 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERLIN: Multimodal Embedding Refinement via LLM-based Iterative Navigation for Text-Video Retrieval-Rerank Pipeline
Jul 17, 2024



The rapid expansion of multimedia content has made accurately retrieving relevant videos from large collections increasingly challenging. Recent advancements in text-video retrieval have focused on cross-modal interactions, large-scale foundation model training, and probabilistic modeling, yet often neglect the crucial user perspective, leading to discrepancies between user queries and the content retrieved. To address this, we introduce MERLIN (Multimodal Embedding Refinement via LLM-based Iterative Navigation), a novel, training-free pipeline that leverages Large Language Models (LLMs) for iterative feedback learning. MERLIN refines query embeddings from a user perspective, enhancing alignment between queries and video content through a dynamic question answering process. Experimental results on datasets like MSR-VTT, MSVD, and ActivityNet demonstrate that MERLIN substantially improves Recall@1, outperforming existing systems and confirming the benefits of integrating LLMs into multimodal retrieval systems for more responsive and context-aware multimedia retrieval.
Unleash the Potential of CLIP for Video Highlight Detection
Apr 02, 2024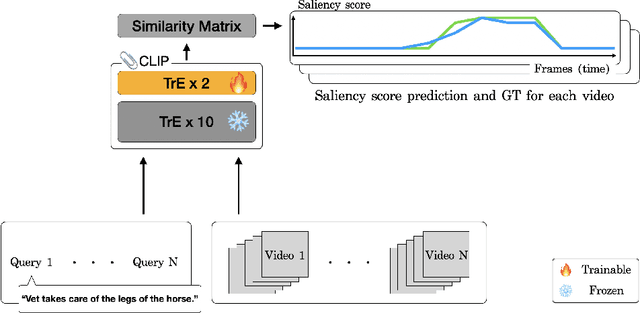
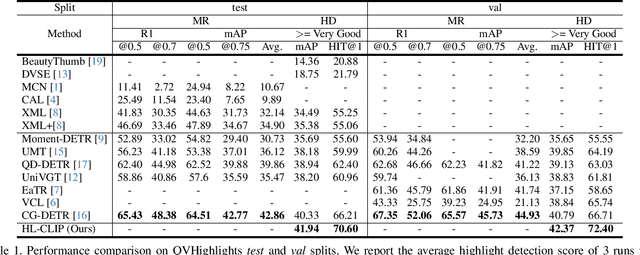
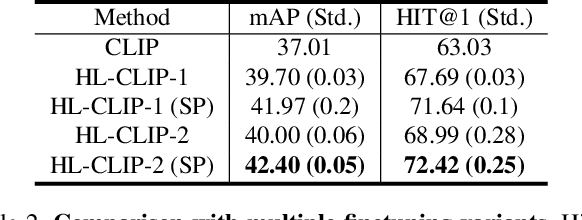
Multimodal and large language models (LLMs) have revolutionized the utilization of open-world knowledge, unlocking novel potentials across various tasks and applications. Among these domains, the video domain has notably benefited from their capabilities. In this paper, we present Highlight-CLIP (HL-CLIP), a method designed to excel in the video highlight detection task by leveraging the pre-trained knowledge embedded in multimodal models. By simply fine-tuning the multimodal encoder in combination with our innovative saliency pooling technique, we have achieved the state-of-the-art performance in the highlight detection task, the QVHighlight Benchmark, to the best of our knowledge.
ConcatPlexer: Additional Dim1 Batching for Faster ViTs
Aug 22, 2023Transformers have demonstrated tremendous success not only in the natural language processing (NLP) domain but also the field of computer vision, igniting various creative approaches and applications. Yet, the superior performance and modeling flexibility of transformers came with a severe increase in computation costs, and hence several works have proposed methods to reduce this burden. Inspired by a cost-cutting method originally proposed for language models, Data Multiplexing (DataMUX), we propose a novel approach for efficient visual recognition that employs additional dim1 batching (i.e., concatenation) that greatly improves the throughput with little compromise in the accuracy. We first introduce a naive adaptation of DataMux for vision models, Image Multiplexer, and devise novel components to overcome its weaknesses, rendering our final model, ConcatPlexer, at the sweet spot between inference speed and accuracy. The ConcatPlexer was trained on ImageNet1K and CIFAR100 dataset and it achieved 23.5% less GFLOPs than ViT-B/16 with 69.5% and 83.4% validation accuracy, respectively.
MixNeRF: Modeling a Ray with Mixture Density for Novel View Synthesis from Sparse Inputs
Feb 17, 2023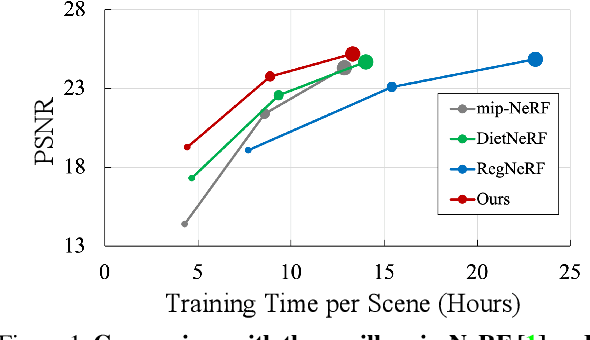
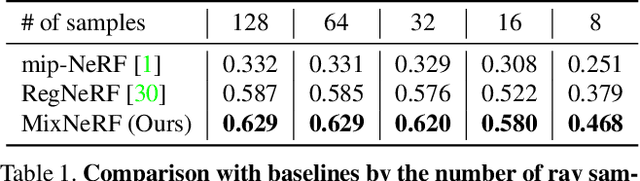
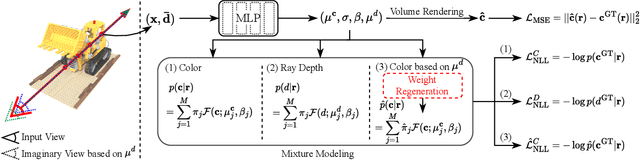
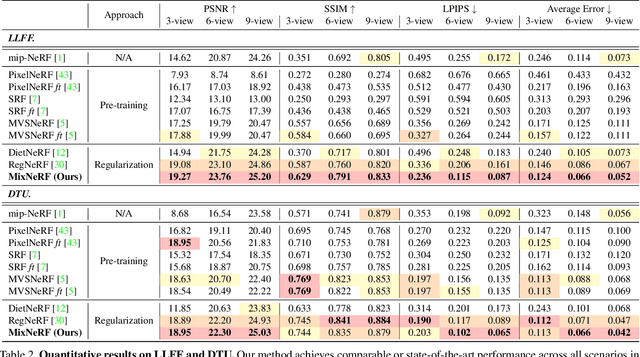
Neural Radiance Field (NeRF) has broken new ground in the novel view synthesis due to its simple concept and state-of-the-art quality. However, it suffers from severe performance degradation unless trained with a dense set of images with different camera poses, which hinders its practical applications. Although previous methods addressing this problem achieved promising results, they relied heavily on the additional training resources, which goes against the philosophy of sparse-input novel-view synthesis pursuing the training efficiency. In this work, we propose MixNeRF, an effective training strategy for novel view synthesis from sparse inputs by modeling a ray with a mixture density model. Our MixNeRF estimates the joint distribution of RGB colors along the ray samples by modeling it with mixture of distributions. We also propose a new task of ray depth estimation as a useful training objective, which is highly correlated with 3D scene geometry. Moreover, we remodel the colors with regenerated blending weights based on the estimated ray depth and further improves the robustness for colors and viewpoints. Our MixNeRF outperforms other state-of-the-art methods in various standard benchmarks with superior efficiency of training and inference.
Smoothing the Generative Latent Space with Mixup-based Distance Learning
Nov 23, 2021

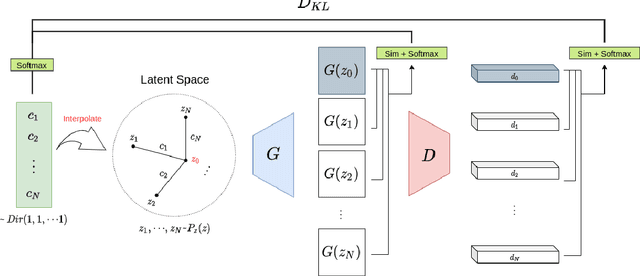

Producing diverse and realistic images with generative models such as GANs typically requires large scale training with vast amount of images. GANs trained with extremely limited data can easily overfit to few training samples and display undesirable properties like "stairlike" latent space where transitions in latent space suffer from discontinuity, occasionally yielding abrupt changes in outputs. In this work, we consider the situation where neither large scale dataset of our interest nor transferable source dataset is available, and seek to train existing generative models with minimal overfitting and mode collapse. We propose latent mixup-based distance regularization on the feature space of both a generator and the counterpart discriminator that encourages the two players to reason not only about the scarce observed data points but the relative distances in the feature space they reside. Qualitative and quantitative evaluation on diverse datasets demonstrates that our method is generally applicable to existing models to enhance both fidelity and diversity under the constraint of limited data. Code will be made public.
The U-Net based GLOW for Optical-Flow-free Video Interframe Generation
Apr 06, 2021
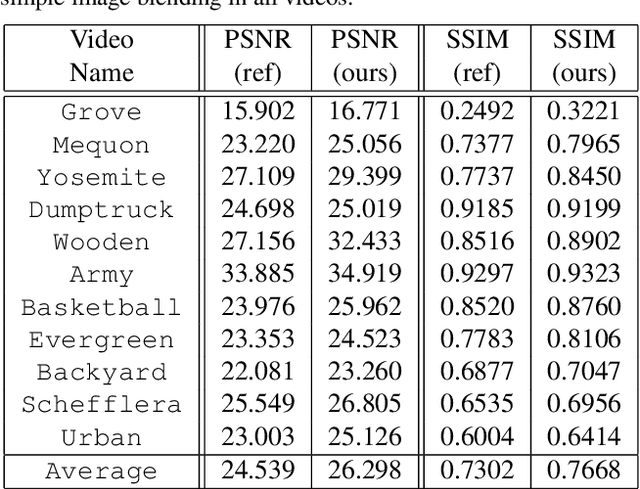
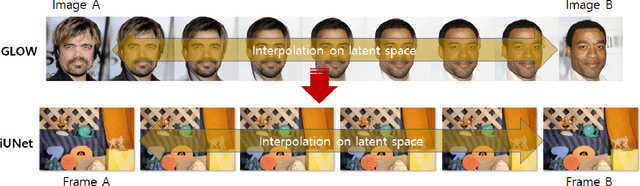
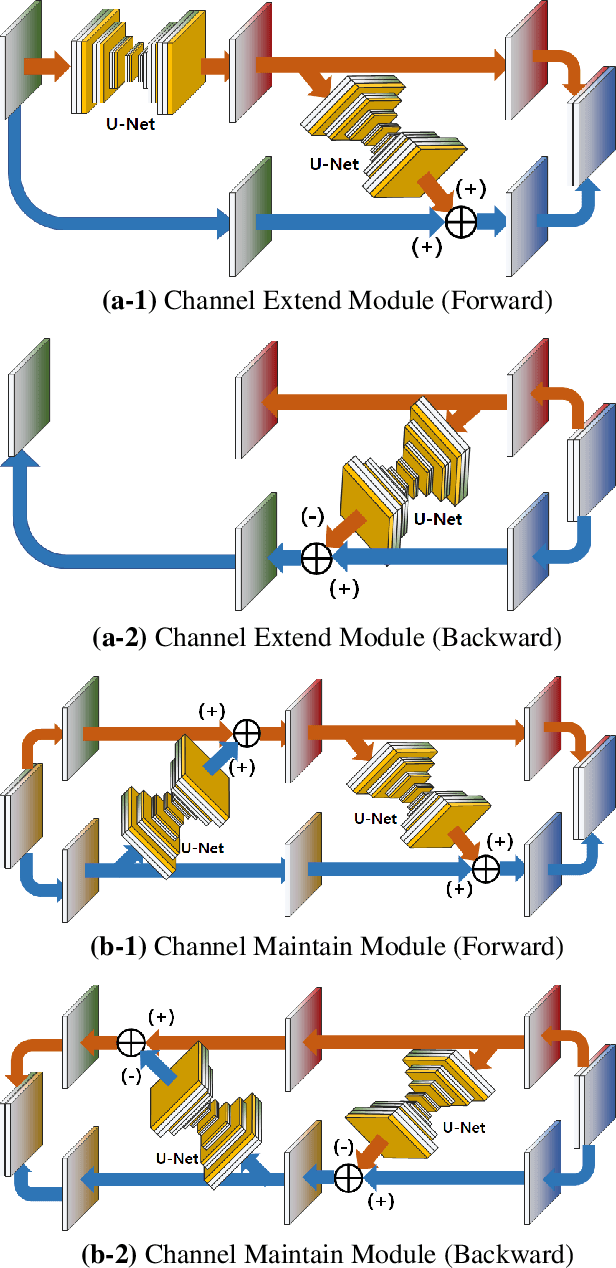
Video frame interpolation is the task of creating an interframe between two adjacent frames along the time axis. So, instead of simply averaging two adjacent frames to create an intermediate image, this operation should maintain semantic continuity with the adjacent frames. Most conventional methods use optical flow, and various tools such as occlusion handling and object smoothing are indispensable. Since the use of these various tools leads to complex problems, we tried to tackle the video interframe generation problem without using problematic optical flow . To enable this , we have tried to use a deep neural network with an invertible structure, and developed an U-Net based Generative Flow which is a modified normalizing flow. In addition, we propose a learning method with a new consistency loss in the latent space to maintain semantic temporal consistency between frames. The resolution of the generated image is guaranteed to be identical to that of the original images by using an invertible network. Furthermore, as it is not a random image like the ones by generative models, our network guarantees stable outputs without flicker. Through experiments, we \sam {confirmed the feasibility of the proposed algorithm and would like to suggest the U-Net based Generative Flow as a new possibility for baseline in video frame interpolation. This paper is meaningful in that it is the world's first attempt to use invertible networks instead of optical flows for video interpolation.