 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotif-2-12.7B-Reasoning: A Practitioner's Guide to RL Training Recipes
Dec 11, 2025We introduce Motif-2-12.7B-Reasoning, a 12.7B parameter language model designed to bridge the gap between open-weight systems and proprietary frontier models in complex reasoning and long-context understanding. Addressing the common challenges of model collapse and training instability in reasoning adaptation, we propose a comprehensive, reproducible training recipe spanning system, data, and algorithmic optimizations. Our approach combines memory-efficient infrastructure for 64K-token contexts using hybrid parallelism and kernel-level optimizations with a two-stage Supervised Fine-Tuning (SFT) curriculum that mitigates distribution mismatch through verified, aligned synthetic data. Furthermore, we detail a robust Reinforcement Learning Fine-Tuning (RLFT) pipeline that stabilizes training via difficulty-aware data filtering and mixed-policy trajectory reuse. Empirical results demonstrate that Motif-2-12.7B-Reasoning achieves performance comparable to models with significantly larger parameter counts across mathematics, coding, and agentic benchmarks, offering the community a competitive open model and a practical blueprint for scaling reasoning capabilities under realistic compute constraints.
Motif 2 12.7B technical report
Nov 07, 2025We introduce Motif-2-12.7B, a new open-weight foundation model that pushes the efficiency frontier of large language models by combining architectural innovation with system-level optimization. Designed for scalable language understanding and robust instruction generalization under constrained compute budgets, Motif-2-12.7B builds upon Motif-2.6B with the integration of Grouped Differential Attention (GDA), which improves representational efficiency by disentangling signal and noise-control attention pathways. The model is pre-trained on 5.5 trillion tokens spanning diverse linguistic, mathematical, scientific, and programming domains using a curriculum-driven data scheduler that gradually changes the data composition ratio. The training system leverages the MuonClip optimizer alongside custom high-performance kernels, including fused PolyNorm activations and the Parallel Muon algorithm, yielding significant throughput and memory efficiency gains in large-scale distributed environments. Post-training employs a three-stage supervised fine-tuning pipeline that successively enhances general instruction adherence, compositional understanding, and linguistic precision. Motif-2-12.7B demonstrates competitive performance across diverse benchmarks, showing that thoughtful architectural scaling and optimized training design can rival the capabilities of much larger models.
Grouped Differential Attention
Oct 08, 2025The self-attention mechanism, while foundational to modern Transformer architectures, suffers from a critical inefficiency: it frequently allocates substantial attention to redundant or noisy context. Differential Attention addressed this by using subtractive attention maps for signal and noise, but its required balanced head allocation imposes rigid constraints on representational flexibility and scalability. To overcome this, we propose Grouped Differential Attention (GDA), a novel approach that introduces unbalanced head allocation between signal-preserving and noise-control groups. GDA significantly enhances signal focus by strategically assigning more heads to signal extraction and fewer to noise-control, stabilizing the latter through controlled repetition (akin to GQA). This design achieves stronger signal fidelity with minimal computational overhead. We further extend this principle to group-differentiated growth, a scalable strategy that selectively replicates only the signal-focused heads, thereby ensuring efficient capacity expansion. Through large-scale pretraining and continual training experiments, we demonstrate that moderate imbalance ratios in GDA yield substantial improvements in generalization and stability compared to symmetric baselines. Our results collectively establish that ratio-aware head allocation and selective expansion offer an effective and practical path toward designing scalable, computation-efficient Transformer architectures.
MERLIN: Multimodal Embedding Refinement via LLM-based Iterative Navigation for Text-Video Retrieval-Rerank Pipeline
Jul 17, 2024



The rapid expansion of multimedia content has made accurately retrieving relevant videos from large collections increasingly challenging. Recent advancements in text-video retrieval have focused on cross-modal interactions, large-scale foundation model training, and probabilistic modeling, yet often neglect the crucial user perspective, leading to discrepancies between user queries and the content retrieved. To address this, we introduce MERLIN (Multimodal Embedding Refinement via LLM-based Iterative Navigation), a novel, training-free pipeline that leverages Large Language Models (LLMs) for iterative feedback learning. MERLIN refines query embeddings from a user perspective, enhancing alignment between queries and video content through a dynamic question answering process. Experimental results on datasets like MSR-VTT, MSVD, and ActivityNet demonstrate that MERLIN substantially improves Recall@1, outperforming existing systems and confirming the benefits of integrating LLMs into multimodal retrieval systems for more responsive and context-aware multimedia retrieval.
Unleash the Potential of CLIP for Video Highlight Detection
Apr 02, 2024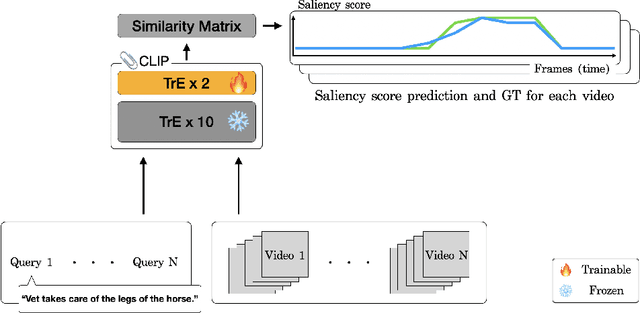
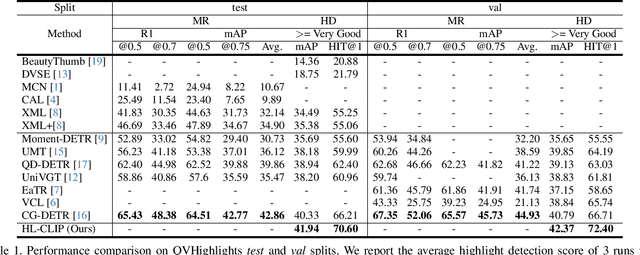
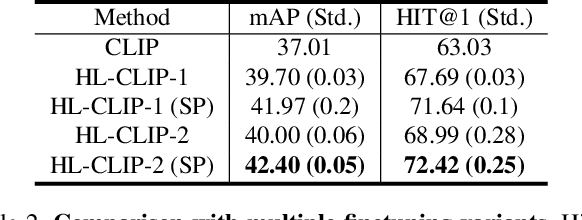
Multimodal and large language models (LLMs) have revolutionized the utilization of open-world knowledge, unlocking novel potentials across various tasks and applications. Among these domains, the video domain has notably benefited from their capabilities. In this paper, we present Highlight-CLIP (HL-CLIP), a method designed to excel in the video highlight detection task by leveraging the pre-trained knowledge embedded in multimodal models. By simply fine-tuning the multimodal encoder in combination with our innovative saliency pooling technique, we have achieved the state-of-the-art performance in the highlight detection task, the QVHighlight Benchmark, to the best of our knowledge.