnostic VLP framework.