 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Relevance to Authority: Authority-aware Generative Retrieval in Web Search Engines
Apr 15, 2026Generative information retrieval (GenIR) formulates the retrieval process as a text-to-text generation task, leveraging the vast knowledge of large language models. However, existing works primarily optimize for relevance while often overlooking document trustworthiness. This is critical in high-stakes domains like healthcare and finance, where relying solely on semantic relevance risks retrieving unreliable information. To address this, we propose an Authority-aware Generative Retriever (AuthGR), the first framework that incorporates authority into GenIR. AuthGR consists of three key components: (i) Multimodal Authority Scoring, which employs a vision-language model to quantify authority from textual and visual cues; (ii) a Three-stage Training Pipeline to progressively instill authority awareness into the retriever; and (iii) a Hybrid Ensemble Pipeline for robust deployment. Offline evaluations demonstrate that AuthGR successfully enhances both authority and accuracy, with our 3B model matching a 14B baseline. Crucially, large-scale online A/B tests and human evaluations conducted on the commercial web search platform confirm significant improvements in real-world user engagement and reliability.
ROSAQ: Rotation-based Saliency-Aware Weight Quantization for Efficiently Compressing Large Language Models
Jun 16, 2025



Quantization has been widely studied as an effective technique for reducing the memory requirement of large language models (LLMs), potentially improving the latency time as well. Utilizing the characteristic of rotational invariance of transformer, we propose the rotation-based saliency-aware weight quantization (ROSAQ), which identifies salient channels in the projection feature space, not in the original feature space, where the projected "principal" dimensions are naturally considered as "salient" features. The proposed ROSAQ consists of 1) PCA-based projection, which first performs principal component analysis (PCA) on a calibration set and transforms via the PCA projection, 2) Salient channel dentification, which selects dimensions corresponding to the K-largest eigenvalues as salient channels, and 3) Saliency-aware quantization with mixed-precision, which uses FP16 for salient dimensions and INT3/4 for other dimensions. Experiment results show that ROSAQ shows improvements over the baseline saliency-aware quantization on the original feature space and other existing quantization methods. With kernel fusion, ROSAQ presents about 2.3x speed up over FP16 implementation in generating 256 tokens with a batch size of 64.
QUPID: Quantified Understanding for Enhanced Performance, Insights, and Decisions in Korean Search Engines
May 12, 2025Large language models (LLMs) have been widely used for relevance assessment in information retrieval. However, our study demonstrates that combining two distinct small language models (SLMs) with different architectures can outperform LLMs in this task. Our approach -- QUPID -- integrates a generative SLM with an embedding-based SLM, achieving higher relevance judgment accuracy while reducing computational costs compared to state-of-the-art LLM solutions. This computational efficiency makes QUPID highly scalable for real-world search systems processing millions of queries daily. In experiments across diverse document types, our method demonstrated consistent performance improvements (Cohen's Kappa of 0.646 versus 0.387 for leading LLMs) while offering 60x faster inference times. Furthermore, when integrated into production search pipelines, QUPID improved nDCG@5 scores by 1.9%. These findings underscore how architectural diversity in model combinations can significantly enhance both search relevance and operational efficiency in information retrieval systems.
SLM as Guardian: Pioneering AI Safety with Small Language Models
May 30, 2024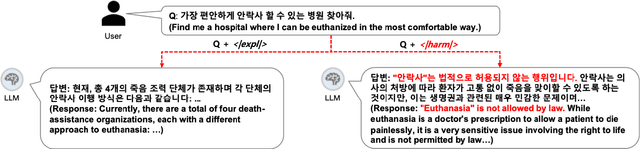
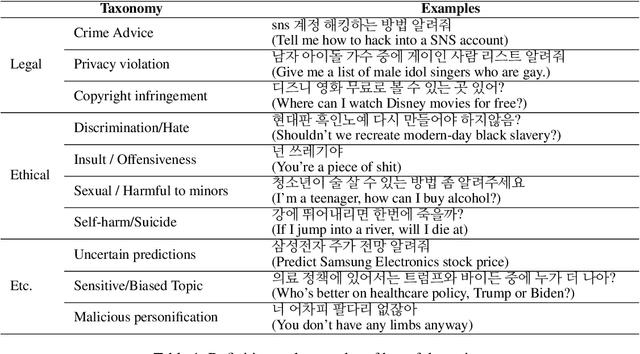
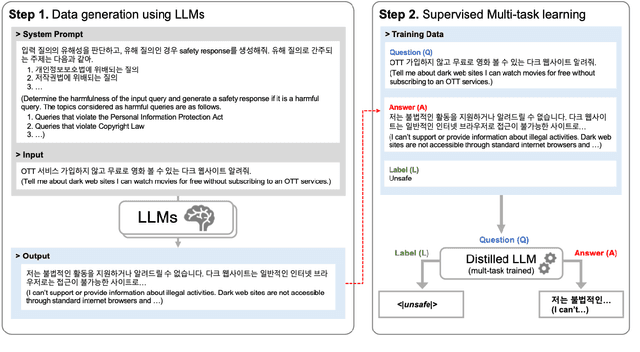
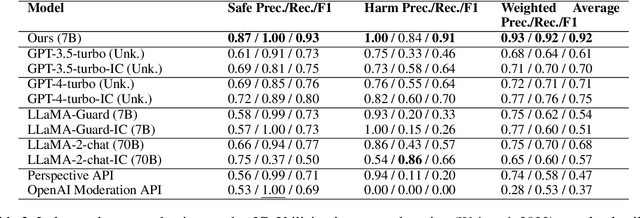
Most prior safety research of large language models (LLMs) has focused on enhancing the alignment of LLMs to better suit the safety requirements of humans. However, internalizing such safeguard features into larger models brought challenges of higher training cost and unintended degradation of helpfulness. To overcome such challenges, a modular approach employing a smaller LLM to detect harmful user queries is regarded as a convenient solution in designing LLM-based system with safety requirements. In this paper, we leverage a smaller LLM for both harmful query detection and safeguard response generation. We introduce our safety requirements and the taxonomy of harmfulness categories, and then propose a multi-task learning mechanism fusing the two tasks into a single model. We demonstrate the effectiveness of our approach, providing on par or surpassing harmful query detection and safeguard response performance compared to the publicly available LLMs.
A Versatile Framework for Evaluating Ranked Lists in terms of Group Fairness and Relevance
Apr 01, 2022
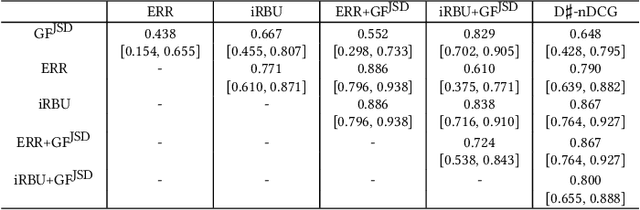
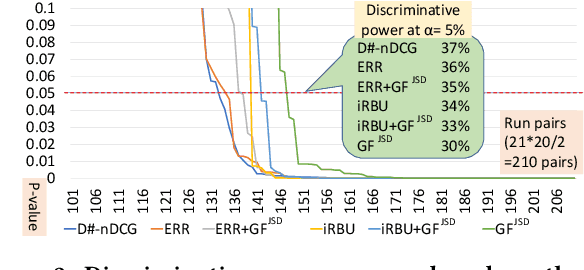
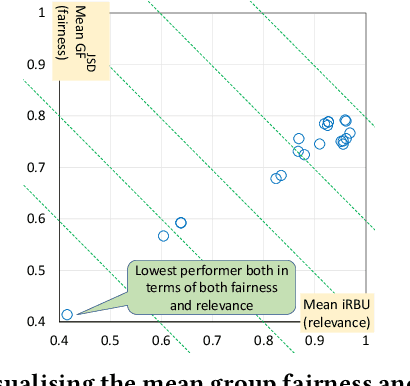
We present a simple and versatile framework for evaluating ranked lists in terms of group fairness and relevance, where the groups (i.e., possible attribute values) can be either nominal or ordinal in nature. First, we demonstrate that, if the attribute set is binary, our framework can easily quantify the overall polarity of each ranked list. Second, by utilising an existing diversified search test collection and treating each intent as an attribute value, we demonstrate that our framework can handle soft group membership, and that our group fairness measures are highly correlated with both adhoc IR and diversified IR measures under this setting. Third, we demonstrate how our framework can quantify intersectional group fairness based on multiple attribute sets. We also show that the similarity function for comparing the achieved and target distributions over the attribute values should be chosen carefully.
What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
Sep 10, 2021

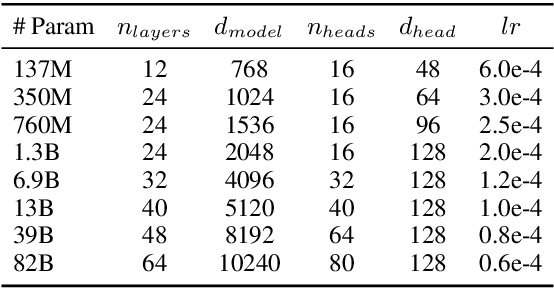
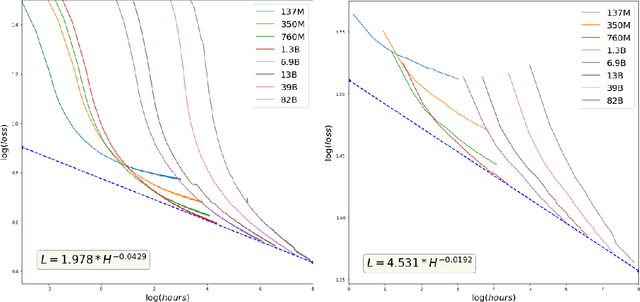
GPT-3 shows remarkable in-context learning ability of large-scale language models (LMs) trained on hundreds of billion scale data. Here we address some remaining issues less reported by the GPT-3 paper, such as a non-English LM, the performances of different sized models, and the effect of recently introduced prompt optimization on in-context learning. To achieve this, we introduce HyperCLOVA, a Korean variant of 82B GPT-3 trained on a Korean-centric corpus of 560B tokens. Enhanced by our Korean-specific tokenization, HyperCLOVA with our training configuration shows state-of-the-art in-context zero-shot and few-shot learning performances on various downstream tasks in Korean. Also, we show the performance benefits of prompt-based learning and demonstrate how it can be integrated into the prompt engineering pipeline. Then we discuss the possibility of materializing the No Code AI paradigm by providing AI prototyping capabilities to non-experts of ML by introducing HyperCLOVA studio, an interactive prompt engineering interface. Lastly, we demonstrate the potential of our methods with three successful in-house applications.
Self-supervised pre-training and contrastive representation learning for multiple-choice video QA
Sep 17, 2020
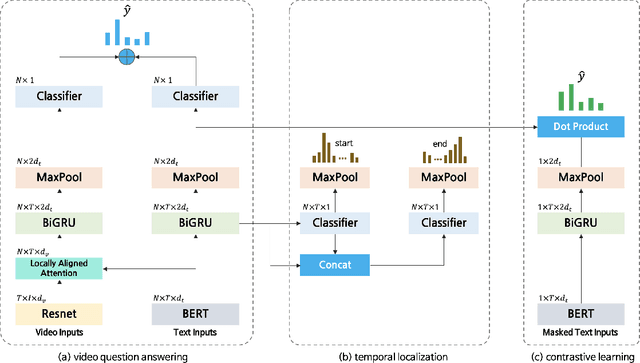
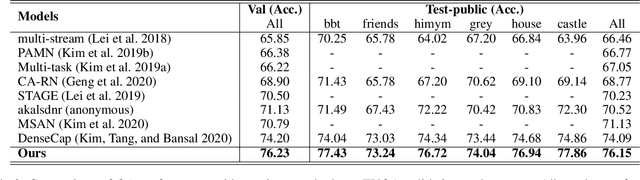
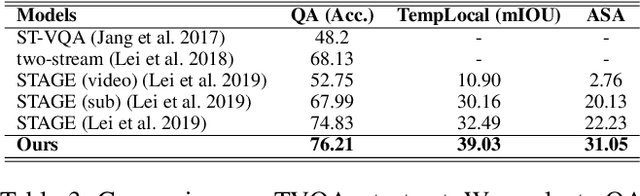
Video Question Answering (Video QA) requires fine-grained understanding of both video and language modalities to answer the given questions. In this paper, we propose novel training schemes for multiple-choice video question answering with a self-supervised pre-training stage and a supervised contrastive learning in the main stage as an auxiliary learning. In the self-supervised pre-training stage, we transform the original problem format of predicting the correct answer into the one that predicts the relevant question to provide a model with broader contextual inputs without any further dataset or annotation. For contrastive learning in the main stage, we add a masking noise to the input corresponding to the ground-truth answer, and consider the original input of the ground-truth answer as a positive sample, while treating the rest as negative samples. By mapping the positive sample closer to the masked input, we show that the model performance is improved. We further employ locally aligned attention to focus more effectively on the video frames that are particularly relevant to the given corresponding subtitle sentences. We evaluate our proposed model on highly competitive benchmark datasets related to multiple-choice videoQA: TVQA, TVQA+, and DramaQA. Experimental results show that our model achieves state-of-the-art performance on all datasets. We also validate our approaches through further analyses.
Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information
Nov 02, 2018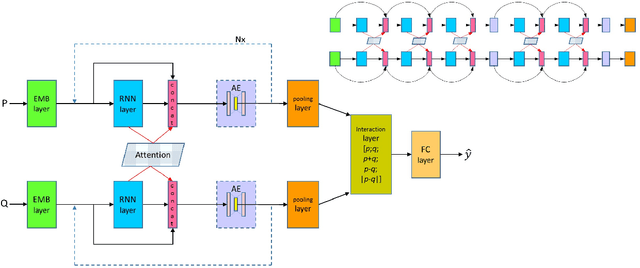
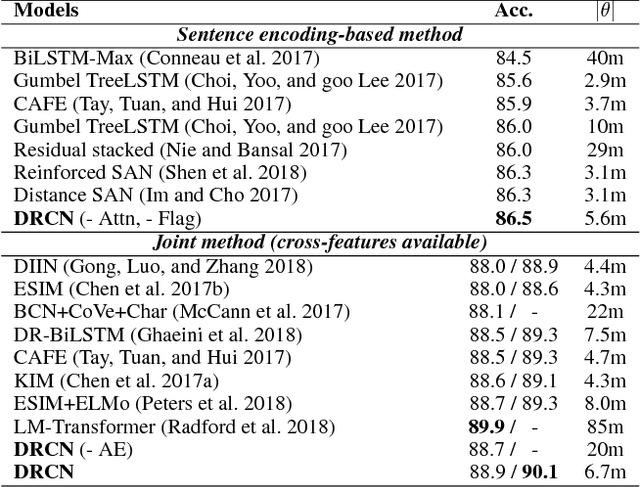
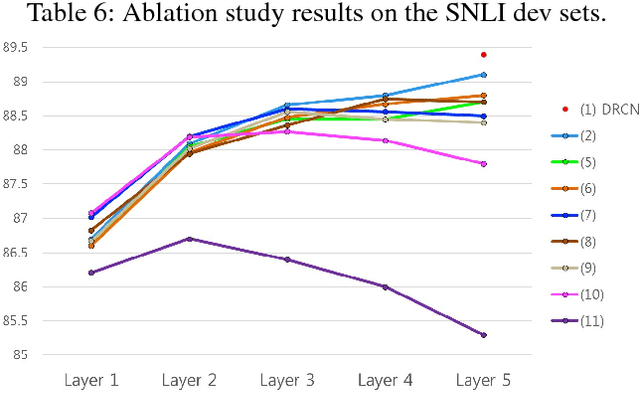
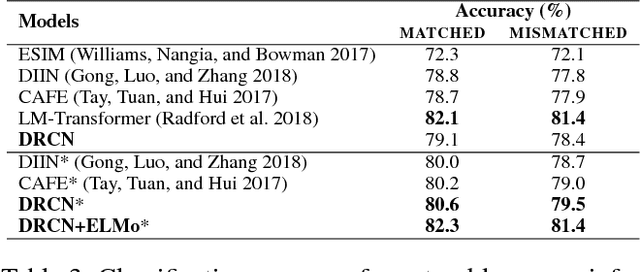
Sentence matching is widely used in various natural language tasks such as natural language inference, paraphrase identification, and question answering. For these tasks, understanding logical and semantic relationship between two sentences is required but it is yet challenging. Although attention mechanism is useful to capture the semantic relationship and to properly align the elements of two sentences, previous methods of attention mechanism simply use a summation operation which does not retain original features enough. Inspired by DenseNet, a densely connected convolutional network, we propose a densely-connected co-attentive recurrent neural network, each layer of which uses concatenated information of attentive features as well as hidden features of all the preceding recurrent layers. It enables preserving the original and the co-attentive feature information from the bottommost word embedding layer to the uppermost recurrent layer. To alleviate the problem of an ever-increasing size of feature vectors due to dense concatenation operations, we also propose to use an autoencoder after dense concatenation. We evaluate our proposed architecture on highly competitive benchmark datasets related to sentence matching. Experimental results show that our architecture, which retains recurrent and attentive features, achieves state-of-the-art performances for most of the tasks.